上篇文章《天书般的ICTCLAS分词系统代码(一)》 说了说ICTCLAS分词系统有些代码让人无所适从,需要好一番努力才能弄明白究竟是怎么回事。尽管有很多人支持应当写简单、清晰的代码,但也有人持不同意见。主要集中在(1)如果效率高,代码复杂点也行; (2)只要注释写得好就行;(3)软件关键在思路(这我同意),就好像买了一台电脑,不管包装箱内的电脑本身怎么,一群人偏在死扣那个外面透明胶带帖歪了(这我坚决不同意,因为只有好思路出不来好电脑,好电脑还要性能稳定,即插即用的好硬件;另外天书般的代码不仅仅是透明胶带 贴歪的问题,他甚至可能意味着电脑中的绝缘胶带失效了...)。
这两天在抓紧学习ICTCLAS分词系统的思路的同时,也在消化学习它的代码实现,然而我看到的代码已经不仅仅是为了效率牺牲代码清晰度的问题了,我看到的是连作者都不知道自己真正想要做什么了,尽管程序的执行结果是正确的!
为了说明这种情况的严重性,我们需要从CQueue.cpp这个文件着手。我对CQueue这个类颇有些微辞,明明是个Queue,里面确用的是Push、Pop方法(让人感觉是个Stack而不是Queue),而且Pop方法纯粹是个大杂烩,不过这些都不是原则性问题,毕竟每个人有每个人写代码的习惯。CQueue完成的工作是制造一个排序队列(按照eWeight从小到大排序),如图一:

(图一)
在了解了这些内容的基础上,让我们看看ICTCLAS中NShortPath.cpp中的代码实现(这里我们只看ShortPath方法的实现) ,为了让问题暴露得更清晰一些,我简化了代码中一些不相关的内容。
{
......
for (; nCurNode < m_nVertex; nCurNode++)
{
CQueue queWork;
//此处省略的代码主要负责将一些结点按照eWeight从
//小到大的顺序放入队列queWork
......
//初始化权重
for (i = 0; i < m_nValueKind; i++)
m_pWeight[nCurNode - 1][i] = INFINITE_VALUE;
i = 0;
while (i < m_nValueKind && queWork.Pop(&nPreNode, &nIndex, &eWeight) != -1)
{
//Set the current node weight and parent
if ( m_pWeight[nCurNode - 1][i] == INFINITE_VALUE)
m_pWeight[nCurNode - 1][i] = eWeight;
else if ( m_pWeight[nCurNode - 1][i] < eWeight)
//Next queue
{
i++; //Go next queue and record next weight
if (i == m_nValueKind)
//Get the last position
break;
m_pWeight[nCurNode - 1][i] = eWeight;
}
m_pParent[nCurNode - 1][i].Push(nPreNode, nIndex);
}
}
......
}
上面的代码作者想干什么?让我们来分析一番:
变量queWork中存放的是一个按照eWeight从小到大排列的队列, 我们不妨假设里面有4个元素,其eWeight值分别是5、6、7、8。另外我们假设变量m_nValueKind的值为2,即查找最短的两条路径(注意:这种说法不完全正确,后面会解释为什么)。在此假设基础上,我们看看程序是如何运行的:
1)将所有m_pWeight[nCurNode - 1][i]初始化为INFINITE_VALUE。
2)在第一轮循环中,我们从queWork中取出第一个元素,其eWeight为5,注意表达式“if (m_pWeight[nCurNode - 1][i] == INFINITE_VALUE) ”没有任何作用,因为我们在第一步将所有m_pWeight[nCurNode - 1][i] 均初始化成了INFINITE_VALUE,所以第一轮循环该条件一定为true。
3)在第二轮循环中,我们从queWork中取出第二个元素,其eWeight为6,此时表达式“else if (m_pWeight[nCurNode - 1][i] < eWeight) ”似乎就没有什么作用了,因为queWork是经过排序的,第二个元素的eWeight不会小于第一个eWeight,对于我们这个例子来说, 该表达式一定为true,于是就让 i++。
4)紧接着你会发现程序重新进入了步骤2)的循环。
程序执行结果如图二:
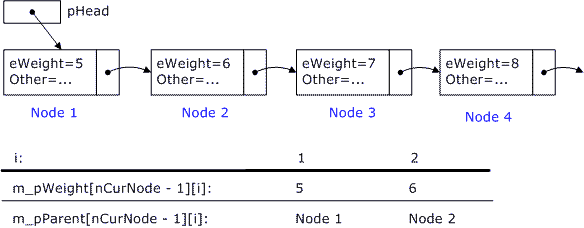
(图二)
如果真是这样的话,上面的代码似乎可以简化成:
{
......
for (; nCurNode < m_nVertex; nCurNode++)
{
CQueue queWork;
//此处省略的代码主要负责将一些结点按照eWeight从
//小到大的顺序放入队列queWork
......
//初始化权重
for (i = 0; i < m_nValueKind; i++)
m_pWeight[nCurNode - 1][i] = INFINITE_VALUE;
i = 0;
while (i < m_nValueKind && queWork.Pop(&nPreNode, &nIndex, &eWeight) != -1)
{
m_pWeight[nCurNode - 1][i] = eWeight;
m_pParent[nCurNode - 1][i].Push(nPreNode, nIndex);
i++;
}
}
......
}
对于上面这个案例,简化后的程序与ICTCLAS中的程序执行结果完全相同。可作者写出如此复杂的代码应当是有理由的,难道我们对代码的分析有什么问题吗?
是的!作者将一个最为重要的内容作为隐含条件放入了代码之中,我们只能通过 if 条件以及 else if 条件中的内容推断出这个隐含条件究竟是什么,而这个隐含的条件恰恰应当是这段代码中最关键的内容。如果没能将最关键的内容展现在代码当中,而是需要读者去推断的话,我只能说连作者自己都不清楚究竟什么是最关键的东西,仅仅是让程序执行没有错误而已。
那么究竟隐藏了什么关键的内容呢?那就是“m_pWeight[nCurNode - 1][i] = eWeight”这个条件。在ShortPath方法代码中,作者用了 if 条件、 else if 条件,但都没有提及等于eWeight时程序的执行行为,他将这个留给了读者去推敲,看出来这个隐含条件就看出来了,看不出来就只能怪你自己笨了。
我们更换一组数据来看看:假设queWork里面有4个元素,其eWeight值分别是5、6、6、7,还假设变量m_nValueKind的值为2,那么ICTCLAS中ShortPath程序执行结果是什么呢?读者可以根据代码自己推敲一下,然后再看看下面的结果,与你预期的一样不一样。如图三。

(图三)
这里m_Parent[nCurNode - 1][2]是一个CQueue,里面存入了eWeight为6的两个结点。这也是为什么我前文说,NShortPath中 N 如果取2,并不意味着只有两条路径。
如果那位有耐心看到这里,对ICTCLAS中的NShortPath.cpp代码有什么感觉呢?其实要想写出一个比较清晰的代码并不复杂,只要你真正了解究竟什么是最重要的东西,对于NShortPath.cpp中的代码,只要我们稍加修改,就可以让这天书般的代码改善不少。经过调整后的代码如下:
{
......
for (; nCurNode < m_nVertex; nCurNode++)
{
CQueue queWork;
//此处省略的代码主要负责将一些结点按照eWeight从
//小到大的顺序放入队列queWork
......
//初始化权重
for (i = 0; i < m_nValueKind; i++)
m_pWeight[nCurNode - 1][i] = INFINITE_VALUE;
if(queWork.Pop(&nPreNode, &nIndex, &eWeight) != -1)
{
for(i=0; i < m_nValueKind ; i++)
{
m_pWeight[nCurNode - 1][i] = eWeight;
do
{
m_pParent[nCurNode - 1][i].Push(nPreNode, nIndex);
if(queWork.Pop(&nPreNode, &nIndex, &new_eWeight) == -1)
goto finish;
}while(new_eWeight == eWeight)
eWeight = new_eWeight;
}
}
}
finish:
......
}
经过改造的代码使用了一个do...while循环,并利用了goto命令简化代码结构,我想这样的代码读起来应当清晰多了吧。
- 小结
(1)软件关键在思路,只有真正了解思路的人才能写出清晰的代码。如果代码不清晰,说明思路根本不清晰。
(2)注释写得好不如代码结构清晰。
(3)除非经过测试,否则不要为了一点效率提升而损失代码的可读性。
来源:http://www.cnblogs.com/zhenyulu/category/85598.html