matlab实现感知器学习算法
感知器(Perceptron)
1958年,美国学者F.Rosenblatt提出了适于简单模式分类的感知器学习算法。
1、模型介绍
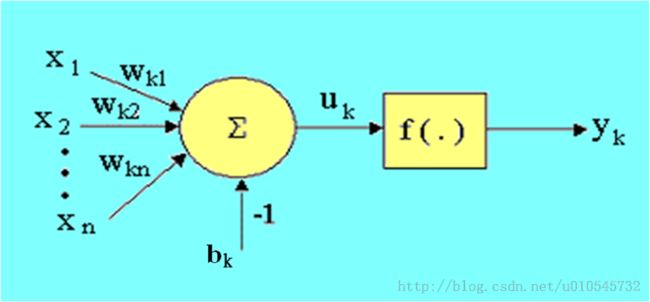
其中x1,x2,...,xn表示外界对于第k个神经元的刺激,在具体的科学实践中表示信号或图像的像素点值。wk1,wk2,...wkn分别表示n个输入对神经元刺激的强度,对各个刺激进行加权求和并加上一个负的偏置量,就形成了第k个神经元所接受的信息uk,作用在函数f上以后就得到了实际输出yk.因为感知器学习算法是一个有导师学习算法,因此输入值必对应着一个期望输出。
2、算法流程
将感知器学习算法应用到二分类问题时,它的训练过程是这样的:
1) 给出m个带有标签的样本{(x1,y1),(x2,y2),...(xm,ym)},其中yi= -1 or 1 (i=1,2,...m) 是样本xi = (xi1,xi2,...,xin)的标签;
2) 将数据的标签并入训练样本,形成增广向量,每个数据的维数为n+1;
3)在(0,1)均匀分布区间内生成1x(n+1)权值矩阵W;
4) 将数据依次送入感知器进行学习
如果W*[data(k,:) yk] <=0 ,说明训练错误,则对权值进行惩罚,W = W + c*[data(k,:) yk];
否则对权值进行奖励即不惩罚,W = W;
5) 对所有数据训练完成后,如果至少有一个数据训练错误,则要对权值进行重新训练,直到对所有数据训练正确,即可退出训练过程。
3、实验
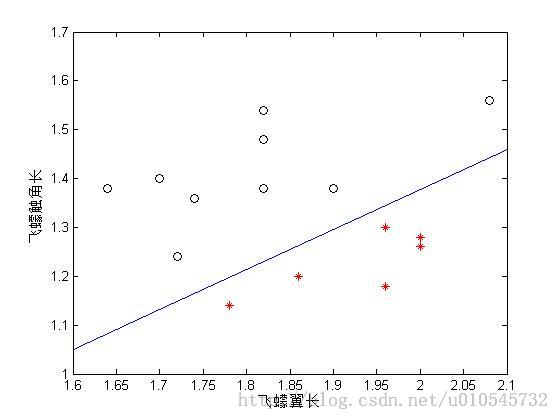
下面是一组数据:
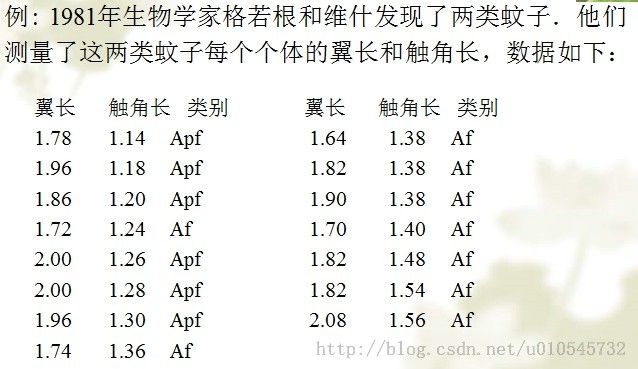
利用这一批数据,对感知器进行了训练