Hadoop:Hadoop的分布式(伪分布式)部署安装
今天总结一下hadoop的分布式部署安装,由于寡人资源实在是有限,在学习的时候,是在一台机器上模拟多台服务器进行部署的,后面我们在写集群。
原创文章,转载请注明出处:http://blog.csdn.net/jessonlv/article/details/18270041
1、安装前的准备
在安装软件之前,我们的linux系统具体要进行一下操作,不然,hadoop安装不成功!
1、关闭防火墙,
RedHat 内置一个文本行的管理工具,可以管理防火墙、ip 地址、各类服务等信息的设置。使用setup 命令调出该工具。很简单,我就不赘述了。。
2、修改IP地址
将虚拟机的ip地址和宿主机的ip地址设置在一个网段,互相ping通。命令也很简单,不赘述。
3、修改hostname为hadoop
命令“hostname 新主机名”,意味着修改主机名,但只对本次会话有效,重启机器后失效。我们要想永久改主机名,需要修改配置文:/etc/sysconfig/network我们这里将主机名改为:hadoop
4、设置ssh自动登录。
设置ssh自动登录。
如果我们需要远程管理其他机器的话,一般使用远程桌面或者telnet。linxu 服务器几乎都是命令行,所以只能使用telnet 了。telnet 的缺点是通信不加密,非常不安全,只适合于
内网访问。为解决这个问题,推出了加密的通信协议,即SSH。SSH 的全称是Secure Shell,使用非对称加密方式,传输内容使用rsa 或者dsa 加密,可以有效避免网络窃听。
hadoop 的进程之间通信使用ssh 方式,需要每次都要输入密码。为了实现自动化操作,我们下面配置SSH 的免密码登录方式.
首先到用户主目录下:

在“ls -a”命令显示的文件中,最后一列中间一项是“.ssh”,该文件夹是存放密钥的。注意该文件夹是以“.”开头的,是隐藏文件。待会我们生成的密钥都会放到这个文件夹中。
现在执行命令,生成密钥

解释一下:
命令“ssh-keygen -t rsa”表示使用rsa 加密方式生成密钥, 回车后,会提示三次输入信息,我们直接回车即可。
然后进入密钥文件夹,执行命令,
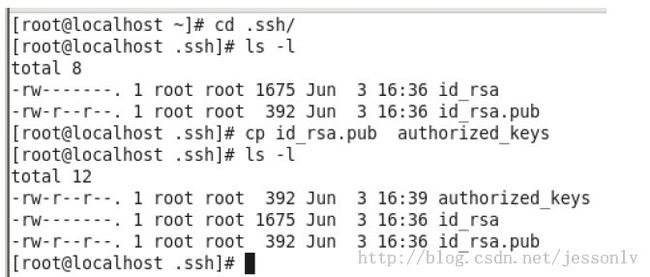
其中,命令“cp id_rsa.pub authorized_keys”用于生成授权文件。至此,配置部分完成了。这里为什么要使用ssh 登录本机哪?因为hadoop 在本机部署时,需要使用ssh 访问。
注意:文件夹“.ssh”中的三个文件的权限,是有要求的,“自己之外的任何人对每个文件都没有写权限”。另外,“.ssh”文件夹是700 权限。如果权限有问题,会造成SSH 访问
失败。
现在开始验证SSH 无密码登录

执行“ssh localhost”意味着使用“ssh”通信协议访问主机“localhost”,第一次执行时需要确认;第二次不再确认了。这就是无密码登录。当登录到对方机器后,退出使用命令
“exit”。这两次操作时,注意观察主机名变化。读者可以执行命令“ssh book0”,验证dns对book0 解析是否正确。
注意:使用命令ssh 时,一定要观察主机名的变化。很多同学在操作ssh 时,由于大量的使用ssh 登录退出,忘记自己目前在哪台机器了,执行了大量错误的操作。
另外,如果多次执行ssh,每次都要输入确认信息的话,说明配置失败了。可以删除文件夹“.ssh”,重新配置。也可以重启虚拟机再配置。只要严格按照上面的步骤操作,保证
能够成功的。
如果还搞不定,给你个绝招” 删除/etc/udev/rules.d/70-persistent-net.rules 文件,重启
系统”。
配置出错,可以查看/var/log/secure 日志文件,找原因。
以上四项完成以后下面我安装jdk和hadoop
2、安装jdk和hadoop
(1)jdk-6u24-linux-xxx.bin
(2)hadoop-1.1.2.tar.gz
将这个两个文件放在/usr/local 下,分别解压,并将解压后的文件分别命名为: hadoop 和 jdk
1、首先配置jdk
我们知道,jdk的配置在/etc/profile里。hadoop的配置道理和jdk是一样的,看图中红线圈中的部分。

当然,编辑完配置文件后,还要执行
source /etc/profile验证执行 java -version 等命令。
3、修改hadoop的四个配置文件
这四个配置文件分别为:
1、hadoop-env.sh
用vi编辑器打开,将下面的配置复制进去就行了:
export JAVA_HOME=/usr/local/jdk/注意你的路径。
2、core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
<description>change your own hostname</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>我在上面加了描述,只要和你的主机名相对应就行,这里我的主机名字数hadoop
3、hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
这个不需要改,直接复制上去就行。
4、mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9001</value>
<description>change your own hostname</description>
</property>
</configuration>这个还是需要修改你的主机名,端口号不用改。
至此,四个文件都修改完毕,大功将要告成,哈哈。
4、格式化hadoop的namenode
hadoop namenode -format
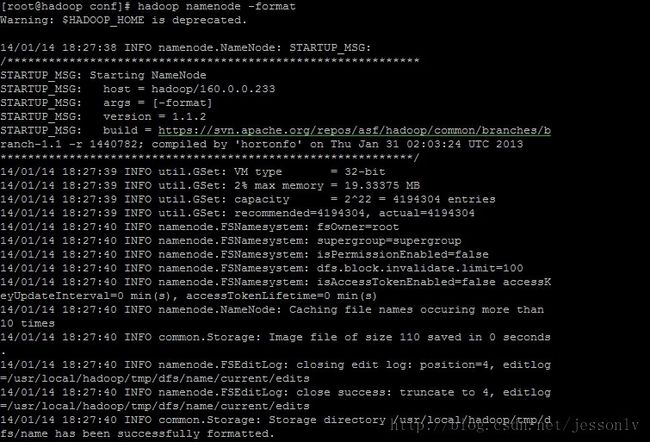
如果出现上面的日志信息,那说明咱们的hadoop安装已经大功告成了。下面,我们看看劳动成果。
5、启动hadoop
启动命令:
./start-all.sh在local/hadoop/bin 目录下。

然后用jps命令查看下都启动了什么进程,我们发现hadoop的运行,一下子蹦出了五个进程,看名思意。
6、验证hadoop
启动成功后,我们在浏览器下验证:

另外一个端口号再来一张:
至此,我们的安装就全部完成了,后面我会总结下集群的安装、设置。