如何构建高性能web站点之:分布式缓存
一、数据库前段的缓冲区
要明白数据库前段的缓冲区,首先要明白什么是文件系统内核缓冲区(Buffer Area):它位于物理内存的内核地址空间,除了使用O_DIRECT标记打开的文件以外,所有对磁盘的读写操作,都需要经过它,所以,可以把它看作磁盘的前段设备。
这块内核缓冲区也称为:页高速缓存(Page Cache),实际上它包括两部分:
1、读缓存区
2、写缓存区
读缓存区
读缓冲区保存着系统最近从磁盘上读取的数据,一旦下次需要这些数据,那么内核将直接在读缓存区中获得,而不需要再次读取磁盘。
写缓存区
写缓存区的主要作用是减少对磁盘的物理写操作,通常情况下,向磁盘的写操作并不着急,程序的运行并不会因为磁盘的写操作而等待,内核缓冲区可以将多个写操作指令累积起来,通过一次磁盘的磁头移动来完成,当然,写缓存区会导致数据的实际写入延长几秒,在实际写入之前,这些数据被称为Dirty Page ,脏页。
实际上,从职能上来看,将写缓存区叫做缓冲区更加形象,缓冲区的例子在生活中随处可见,例如城市的十字路口,它就像一个写缓冲区,红灯亮起的时候,车辆都停在缓冲区,当绿灯时,车辆依次前进,就像内核中的数据积累到一定程度时被写入磁盘。同样,我们可以在数据库和动态内容之间建立一层缓存区,它可以独立部署在服务器上,用于加速数据库的读写操作,这个缓存区实际上是由动态内容来控制的。这个时候就使用到了memcached。
二、使用memcached
key-value
首先为了实现高速缓存,我们不会将缓存内容放在磁盘上,基于这个原则,memcached使用物理内存来作为缓存区,当我们启动memcached的时候,需要指定分配给缓存区的内存大小,比如分配4Gs-colin:~ # memcached -d -m 4086 -l 10.0.1.12 -p 11711
memcached 使用key-value 的方式来存储数据,每个数据之间相互独立,每个数据都已key作为唯一的索引。
数据项过期时间
由于缓存区是有大小限制的,一旦缓存区没有足够的空间存储新的数据项的时候,memcached便会想办法淘汰一些数据项来腾出空间,淘汰机制基于LRU(Least Recently Used)算法,将最近不常访问的数据项淘汰掉。一般都是为其设置过期时间,过期时间的取值,需要根据自己站点来平衡把握。
网络并发模型
作为分布式系统,memcached可以独立运行在服务器上,动态内容通过 TCP Socket 来访问它,这样一来,memcached 本身的网络并发处理能力尤为重要。memcached 使用libevent 函数库来实现网络并发模型,其中包括epoll,所以在较大并发用户数的情况下,我们仍然可以放心使用memcached。
对象的序列化
我们可以在memcached上存储什么样的数据呢?这需要考虑到网络传输,意思就是,我们可以在网络传输中传输什么样的内容?哈哈,自然是二进制了,那么,对于数组或者对象这样的抽象数据类型而言,是否可以存储在memcached中呢?
基于序列化机制,没有可以将更好层次的抽象数据类型转化为二进制字符串,以便通过网络进入缓存服务器,同时,在读取这些数据的时候,二进制字符串又可以转换回原来的数据类型。
基于序列化机制,没有可以将更好层次的抽象数据类型转化为二进制字符串,以便通过网络进入缓存服务器,同时,在读取这些数据的时候,二进制字符串又可以转换回原来的数据类型。
有点需要注意的是,我们在试图将一个类的对象进行序列化时,对象的成员函数是不会被序列化的,被序列化的知识对象的数据成员。当需要从持久化数据中恢复对象时(也就算反序列化时),我们会首先实例化一个新的对象,然后将之前持久化的数据成员依次赋值给新对象的相应数据成员。顺便提下,JSON格式,可以很好的应用在序列化中,任何数组和对象都可以很容易的与json格式的字符串互相转换,且计算量不大。
三、读操作缓存
重复的身份验证
很早以前,我们喜欢将用户ID直接写入浏览器的cookies,并以此为荣,但是黑客很容易的篡改本地cookies来冒充其他用户,这时候新的方法出现了,那就是在用户登录的时候,我们会给其一个ticket字符串, 并将它写入浏览器cookies,随后的每次请求,我们都检查这个ticket,由于客户不知道我们发给其他用户的ticket,所以无法冒充其他用户。
缓存用户登录状态
但是有一点即使我们的查询效率很高,查询本身还是存在开销的,这很大程度上在于数据库的I/O操作,这个时候,就需要memcached了。这个时候应该充分的利用emcached的序列化,并且设置缓存数据的有效期,但是提醒一点,如果是用户注销了登录的话,记得清楚memcached中的登录状态缓存。
四、写操作缓存
对于一个数据库写操作频繁的站点来说,通过引入写缓存来减少写数据库的次数显得至关重要。通常的数据写操作包括插入、更新、删除,这些操作的同时可能又伴随着条件查找和索引的更新,所以这东西的开销往往是让人印象深刻的。
这个时候,就会用到memcached的原子递增操作,事实上,也正是因为它,我们才会考虑在访问量递增更新的应用中引入写缓存,写缓存的本质是,在对数据库的写入操作累积到你程序定义的数量时,它在一次行的去执行这些操作,虽然实际的写入往往会延迟几秒钟,但是通常情况下,我们对写入的操作也不是要求实时的,这样既提高了效率又满足了我们业务的需求,何乐不为?
这个时候,就会用到memcached的原子递增操作,事实上,也正是因为它,我们才会考虑在访问量递增更新的应用中引入写缓存,写缓存的本质是,在对数据库的写入操作累积到你程序定义的数量时,它在一次行的去执行这些操作,虽然实际的写入往往会延迟几秒钟,但是通常情况下,我们对写入的操作也不是要求实时的,这样既提高了效率又满足了我们业务的需求,何乐不为?
五、监控状态
作为一个分布式系统,虽然memcached能够出色的完成你交给它的任务,但是并不是代表你能对它放任不管,相反,我们需要知道它的运行状况,memcached提供了这样的协议,可以让你获得对它的实时状态。
来看个包括缓存状态的数组:
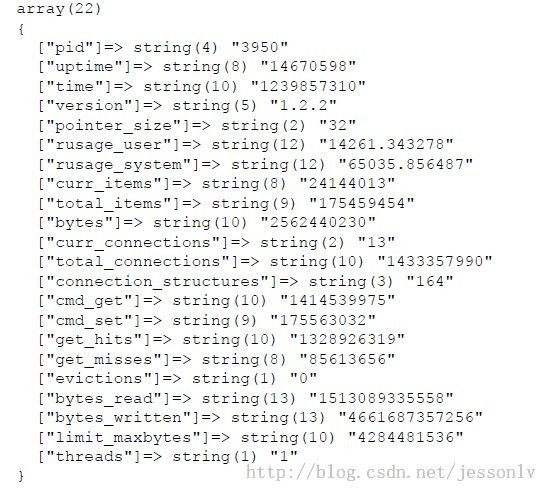
真的很全面,比如 uptime表示memcached持续运行的时间;cmd_get表示读取数据项的次数;cmd_set表示更新数据项的次数;get_hits表示缓存命中的次数;bytes_read表示读取字节的总数;bytes表示缓存区已经使用的大小;limit_maxbytes表示缓存区的总大小。
以上这么多的信息,我们可以从三个方面去看:
空间使用率
持续关注缓存空间的使用率,可以让我们知道何时需要为缓存系统扩容,以避免由于缓存空间已满造成的数据被动淘汰,有些数据项在过期之前被LRU算法淘汰可能会造成一定不良后果。缓存命中率
终端用户访问加速节点时,如果该节点有缓存住了要被访问的数据时就叫做命中,如果没有的话需要回原服务器取,就是没有命中。取数据的过程与用户访问是同步进行的,所以即使是重新取的新数据,用户也不会感觉到有延时。 命中率=命中数/(命中数+没有命中数), 缓存命中率是判断加速效果好坏的重要因素之一。非常教科书式的解释,大家自行消化。I/O流量
我们还需要关注memcached中数据项读写字节数的增长速度,这反应了它的工作量,我们从中可以得知memcached是忙还是空闲。同时我们也可能希望在监控系统中集成对memcached的监控,例如cacti监控系统,后面学习。缓存扩展
有很多理由让我们不得不扩展memcached的规模,包括并发处理能力和缓存空间容量等,不论哪个达到了极限,扩展都在所难免。对于缓存空间的容量,扩展既意味着增加物理内存,这有点不切实际,而对于并发处理能力,这正是memcached的特长所在,所以,我们只能增加缓存服务器来达到扩展的目的。
当有多台缓存服务器的时候,我们面临的是如何将缓存数据均衡的分布在多台服务器上,
一种是我们可以以商业逻辑来划分设计,另外一种是基于key的划分方式,
以商业逻辑来划分设计
比如一台用来缓存用户登录状态,一台用来缓存访问量统计:
10.0.1.12-->用户登录状态缓存
10.0.1.13-->访问量统计缓存
10.0.1.13-->访问量统计缓存
有两个问题出现:
一是这两台服务器的工作量均衡么?
二是如果两台仍不能满足需要,那如何继续扩展呢?
对于第一个问题,严格来说,要想达到真正的均衡是不现实的,由于它们的职责所在不同,它们的开销和访问率也不尽相同,所以有的只是相对的均衡。
对于第二个问题,加入访问量统计缓存需要扩展,那么我们准备一台新的服务器:10.0.1.14.然后将访问量统计缓存再次划分,同样基于业务逻辑为基础,例如将子站点划分为两部分,让它们分别存储在两台服务器上,这样就形成了:
10.0.1.12-->用户登录状态缓存
10.0.1.13-->访问量统计缓存 group1
10.0.1.14-->访问量统计缓存 group2
一是这两台服务器的工作量均衡么?
二是如果两台仍不能满足需要,那如何继续扩展呢?
对于第一个问题,严格来说,要想达到真正的均衡是不现实的,由于它们的职责所在不同,它们的开销和访问率也不尽相同,所以有的只是相对的均衡。
对于第二个问题,加入访问量统计缓存需要扩展,那么我们准备一台新的服务器:10.0.1.14.然后将访问量统计缓存再次划分,同样基于业务逻辑为基础,例如将子站点划分为两部分,让它们分别存储在两台服务器上,这样就形成了:
10.0.1.12-->用户登录状态缓存
10.0.1.13-->访问量统计缓存 group1
10.0.1.14-->访问量统计缓存 group2
基于key的划分方式
为此,我们需要设计一种不需要依赖数据项内容的散列算法,将所有数据项的key均衡分配在这三台缓存服务器上。一个简单而且有效的方法是取余运算,就像是打扑克时的发牌,让所有的数据项按照一个顺序在不同的缓存服务器上轮询,这样可以达到一个较好的均衡。
举个例子:
取余之前,我们要做一些准备工作,目的是让key变成整数,而且尽量唯一,比如这个key是:jessonlv-1986.htm
我们先对它进行md5运算,得到一个32字节的字符串比如是:e6e87fc57lkji1245lki1547iuhgt632,同时也是一个十六进制的长整数,为了节省开销,我们取这个字符串的前5个字节,然后将其转化为十进制数:比如945689,这个时候我们再将这个数字进行“模3”的运算。取余的结果就是我们服务器的编号,服务器的编号从0开始。
这里有个问题也许你一直在思考,那就是我们扩展缓存系统后,由于分区算法的改变,会涉及缓存数据需要从一台缓存服务器迁移到另一台缓存服务器的问题,如何迁移呢?事实上,根本不需要考虑迁移的问题,因为是缓存,它应该具备关键时刻牺牲自己的勇气,你必须明白缓存不是持久性存储,并且从引入分布式缓存时就得时刻提醒自己。
没错,当调整缓存区算法后,我们需要时间来等待缓存的重建和预热,但这往往并不影响站点的正常运转,前提是你要按照文章前面堵缓存和写缓存的设计理念来进行设计。。。
举个例子:
取余之前,我们要做一些准备工作,目的是让key变成整数,而且尽量唯一,比如这个key是:jessonlv-1986.htm
我们先对它进行md5运算,得到一个32字节的字符串比如是:e6e87fc57lkji1245lki1547iuhgt632,同时也是一个十六进制的长整数,为了节省开销,我们取这个字符串的前5个字节,然后将其转化为十进制数:比如945689,这个时候我们再将这个数字进行“模3”的运算。取余的结果就是我们服务器的编号,服务器的编号从0开始。
这里有个问题也许你一直在思考,那就是我们扩展缓存系统后,由于分区算法的改变,会涉及缓存数据需要从一台缓存服务器迁移到另一台缓存服务器的问题,如何迁移呢?事实上,根本不需要考虑迁移的问题,因为是缓存,它应该具备关键时刻牺牲自己的勇气,你必须明白缓存不是持久性存储,并且从引入分布式缓存时就得时刻提醒自己。
没错,当调整缓存区算法后,我们需要时间来等待缓存的重建和预热,但这往往并不影响站点的正常运转,前提是你要按照文章前面堵缓存和写缓存的设计理念来进行设计。。。