Practical Machine Learning实用机器学习 章1
http://blog.csdn.net/pipisorry/article/details/46490177
实用机器学习Practical Machine Learning courses学习笔记
Practical Machine Learning实用机器学习
1.1 Prediction motivation预测的动机
课程概览About this course
This course covers the basic ideas behind machine learning/prediction, What this course depends on What would be useful
·Study design training
vs. test sets
Conceptual issues out
of sample error, ROC curves
Practical implementation the
caret package
·The Data Scientist's Toolbox
R Programming
·Exploratory analysis
Reporting Data and Reproducible Research
Regression models
机器学习的用处
Local governments > pension(退休金) payments
Google >whether you will click on an ad
Amazon >what movies you will watch
Insurance companies >what your risk of death is
Johns Hopkins >who will succeed in their programs
推荐书目及资源
The elements of statistical learning
Machine learning (more advanced material)
List of machine learning resources on Quora
List of machine learning resources from Science
Advanced notes from MIT open courseware
Advanced notes from CMU
Kaggle machine learning competitions
1.2 什么是预测What is prediction
预测问题的中心教条dogma
predict for these dots whether they're red or blue:

choosing the right dataset and that knowing what the specific question is are again paramount(最重要的)
可能存在的问题
一个例子:Google Flu trends algorithm didn't realize the search terms that people would use would change overtime.They might use different terms when they were searching, and so that would affect the algorithm's performance.And also, the way that those terms were actually being used in the algorithm wasn't very well understood.And so when the function of a particular search term changed in their algorithm, it can cause problems.
预测器的流程components of a predictor
question -> input data -> features -> algorithm -> parameters -> evaluation
Note: question: What are you trying to predict and what are you trying to predict it with?
预测的一个例子:垃圾邮件
question -> input data -> features -> algorithm -> parameters -> evaluation
Start with a general question
Can I automatically detect emails that are SPAM that are not?
Make it concrete
Can I use quantitative characteristics of the emails to classify them as SPAM/HAM?
Note:try to make it as concrete as possible
question -> input data -> features -> algorithm -> parameters -> evaluation
rss.acs.unt.edu/Rdoc/library/kernlab/html/spam.html
question -> input data -> features -> algorithm -> parameters -> evaluation
library(kernlab)
data(spam)
head(spam)Our simple algorithm
- Find a value C .
- frequency of 'your' > C predict "spam"
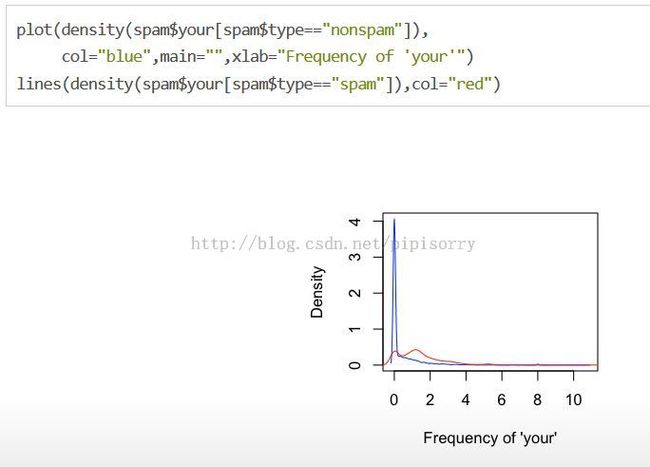
Note:best cut off is above 0.5 then we say that it's SPAM, and if it's below 0.5 we can say that it's HAM.
question -> input data -> features -> algorithm -> parameters -> evaluation

question -> input data -> features -> algorithm -> parameters -> evaluation

1.3 步骤的相对重要性Relative importance of steps
{about the tradeoffs and the different components of building a machine learning algorithm}
Relative order of importance:question > data > features > algorithms
...
Then creating features is an important component in that if you don't compress the data in the right way you might lose all of the relevant and valuable information.
And finally, in my experience it's been the algorithmis often the least important part of building a machine learning algorithm.It can be very important depending on the exact modality of the type of data that you're using.For example, image data and voice data can require certain kinds of prediction algorithms that might not necessarily be as.
An important point
The combination of some data and an aching desire for an answer does not ensure that a reasonable answer can be extracted from a given body of data.--John Tukey
In other words, an important component of knowing how to do prediction is to know when to give up,when the data that you have is just not sufficient to answer the question that you're trying to answer.
Garbage in = Garbage out
question -> input data -> features -> algorithm -> parameters -> evaluation- May be easy (movie ratings -> new movie ratings)
- May be harder (gene expression data -> disease)
- Depends on what is a "good prediction".
- Often more data > better models
- The most important step!
特征关系重大Features matter!
question -> input data -> features -> algorithm -> parameters -> evaluationProperties of good features
- Lead to data compression
- Retain relevant information
- Are created based on expert application knowledge
Note:there's a debate in the community about whether it's better to create features automatically or whether it's better to use expert domain knowledge.And in general it seems that the, expert domain knowledge can help quite a bit in many, many applications and so should be consulted when building a features for machine learning algorithm.
Common mistakes
- Trying to automate feature selection
- Not paying attention to data-specific quirks
- Throwing away information unnecessarily
Note:
1. Some common mistake are trying to automate feature selection in a way that doesn't allow for you to understand how those features are actually.Being applied to make good predictions.Black box predictions can be very useful,can be very accurate but they can also change on a dime if we're not paying attention to how those features actually do predict the outcome.
2. The function of a particular set of data set might be that there's outlines if there's weird behaviors of specific features and not understanding those can cause problems.
Based on a bunch of features they sort of collected in an unsupervised way.In other words they filtered through the data in a way to identify those features that might be useful for later predictive algorithms.But even when they did this, they went back and looked at those features and tried to figure out why they would be predictive and so for example these features, this feature here makes it very clear why it would be a good predictor for a cat.
算法并没有那么重要Algorithms matter less than you'd think
question -> input data -> features -> algorithm -> parameters -> evaluationUsing a very, sensible approach will get you a very large weight of solving the problem.And then, getting the absolute best method can improve, but it often doesn't improve that much over, sort of, most good sensible methods.
建立机器学习算法要考虑的问题

Note:Scalable means it's easy to apply to a large data set.Whether that's because it's very very fast or whether it's because it's parallelizable across multiple samples for example.
[Gaining access to the best machine-learning methods]
Prediction is about accuracy tradeoffs
- Interpretability versus accuracy
- Speed versus accuracy
- Simplicity versus accuracy
- Scalability versus accuracy

Note:如医疗上,医生更容易理解决策树形式的。
http://www.cs.cornell.edu/~chenhao/pub/mldg-0815.pdf
Scalability matters

http://www.techdirt.com/blog/innovation/articles/20120409/03412518422/
http://techblog.netflix.com/2012/04/netflix-recommendations-beyond-5-stars.html
Note:netflix从未应用竞赛的算法到实际中是因为拓展性问题,不能应用到大数据中
1.4 训练集和测试集误差 In and out of sample errors
In Sample Error: The error rate you get on the samedata set you used to build your predictor. Sometimescalled resubstitution error.
Out of Sample Error: The error rate you get on a newdata set. Sometimes called generalization error.
Key ideas
- Out of sample error is what you care about
- In sample error < out of sample error
- The reason is overfitting : Matching your algorithm to the data you have
Note:
1. In sample error is always going to be a little bit optimistic,from what the error is that you would get from a new sample.And the reason why is, in your specific sample, sometimes your prediction algorithm will tune itself a little bit to the noise that you collected in that particular data set.
2. So sometimes you want to be able to give up a little bit of accuracy in the sample you have, to be able to get accuracy on new data sets.In other words, when the noise is a little bit different, your algorithm will berobust.
过拟合Overfitting
- Data have two parts
- Signal : the part we're trying to use to predict
- Noise : random variation in the dataset that we get, because the data are measured noisily.
- Signal : the part we're trying to use to predict
- The goal of a predictor is to find signal
- You can always design a perfect in-sample predictor; You capture both signal + noise when you do that; Predictor won't perform as well on new samples
1.5 预测的研究设计Prediction study design
{about how to minimize the problems that can be caused by in sample verses out of sample errors}
- Define your error rate
- Split data into:
- Training, Testing, Validation (optional)
- On the training set pick features
- Use cross-validation
- On the training set pick prediction function
- Use cross-validation
- If no validation
- Apply 1x to test set
- If validation
- Apply to test set and refine
- Apply 1x to validation
1. 5:why do we only apply it one time?If we applied multiple models to our testing set, then, and pick the best one, then we're using the test set, in some sense, to train the model.In other words, we're still getting an optimistic view of what the data error would be on a completely new dataset.
2. 6:apply your best prediction models all to your test set and refine them a little bit.So what you might find is that some features don't work so well when you're doing out of sample prediction and you might refine and adjust your model a little bit.But now, again, like I said, your test set error is going to be a little bit optimistic error for what your actual out of sample error will be.And so what we do is we again, apply our model to exactly one time to the validation set, only the best one to get our prediction.
3. The idea is that there is one dataset that's held out from the very start, that you only apply exactly one model to, and you never do any training or tuning or testing to, and that will give you a good estimate of your out of sample error rates.
Know the benchmarks
http://www.heritagehealthprize.com/c/hhp/leaderboardStudy design

http://www2.research.att.com/~volinsky/papers/ASAStatComp.pdf
Avoid small sample sizes
- One classifier is flipping a coin
- Probability of perfect classification is approximately:
- (12)samplesize
- n=1 flipping coin 50% chance of 100% accuracy
- n=2 flipping coin 25% chance of 100% accuracy
- n=10 flipping coin 0.10% chance of 100% accuracy
数据集划分规则Rules of thumb for prediction study design
- If you have a large sample size
- 60% training
- 20% test
- 20% validation
- If you have a medium sample size
- 60% training
- 40% testing
- If you have a small sample size
- Do cross validation
- Report caveat of small sample size
1. 2:you don't get to refine your models in a test set and then apply them to a validation set.But it might insure that your testing site is of sufficient size.
2. 3:First of all, you might reconsider whether you have enough samples to be able to build a prediction algorithm in the first place.But suppose your dead set on building a prediction or machine learning algorithm, then the idea might be to do cross validation and report the caveat of the small sample size and the fact that you never got to predict this in an out of sample or a testing data set.
要记住的原则Some principles to remember
- 1. Set the test/validation set aside and don't look at it
- 2. In general randomly sample training and test
- 3. Your data sets must reflect structure of the problem
- If predictions evolve with time split train/test in time chunks (calledbacktesting in finance)
- 4. All subsets should reflect as much diversity as possible
- Random assignment does this
- You can also try to balance by features - but this is tricky
1. the test set or the validation set should be set aside and never looked at when building your model.In other words, you would need to have one data set which you apply only one model to, only one time, and that data set should be completely independent of anything you use to build the prediction model.
2. So for example, if you have, time fit time force data, in other words you have, data collected over time, you might want to build your, training set inchunksof time, but again, random chunks of time and build them on random predictions.
3. In other words, if you want to sample any data set that might have sources of dependence over time or across space,you need to sample your data in chunks.This is called backtesting in finance.And it's basically the idea that you want to be able to use chunks of data that consist of observations over time.
1.6 误差类型Types of errors
{about the types of errors and the ways that evaluate the prediction functions}
基本术语 Basic terms
对于二分类问题:
In general, Positive = identified and negative = rejected. Therefore:
True positive = correctly identified
False positive = incorrectly identified
True negative = correctly rejected
False negative = incorrectly rejected
Medical testing example:
True positive = Sick people correctly diagnosed as sick
False positive= Healthy people incorrectly identified as sick
True negative = Healthy people correctly identified as healthy
False negative = Sick people incorrectly identified as healthy.
关键量 Key quantities
敏感性sensitivity(召回率recall)、特异性specificity、正预测值positive predictive value(精确度precision)、负预测值、准确性accuracy

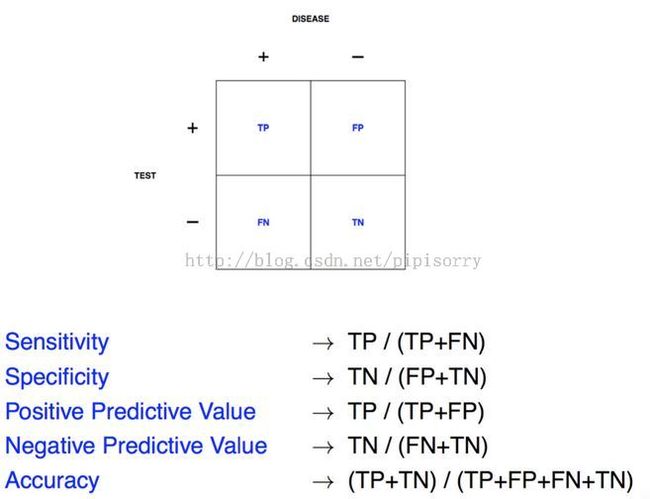

Note:
1. the columns correspond to what your disease status is, in this particular example,positive means that you have the disease.
2. And the test is our prediction, our machine learning algorithm.A positive means we predict that you have a disease.
3. 准确性the accuracy is just a probability that we classified you to the correct outcome.It's the true positives, and the true negatives, just added up.
[ Precision/Recall精确度/召回率]
[http://en.wikipedia.org/wiki/Sensitivity_and_specificity]
筛选试验 Screening tests

The general population(0.1%)
if you got a positive test, what's the probability that you actually have the disease?(也就是已知下面题目(左)中的sensitivity和specificity以及0.001的人群感染率,求positive predictive value)

Note:
1. 敏感性和特异性解释:In other words, the probability that we'll get it right, if you're diseased is 99%, and the probability we'll get it right if you're healthy is 99%.
2. 另两种解法:

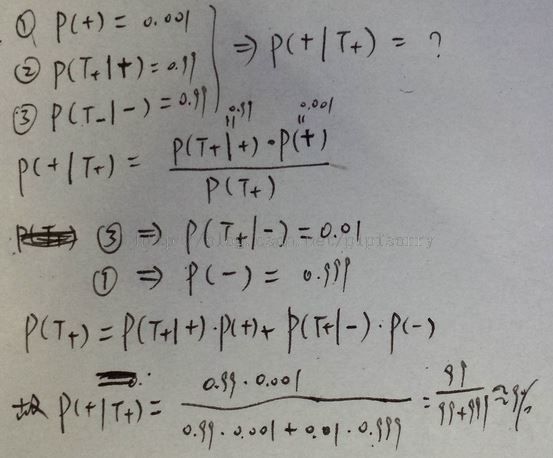
{右图中+代表实际有病,T+代表算法检测有病}
3. 算出结果很小的原因是:
The reason is 99%(99) of a small number, so 99 out of 100. is still smaller than 1%(999) out of a much bigger number.
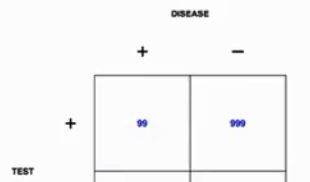
High risk sub-population(10%)
If instead we consider the case where 10% of people are actually sick
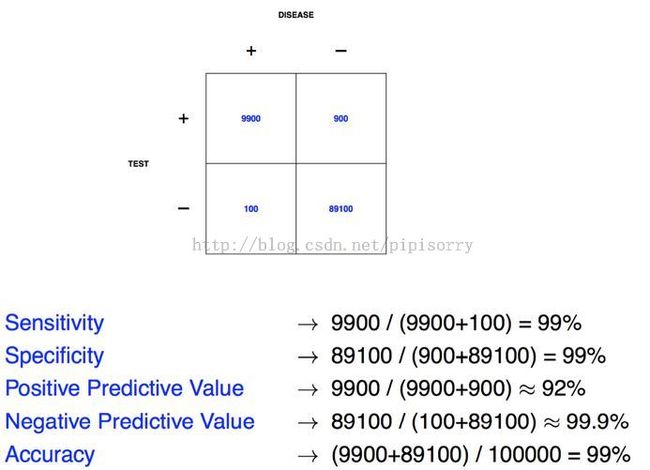
Note:这时计算出的结果为92%,明显大了很多
结论:
If you're predicting a rare event.You have to be aware of, how rare that event is.This goes back to the idea of knowing what population you're sampling from.
[ http://www.biostat.jhsph.edu/~iruczins/teaching/140.615/]
连续型数据度量 For continuous data

Note:
1. The goal here is to see how close you are to the truth.
2. squared this distance is a little bit hard to interpret on the same scale as the predictions or the truth.And so they take the square root of that quantity.
But RMSE often doesn't work when there are a lot of outliers.Or the values of the variables can have very different scales.for example, if you have one really,really large value.It might really raise the mean.
常见的误差度量方法 Common error measures
- Median absolute deviation 平均绝对偏差
- Continuous data, often more robust
- Sensitivity (recall)
- If you want few missed positives
- Specificity
- If you want few negatives called positives
- Accuracy
- Weights false positives/negatives equally
- Concordance调和
- One example is kappa
1. Median absolute deviation:they take the median of the diff, distance between the observed value,and the predicted value, and they do the absolute value instead of doing the squared value.And so again, that requires all of the distances to be positive,but it's a little bit more robust to the size of those errors.
2.3. sensitivity and specificity are very commonly used when talking about particularly medical tests, but they also are particularly widely used if you care about one type of error more than the other type of error.
4. accuracy is an important point if again you have a very large discrepancy(差异) in number of times that you're a positive or a negative.
5. For multiclass cases,one particular distance measure, kappa.But there are a whole large class of distance measures, and they all have different properties, that can be used when you have multiclass data.
from: http://blog.csdn.net/pipisorry/article/details/46490177