OpenRisc-45-or1200的ID模块分析
引言
之前,我们分析了or1200流水线的整体结构,也分析了流水线中IF级,EX级,本小节我们来分析ID(insn decode)级的一些细节。
1,基础
or1200的pipeline的ID阶段包含一个模块,就是ctrl模块,其对应的文件是or1200_ctrl.v。ID,就是instruction decode,顾名思义,其主要任务就是对从IF阶段取得的指令进行解析,产生各种控制信号。
在分析本模块之前,我们有必要先了解几个相关的概念,这对后面的RTL的分析会有很大帮助。
1>forwording & bypassing
forwording(前递) 和 bypassing(旁路)技术,是现在流水线中非常常见的技术,其作用主要是消除由于数据相关造成的流水线阻塞。什么意思呢?假如某个流水线有5 stages,指令A和指令B在流水线中执行,A在B前面,指令B需要指令A的运算结果,指令A的运算结果在EX阶段就能算出。如果不用forwording & bypassing技术,指令B要等到指令A完成WB阶段的操作之后才能执行,也就是说指令B在指令A完成WB阶段之前必须阻塞。这显然会降低流水线的效率,怎么办呢?就是引进forwording & bypassing技术,将指令A在EX阶段算出结果之后直接送给指令B,而不需要等到WB阶段。
为了便于理解,我们在举一个通俗点的例子,假如现在是8月份,小张(在北京)有一本书被小王(在上海)借走了,小张出差了,到10月份才能回来,小王到9月份就能把书看完,但是如果要归还的话,只能等到10月份,现在呢,小李(也在上海)又想借这本书,怎么办?如果一定要小王把书从上海寄回北京,然后等到小张10月份出差回来,再把书寄回上海的小李。这样做显然是太愚蠢了,直接打个电话让小王看完之后给小李就可以了嘛。那个电话,就是forwording & bypassing。
关于forwording & bypassing,如有兴趣,请参考:http://en.wikipedia.org/wiki/Hazard_(computer_architecture)#Register_forwarding
2>pipeline bubble
pipeline bubble(流水线气泡),如果一切顺利,所有指令没有任何相关,也没有什么branch/jump指令的话。流水线的所有阶段在任何时刻都会正常工作,不会闲置。
但“人生不如意十之八九”,没有一帆风顺的事情,加入出现branch/jump的话,分支地址又不是紧跟后面的指令的话,那么紧跟后面的指令的所有流水线处理就是无效的,为了避免这种情况的出现,一般在branch/jump指令后面增加一条甚至多条NOP指令,即所谓的延迟槽,这时,流水线在某个时刻,有的流水线阶段就是空闲的,也就是出现了流水线气泡。关于pipeline bubble,如有兴趣,请参考:http://en.wikipedia.org/wiki/Bubble_(computing)
3>其他
关于分支预测(branch prediction),动态调度(dynamic schedule),循环展开(loop unrolling)等等这些技术,我们之前都介绍过了,这里不再赘述,如有疑问,请参考之前的blog内容。
2,or1200的ID模块
1>整体分析
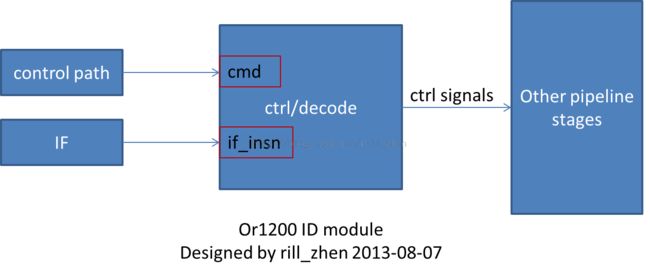
前面我们说过,or1200采用的是5 stages integer static pipeline。ID(指令解码)是其中的第二个阶段,对应的是ctrl模块,这个阶段的任务大体可分为两个方面:
第一个方面是根据其他模块的控制,产生更详细的控制信号,来完成其他模块交给的任务,比如except模块捕获到了一个异常,想让流水线刷新,那么except模块送给ctrl模块一个信号,然后由ctrl模块产生相应的控制信号,刷新整条流水线。
第二个方面就是将F阶段送来的指令,根据指令的定义,而完成对所有指令的解析,解析的结果就是产生不同的控制信号。比如,如果是一条运算指令,那么就把操作数a和操作数b都取出来,送到rf_a和rf_b里面(关于rf模块,我们前面提到过,如有疑问请参考:http://blog.csdn.net/rill_zhen/article/details/9769937),并根据运算类型,产生对应的操作信号(如果是alu运算,就产生alu_op信号,如果是mac运算,就产生mac_op信号)。
ID阶段的整体结构简图,如下所示:
2>模块分析
了解了ctrl模块的大体功能是远远不够的,我们还需要知道其工作细节,下面我们就分析一下ctrl的内部情况。
1》流水线刷新信号的产生
这个部分工作,一共有4个信号,分别是if_flushpipe:刷新IF阶段;id_flushpipe,刷新ID阶段;ex_flushpipe,刷新EX阶段;wb_flushpipe,刷新WB阶段。
这几个信号是怎么产生的呢?代码实现如下:
// // Flush pipeline // assign if_flushpipe = except_flushpipe | pc_we | extend_flush; assign id_flushpipe = except_flushpipe | pc_we | extend_flush; assign ex_flushpipe = except_flushpipe | pc_we | extend_flush; assign wb_flushpipe = except_flushpipe | pc_we | extend_flush;
2》id_insn,流水线正在解码的指令暂时保存
在ctrl模块内部,有一个寄存器来保存从IF阶段传来的指令(if_insn),这个寄存器就是id_insn.它又是如何使用的呢,如下所示:
//
// Instruction latch in id_insn
//
always @(posedge clk or `OR1200_RST_EVENT rst)
begin
if (rst == `OR1200_RST_VALUE)
id_insn <= {`OR1200_OR32_NOP, 26'h041_0000};
else if (id_flushpipe)
id_insn <= {`OR1200_OR32_NOP, 26'h041_0000}; // NOP -> id_insn[16] must be 1
else if (!id_freeze) begin
id_insn <= if_insn;
end
end
3》ex_insn,给外部的信号
表示当前正在处理的指令,这个信号最终会送到du模块,用来调试时,可以知道当前正在解码的指令是什么。
代码如下:
//
// Instruction latch in ex_insn
//
always @(posedge clk or `OR1200_RST_EVENT rst) begin
if (rst == `OR1200_RST_VALUE)
ex_insn <= {`OR1200_OR32_NOP, 26'h041_0000};
else if (!ex_freeze & id_freeze | ex_flushpipe)
ex_insn <= {`OR1200_OR32_NOP, 26'h041_0000}; // NOP -> ex_insn[16] must be 1
else if (!ex_freeze) begin
ex_insn <= id_insn;
end
end
4》ex_branch_op,表示分支指令的操作
这个信号送给了genpc模块和外部的du模块,宽度为3-bit。
代码如下:
// // Generation of ex_branch_op // always @(posedge clk or `OR1200_RST_EVENT rst) if (rst == `OR1200_RST_VALUE) ex_branch_op <= `OR1200_BRANCHOP_NOP; else if (!ex_freeze & id_freeze | ex_flushpipe) ex_branch_op <= `OR1200_BRANCHOP_NOP; else if (!ex_freeze) ex_branch_op <= id_branch_op;
5》id_branch_op,表示PC的偏移的低3-bit
这个信号送给了genpc模块。我们前面说过,在进行分支预测时需要PC的偏移值,这个信号就是。
代码如下:
// // Decode of id_branch_op // always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) id_branch_op <= `OR1200_BRANCHOP_NOP; else if (id_flushpipe) id_branch_op <= `OR1200_BRANCHOP_NOP; else if (!id_freeze) begin case (if_insn[31:26]) // synopsys parallel_case // l.j `OR1200_OR32_J: id_branch_op <= `OR1200_BRANCHOP_J; // j.jal `OR1200_OR32_JAL: id_branch_op <= `OR1200_BRANCHOP_J; // j.jalr `OR1200_OR32_JALR: id_branch_op <= `OR1200_BRANCHOP_JR; // l.jr `OR1200_OR32_JR: id_branch_op <= `OR1200_BRANCHOP_JR; // l.bnf `OR1200_OR32_BNF: id_branch_op <= `OR1200_BRANCHOP_BNF; // l.bf `OR1200_OR32_BF: id_branch_op <= `OR1200_BRANCHOP_BF; // l.rfe `OR1200_OR32_RFE: id_branch_op <= `OR1200_BRANCHOP_RFE; // Non branch instructions default: id_branch_op <= `OR1200_BRANCHOP_NOP; endcase end end
6》rf_addrw,表示要向rf模块写入的地址
代码如下:
// // Register file write address // always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) rf_addrw <= 5'd0; else if (!ex_freeze & id_freeze) rf_addrw <= 5'd00; else if (!ex_freeze) case (id_insn[31:26]) // synopsys parallel_case `OR1200_OR32_JAL, `OR1200_OR32_JALR: rf_addrw <= 5'd09; // link register r9 default: rf_addrw <= id_insn[25:21]; endcase end
7》rf_addra,rf_addrb,rf_rda,rf_rdb,这个四个信号表示从rf模块读的地址
代码如下:
// // Register file read addresses // assign rf_addra = if_insn[20:16]; assign rf_addrb = if_insn[15:11]; assign rf_rda = if_insn[31] || if_maci_op; assign rf_rdb = if_insn[30];
8》alu_op,ALU操作码的解析
这个信号是从各个运算指令中解析出的ALU运算的操作码。
代码如下:
//
// Decode of alu_op
//
always @(posedge clk or `OR1200_RST_EVENT rst) begin
if (rst == `OR1200_RST_VALUE)
alu_op <= `OR1200_ALUOP_NOP;
else if (!ex_freeze & id_freeze | ex_flushpipe)
alu_op <= `OR1200_ALUOP_NOP;
else if (!ex_freeze) begin
case (id_insn[31:26]) // synopsys parallel_case
// l.movhi
`OR1200_OR32_MOVHI:
alu_op <= `OR1200_ALUOP_MOVHI;
// l.addi
`OR1200_OR32_ADDI:
alu_op <= `OR1200_ALUOP_ADD;
// l.addic
`OR1200_OR32_ADDIC:
alu_op <= `OR1200_ALUOP_ADDC;
// l.andi
`OR1200_OR32_ANDI:
alu_op <= `OR1200_ALUOP_AND;
// l.ori
`OR1200_OR32_ORI:
alu_op <= `OR1200_ALUOP_OR;
// l.xori
`OR1200_OR32_XORI:
alu_op <= `OR1200_ALUOP_XOR;
// l.muli
`ifdef OR1200_MULT_IMPLEMENTED
`OR1200_OR32_MULI:
alu_op <= `OR1200_ALUOP_MUL;
`endif
// Shift and rotate insns with immediate
`OR1200_OR32_SH_ROTI:
alu_op <= `OR1200_ALUOP_SHROT;
// SFXX insns with immediate
`OR1200_OR32_SFXXI:
alu_op <= `OR1200_ALUOP_COMP;
// ALU instructions except the one with immediate
`OR1200_OR32_ALU:
alu_op <= {1'b0,id_insn[3:0]};
// SFXX instructions
`OR1200_OR32_SFXX:
alu_op <= `OR1200_ALUOP_COMP;
`ifdef OR1200_IMPL_ALU_CUST5
// l.cust5
`OR1200_OR32_CUST5:
alu_op <= `OR1200_ALUOP_CUST5;
`endif
// Default
default: begin
alu_op <= `OR1200_ALUOP_NOP;
end
endcase
end
end
9》alu_op2,特殊情况下ALU操作码的输出
代码如下:
// // Decode of second ALU operation field [9:6] // always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) alu_op2 <= 0; else if (!ex_freeze & id_freeze | ex_flushpipe) alu_op2 <= 0; else if (!ex_freeze) begin alu_op2 <= id_insn[`OR1200_ALUOP2_POS]; end end
10》mac_op,id_mac_op,mac运算的操作码解析
在=解析过程中使用了ex_mac_op中间临时寄存器,代码如下:
// // Decode of mac_op // `ifdef OR1200_MAC_IMPLEMENTED always @(id_insn) begin case (id_insn[31:26]) // synopsys parallel_case // l.maci `OR1200_OR32_MACI: id_mac_op = `OR1200_MACOP_MAC; // l.mac, l.msb `OR1200_OR32_MACMSB: id_mac_op = id_insn[2:0]; // Illegal and OR1200 unsupported instructions default: id_mac_op = `OR1200_MACOP_NOP; endcase end always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) ex_mac_op <= `OR1200_MACOP_NOP; else if (!ex_freeze & id_freeze | ex_flushpipe) ex_mac_op <= `OR1200_MACOP_NOP; else if (!ex_freeze) ex_mac_op <= id_mac_op; end assign mac_op = abort_mvspr ? `OR1200_MACOP_NOP : ex_mac_op; `else assign id_mac_op = `OR1200_MACOP_NOP; assign mac_op = `OR1200_MACOP_NOP; `endif
11》rfwb_op,rf(register file)的write back操作码的解析
代码如下:
//
// Decode of rfwb_op
//
always @(posedge clk or `OR1200_RST_EVENT rst) begin
if (rst == `OR1200_RST_VALUE)
rfwb_op <= `OR1200_RFWBOP_NOP;
else if (!ex_freeze & id_freeze | ex_flushpipe)
rfwb_op <= `OR1200_RFWBOP_NOP;
else if (!ex_freeze) begin
case (id_insn[31:26]) // synopsys parallel_case
// j.jal
`OR1200_OR32_JAL:
rfwb_op <= {`OR1200_RFWBOP_LR, 1'b1};
// j.jalr
`OR1200_OR32_JALR:
rfwb_op <= {`OR1200_RFWBOP_LR, 1'b1};
// l.movhi
`OR1200_OR32_MOVHI:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
// l.mfspr
`OR1200_OR32_MFSPR:
rfwb_op <= {`OR1200_RFWBOP_SPRS, 1'b1};
// l.lwz
`OR1200_OR32_LWZ:
rfwb_op <= {`OR1200_RFWBOP_LSU, 1'b1};
// l.lbz
`OR1200_OR32_LBZ:
rfwb_op <= {`OR1200_RFWBOP_LSU, 1'b1};
// l.lbs
`OR1200_OR32_LBS:
rfwb_op <= {`OR1200_RFWBOP_LSU, 1'b1};
// l.lhz
`OR1200_OR32_LHZ:
rfwb_op <= {`OR1200_RFWBOP_LSU, 1'b1};
// l.lhs
`OR1200_OR32_LHS:
rfwb_op <= {`OR1200_RFWBOP_LSU, 1'b1};
// l.addi
`OR1200_OR32_ADDI:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
// l.addic
`OR1200_OR32_ADDIC:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
// l.andi
`OR1200_OR32_ANDI:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
// l.ori
`OR1200_OR32_ORI:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
// l.xori
`OR1200_OR32_XORI:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
// l.muli
`ifdef OR1200_MULT_IMPLEMENTED
`OR1200_OR32_MULI:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
`endif
// Shift and rotate insns with immediate
`OR1200_OR32_SH_ROTI:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
// ALU instructions except the one with immediate
`OR1200_OR32_ALU:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
`ifdef OR1200_ALU_IMPL_CUST5
// l.cust5 instructions
`OR1200_OR32_CUST5:
rfwb_op <= {`OR1200_RFWBOP_ALU, 1'b1};
`endif
`ifdef OR1200_FPU_IMPLEMENTED
// FPU instructions, lf.XXX.s, except sfxx
`OR1200_OR32_FLOAT:
rfwb_op <= {`OR1200_RFWBOP_FPU,!id_insn[3]};
`endif
// Instructions w/o register-file write-back
default:
rfwb_op <= `OR1200_RFWBOP_NOP;
endcase
end
end
12》fpu_op,float point process运算的操作码解析
代码如下,需要说明的是ORPSoC的FPU模块并没有实现。
//
// Decode of FPU ops
//
`ifdef OR1200_FPU_IMPLEMENTED
assign fpu_op = {(id_insn[31:26] == `OR1200_OR32_FLOAT),
id_insn[`OR1200_FPUOP_WIDTH-2:0]};
`else
assign fpu_op = {`OR1200_FPUOP_WIDTH{1'b0}};
`endif
13》wb_insn
代码如下,需要注意的是这个信号不能被异常所修改。
wb_insn should not be changed by exceptions due to correct recording of display_arch_state in the or1200_monitor! wb_insn changed by exception is not used elsewhere!
//
// Instruction latch in wb_insn
//
always @(posedge clk or `OR1200_RST_EVENT rst) begin
if (rst == `OR1200_RST_VALUE)
wb_insn <= {`OR1200_OR32_NOP, 26'h041_0000};
else if (!wb_freeze) begin
wb_insn <= ex_insn;
end
end
14》id_branch_addrtarget,分支指令跳转地址
代码如下:
//
// ID Sign extension of branch offset
//
assign id_branch_addrtarget = {{4{id_insn[25]}}, id_insn[25:0]} + id_pc[31:2];
15》ex_branch_addrtarget
是id_branch_addrtarget信号的备份,留给debug使用
代码如下:
// pipeline ID and EX branch target address always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) ex_branch_addrtarget <= 0; else if (!ex_freeze) ex_branch_addrtarget <= id_branch_addrtarget; end
16》sel_a,sel_b,选择要处理的操作码
这两个信号送给了operandmuxes模块,每个信号为2-bit.,表示操作数是来自于哪里,有4中可能:通用寄存器,wb会写数据,ex的执行结果(forword而来),立即数。
代码如下:
// // Generation of sel_a // always @(rf_addrw or id_insn or rfwb_op or wbforw_valid or wb_rfaddrw) if ((id_insn[20:16] == rf_addrw) && rfwb_op[0]) sel_a = `OR1200_SEL_EX_FORW; else if ((id_insn[20:16] == wb_rfaddrw) && wbforw_valid) sel_a = `OR1200_SEL_WB_FORW; else sel_a = `OR1200_SEL_RF; // // Generation of sel_b // always @(rf_addrw or sel_imm or id_insn or rfwb_op or wbforw_valid or wb_rfaddrw) if (sel_imm) sel_b = `OR1200_SEL_IMM; else if ((id_insn[15:11] == rf_addrw) && rfwb_op[0]) sel_b = `OR1200_SEL_EX_FORW; else if ((id_insn[15:11] == wb_rfaddrw) && wbforw_valid) sel_b = `OR1200_SEL_WB_FORW; else sel_b = `OR1200_SEL_RF;
17》id_lsu_op,load/store指令的操作码解析
代码如下:
// // Decode of id_lsu_op // always @(id_insn) begin case (id_insn[31:26]) // synopsys parallel_case // l.lwz `OR1200_OR32_LWZ: id_lsu_op = `OR1200_LSUOP_LWZ; // l.lbz `OR1200_OR32_LBZ: id_lsu_op = `OR1200_LSUOP_LBZ; // l.lbs `OR1200_OR32_LBS: id_lsu_op = `OR1200_LSUOP_LBS; // l.lhz `OR1200_OR32_LHZ: id_lsu_op = `OR1200_LSUOP_LHZ; // l.lhs `OR1200_OR32_LHS: id_lsu_op = `OR1200_LSUOP_LHS; // l.sw `OR1200_OR32_SW: id_lsu_op = `OR1200_LSUOP_SW; // l.sb `OR1200_OR32_SB: id_lsu_op = `OR1200_LSUOP_SB; // l.sh `OR1200_OR32_SH: id_lsu_op = `OR1200_LSUOP_SH; // Non load/store instructions default: id_lsu_op = `OR1200_LSUOP_NOP; endcase end
18》comp_op,比较指令的操作码解析,送给ALU单元
代码如下:
// // Decode of comp_op // always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) begin comp_op <= 4'd0; end else if (!ex_freeze & id_freeze | ex_flushpipe) comp_op <= 4'd0; else if (!ex_freeze) comp_op <= id_insn[24:21]; end
19》multicycle,根据指令类型,判断是否是多个cycle完成还是单个cycle完成。
这个信号送给freeze模块,代码如下:
//
// Decode of multicycle
//
always @(id_insn) begin
case (id_insn[31:26]) // synopsys parallel_case
// l.rfe
`OR1200_OR32_RFE,
// l.mfspr
`OR1200_OR32_MFSPR:
multicycle = `OR1200_TWO_CYCLES; // to read from ITLB/DTLB (sync RAMs)
// Single cycle instructions
default: begin
multicycle = `OR1200_ONE_CYCLE;
end
endcase
end
20》wait_on,流水线等待的周期数
这个信号也是送给了freeze模块,代码如下:
//
// Encode wait_on signal
//
always @(id_insn) begin
case (id_insn[31:26]) // synopsys parallel_case
`OR1200_OR32_ALU:
wait_on = ( 1'b0
`ifdef OR1200_DIV_IMPLEMENTED
| (id_insn[4:0] == `OR1200_ALUOP_DIV)
| (id_insn[4:0] == `OR1200_ALUOP_DIVU)
`endif
`ifdef OR1200_MULT_IMPLEMENTED
| (id_insn[4:0] == `OR1200_ALUOP_MUL)
| (id_insn[4:0] == `OR1200_ALUOP_MULU)
`endif
) ? `OR1200_WAIT_ON_MULTMAC : `OR1200_WAIT_ON_NOTHING;
`ifdef OR1200_MULT_IMPLEMENTED
`ifdef OR1200_MAC_IMPLEMENTED
`OR1200_OR32_MACMSB,
`OR1200_OR32_MACI,
`endif
`OR1200_OR32_MULI:
wait_on = `OR1200_WAIT_ON_MULTMAC;
`endif
`ifdef OR1200_MAC_IMPLEMENTED
`OR1200_OR32_MACRC:
wait_on = id_insn[16] ? `OR1200_WAIT_ON_MULTMAC :
`OR1200_WAIT_ON_NOTHING;
`endif
`ifdef OR1200_FPU_IMPLEMENTED
`OR1200_OR32_FLOAT: begin
wait_on = id_insn[`OR1200_FPUOP_DOUBLE_BIT] ? 0 : `OR1200_WAIT_ON_FPU;
end
`endif
`ifndef OR1200_DC_WRITEHROUGH
// l.mtspr
`OR1200_OR32_MTSPR: begin
wait_on = `OR1200_WAIT_ON_MTSPR;
end
`endif
default: begin
wait_on = `OR1200_WAIT_ON_NOTHING;
end
endcase // case (id_insn[31:26])
end
21》cust5_op,cust5_limm这两个信号是对cust5运算的操作码的解析
代码如下:
// // cust5_op, cust5_limm (L immediate) // assign cust5_op = ex_insn[4:0]; assign cust5_limm = ex_insn[10:5];
22》id_simm,ex_simm
id_simm是运算指令中的立即数的解析,ex_simm是id_simm的备份,供调试使用。
代码如下:
//
// EX Sign/Zero extension of immediates
//
always @(posedge clk or `OR1200_RST_EVENT rst) begin
if (rst == `OR1200_RST_VALUE)
ex_simm <= 32'h0000_0000;
else if (!ex_freeze) begin
ex_simm <= id_simm;
end
end
//
// ID Sign/Zero extension of immediate
//
always @(id_insn) begin
case (id_insn[31:26]) // synopsys parallel_case
// l.addi
`OR1200_OR32_ADDI:
id_simm = {{16{id_insn[15]}}, id_insn[15:0]};
// l.addic
`OR1200_OR32_ADDIC:
id_simm = {{16{id_insn[15]}}, id_insn[15:0]};
// l.lxx (load instructions)
`OR1200_OR32_LWZ, `OR1200_OR32_LBZ, `OR1200_OR32_LBS,
`OR1200_OR32_LHZ, `OR1200_OR32_LHS:
id_simm = {{16{id_insn[15]}}, id_insn[15:0]};
// l.muli
`ifdef OR1200_MULT_IMPLEMENTED
`OR1200_OR32_MULI:
id_simm = {{16{id_insn[15]}}, id_insn[15:0]};
`endif
// l.maci
`ifdef OR1200_MAC_IMPLEMENTED
`OR1200_OR32_MACI:
id_simm = {{16{id_insn[15]}}, id_insn[15:0]};
`endif
// l.mtspr
`OR1200_OR32_MTSPR:
id_simm = {16'b0, id_insn[25:21], id_insn[10:0]};
// l.sxx (store instructions)
`OR1200_OR32_SW, `OR1200_OR32_SH, `OR1200_OR32_SB:
id_simm = {{16{id_insn[25]}}, id_insn[25:21], id_insn[10:0]};
// l.xori
`OR1200_OR32_XORI:
id_simm = {{16{id_insn[15]}}, id_insn[15:0]};
// l.sfxxi (SFXX with immediate)
`OR1200_OR32_SFXXI:
id_simm = {{16{id_insn[15]}}, id_insn[15:0]};
// Instructions with no or zero extended immediate
default:
id_simm = {{16'b0}, id_insn[15:0]};
endcase
end
23》sig_syscall,对系统调用指令的解析
我们都知道,现在一般的CPU指令集中会设计专门设计OS系统调用的指令,以加快系统调用的执行速度。
代码如下:
//
// Decode of l.sys
//
always @(posedge clk or `OR1200_RST_EVENT rst) begin
if (rst == `OR1200_RST_VALUE)
sig_syscall <= 1'b0;
else if (!ex_freeze & id_freeze | ex_flushpipe)
sig_syscall <= 1'b0;
else if (!ex_freeze) begin
sig_syscall <= (id_insn[31:23] == {`OR1200_OR32_XSYNC, 3'b000});
end
end
24》sig_trap,陷入指令的解析
与系统调用功能类似,用来处理软中断,比如著名的0x80中断。
代码如下:
//
// Decode of l.trap
//
always @(posedge clk or `OR1200_RST_EVENT rst) begin
if (rst == `OR1200_RST_VALUE)
sig_trap <= 1'b0;
else if (!ex_freeze & id_freeze | ex_flushpipe)
sig_trap <= 1'b0;
else if (!ex_freeze) begin
sig_trap <= (id_insn[31:23] == {`OR1200_OR32_XSYNC, 3'b010})| du_hwbkpt;
end
end
25》force_dslot_fetch,no_more_dslot,延迟槽控制信号
代码如下:
// // Force fetch of delay slot instruction when jump/branch is preceeded by // load/store instructions // assign force_dslot_fetch = 1'b0; assign no_more_dslot = (|ex_branch_op & !id_void & ex_branch_taken) | (ex_branch_op == `OR1200_BRANCHOP_RFE);
26》对NOP指令的解析
对于NOP指令,判断当前的指令是否为NOP,产生标示三个信号给其它的流水阶段。
代码如下,需要说明的是wb-void信号并未引出来。
assign id_void = (id_insn[31:26] == `OR1200_OR32_NOP) & id_insn[16]; assign ex_void = (ex_insn[31:26] == `OR1200_OR32_NOP) & ex_insn[16]; assign wb_void = (wb_insn[31:26] == `OR1200_OR32_NOP) & wb_insn[16];
27》ex_spr_write,ex_spr_read产生对sprs的读写信号
代码如下:
assign ex_spr_write = spr_write && !abort_mvspr; assign ex_spr_read = spr_read && !abort_mvspr;
28》id_macrc_op,ex_macrc_op,ID阶段和EX阶段的mac运算的操作码解析
代码如下:
// // l.macrc in ID stage // `ifdef OR1200_MAC_IMPLEMENTED assign id_macrc_op = (id_insn[31:26] == `OR1200_OR32_MACRC) & id_insn[16]; `else assign id_macrc_op = 1'b0; `endif // // l.macrc in EX stage // `ifdef OR1200_MAC_IMPLEMENTED always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) ex_macrc_op <= 1'b0; else if (!ex_freeze & id_freeze | ex_flushpipe) ex_macrc_op <= 1'b0; else if (!ex_freeze) ex_macrc_op <= id_macrc_op; end `else assign ex_macrc_op = 1'b0; `endif
29》rfe,是异常返回指示信号
代码如下:
assign rfe = (id_branch_op == `OR1200_BRANCHOP_RFE) | (ex_branch_op == `OR1200_BRANCHOP_RFE);
这个信号送给了if模块,if模块的使用方法如下,如果是异常返回,并且之前保存过,则不用重新从cache里面取指了。
assign if_insn = no_more_dslot | rfe | if_bypass ? {`OR1200_OR32_NOP, 26'h041_0000} : saved ? insn_saved : icpu_ack_i ? icpu_dat_i : {`OR1200_OR32_NOP, 26'h061_0000};
30》except_illegal,非法指令异常信号
将当前指令和指令集中所有指令进行比较,如果不是,则拉高本信号。
代码如下:
//
// Decode of except_illegal
//
always @(posedge clk or `OR1200_RST_EVENT rst) begin
if (rst == `OR1200_RST_VALUE)
except_illegal <= 1'b0;
else if (!ex_freeze & id_freeze | ex_flushpipe)
except_illegal <= 1'b0;
else if (!ex_freeze) begin
case (id_insn[31:26]) // synopsys parallel_case
`OR1200_OR32_J,
`OR1200_OR32_JAL,
`OR1200_OR32_JALR,
`OR1200_OR32_JR,
`OR1200_OR32_BNF,
`OR1200_OR32_BF,
`OR1200_OR32_RFE,
`OR1200_OR32_MOVHI,
`OR1200_OR32_MFSPR,
`OR1200_OR32_XSYNC,
`ifdef OR1200_MAC_IMPLEMENTED
`OR1200_OR32_MACI,
`endif
`OR1200_OR32_LWZ,
`OR1200_OR32_LBZ,
`OR1200_OR32_LBS,
`OR1200_OR32_LHZ,
`OR1200_OR32_LHS,
`OR1200_OR32_ADDI,
`OR1200_OR32_ADDIC,
`OR1200_OR32_ANDI,
`OR1200_OR32_ORI,
`OR1200_OR32_XORI,
`ifdef OR1200_MULT_IMPLEMENTED
`OR1200_OR32_MULI,
`endif
`OR1200_OR32_SH_ROTI,
`OR1200_OR32_SFXXI,
`OR1200_OR32_MTSPR,
`ifdef OR1200_MAC_IMPLEMENTED
`OR1200_OR32_MACMSB,
`endif
`OR1200_OR32_SW,
`OR1200_OR32_SB,
`OR1200_OR32_SH,
`OR1200_OR32_SFXX,
`ifdef OR1200_IMPL_ALU_CUST5
`OR1200_OR32_CUST5,
`endif
`OR1200_OR32_NOP:
except_illegal <= 1'b0;
`ifdef OR1200_FPU_IMPLEMENTED
`OR1200_OR32_FLOAT:
// Check it's not a double precision instruction
except_illegal <= id_insn[`OR1200_FPUOP_DOUBLE_BIT];
`endif
`OR1200_OR32_ALU:
except_illegal <= 1'b0
`ifdef OR1200_MULT_IMPLEMENTED
`ifdef OR1200_DIV_IMPLEMENTED
`else
| (id_insn[4:0] == `OR1200_ALUOP_DIV)
| (id_insn[4:0] == `OR1200_ALUOP_DIVU)
`endif
`else
| (id_insn[4:0] == `OR1200_ALUOP_DIV)
| (id_insn[4:0] == `OR1200_ALUOP_DIVU)
| (id_insn[4:0] == `OR1200_ALUOP_MUL)
`endif
`ifdef OR1200_IMPL_ADDC
`else
| (id_insn[4:0] == `OR1200_ALUOP_ADDC)
`endif
`ifdef OR1200_IMPL_ALU_FFL1
`else
| (id_insn[4:0] == `OR1200_ALUOP_FFL1)
`endif
`ifdef OR1200_IMPL_ALU_ROTATE
`else
| ((id_insn[4:0] == `OR1200_ALUOP_SHROT) &
(id_insn[9:6] == `OR1200_SHROTOP_ROR))
`endif
`ifdef OR1200_IMPL_SUB
`else
| (id_insn[4:0] == `OR1200_ALUOP_SUB)
`endif
`ifdef OR1200_IMPL_ALU_EXT
`else
| (id_insn[4:0] == `OR1200_ALUOP_EXTHB)
| (id_insn[4:0] == `OR1200_ALUOP_EXTW)
`endif
;
// Illegal and OR1200 unsupported instructions
default:
except_illegal <= 1'b1;
endcase
end // if (!ex_freeze)
end
31》dc_no_writethrough
解析load/store指令中读写data cache的寄存器地址是来自r1(stack register)还是r2(frame pointer register)。
代码如下:
// Decode destination register address for data cache to check if store ops // are being done from the stack register (r1) or frame pointer register (r2) `ifdef OR1200_DC_NOSTACKWRITETHROUGH always @(posedge clk or `OR1200_RST_EVENT rst) begin if (rst == `OR1200_RST_VALUE) dc_no_writethrough <= 0; else if (!ex_freeze) dc_no_writethrough <= (id_insn[20:16] == 5'd1) | (id_insn[20:16] == 5'd2); end `else assign dc_no_writethrough = 0; `endif
3,小结
本小节我们分析了or1200的ID级的具体实现,至此,or1200的五级流水,我们已经分析了IF,ID,EX三级,还有MA和WB两级,那是future work了。
ctrl模块虽然看起来代码比较多,但内部却没有FSM,所以各个子模块都是相互独立的,所以没有想象的那么复杂。
enjoy!