HBase学习之一HBase本地模式与伪分布式模式
HBase是模仿Google的Bigtable开发的开源的、分布式的、面向列的存储仓库。就像Bigtable利用Google文件系统(GFS)提供的分布式数据存储,HBase基于Hadoop和HDFS提供了类似Bigtable的功能。当需要随机的、实时的读写大数据时,HBase就有了用武之地。
HBase有单机(本地)和分布式模式两种,而分布式模式又分为伪分布式和全分布是模式。单机模式是HBase的默认模式,该模式使用本地文件系统存储数据而不是基于HDFS。在该模式下,所有的HBase守护进程和一个本地ZooKeeper运行在同一个JVM中,Zookeeper通过绑定一个端口使得客户端可以与HBase通讯。伪分布式下的所有守护进程运行在单个节点上,而且既可以运行在本地文件系统也可以运行在Hadoop Distributed FileSystem (HDFS)上。而全分布式的守护进程则分布在集群中的所有节点上,并且只能运行在HDFS上。
在本地文件系统上运行HBase一般不能确保数据的持久性,要想确保数据都被保存下来,需要在HDFS上运行HBase。但是在本地文件系统上运行HBase 可以快速开始学习和熟悉HBase系统时如何运作的。
首先需要在HBase官方网站下载相对应的HBase版本,解压到指定的目录,假设为${HBASE_HOME}。在本地文件系统上以单机模式运行HBase非常简单,甚至不需要做任何修改就可以直接启动HBase,方法为运行${HBASE_HOME}/bin/start-hbase.sh,日志会记录在${HBASE_HOME}/logs目录中,可以通过查看日志文件确认HBase启动过程是否出现问题及是否启动成功。执行${HBASE_HOME}/bin/stop-hbase.sh可以停止HBase。默认情况下,HBase向目录/tmp/hbase-${user.name}中写数据,而ZooKeeper的数据写入/tmp/hbase-${user.name}/zookeeper中。可以修改${HBASE_HOME}/conf/hbase-site.xml文件,该文件初始不包含任何属性及属性值,可以通过设置特定属性值来覆盖默认值。比如上面提到的hbase和zookeeper的数据存放目录可以通过修改hbase.rootdir和hbase.zookeeper.property.dataDir属性值来改变。具体代码如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///DIRECTORY/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/DIRECTORY/zookeeper</value>
</property>
</configuration>
DIRECTORY为实际目录路径。
伪分布模式运行HBase在单个节点上,只能用来作为测试或者原型开发的目的,而不能用于生产或者测试HBase的性能。伪分布式即可以运行在本地文件系统上也可以运行在HDFS上(即使HDFS也以伪分布模式部署)。要想使HBase以伪分布或者全分布模式运行,必须修改hbase-site.xml文件的属性hbase.cluster.distributed为true以覆盖默认值false,false表示HBase以单机模式运行。修改的代码如下:
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
若伪分布模式下的HBase运行在本地文件系统之上(如何指定数据目录可参考上面内容),由于HBase使用Hadoop本地文件系统写数据到操作系统的本地文件系统,而Hadoop本地文件系统不支持同步,除非操作系统正常的关闭,否则会出现数据丢失的问题。若将HBase的数据按照默认方式保存在/tmp/hbase-${user.name},则由于大多数操作系统会定时清理/tmp/目录,还是会出现数据丢失的问题。为了数据的持久性,最好的办法是基于HDFS运行HBase,下面介绍如何进行这方面的配置。
修改hbase-site.xm文件内容如下,其中hdfs://hadoop:8020/hbase,其中hadoop为运行namenode的主机,8020为端口号,hbase为在HDFS上存放HBase数据的目录。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
完成上面的配置后,在启动HBase之前需要确保HDFS进程已经在运行,该进程可以通过脚本start-dfs.sh或者start-all.sh启动,后者还会启动jobtracker和tasktracker进程,而这两个进程不是HBase使用的,所以不是必须启动的。运行${HBASE_HOME}/bin/start-hbase.sh启动HBase,将会启动HMaster、HQuorumPeer、HRegionServer,可以通过使用命令jps或者查看${HBASE_HOME}/logs下的日志文件确认HBase启动成功。
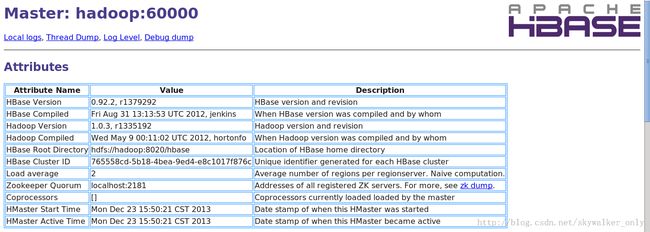
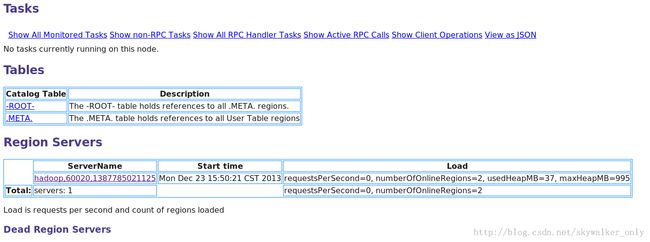
HBase也提供了UI界面访问HBase,可以查看HBase的启动时间、HBase的版本、HBase表、Region Servers等。默认是配置在主机点的60010端口上,可以在hbase-site.xml修改hbase.master.info.port属性值来改变端口或者-1以禁用UI。UI界面如下面的图片所示: