Tachyon 分布式内存文件系统
随着实时计算的需求日益增多,分布式内存计算也持续升温,怎样将海量数据近乎实时的处理,或者说怎么样把离线批处理的速度再提升到一个新的高度,是当前研究的重点。近年来,内存的吞吐量成指数倍的增长,而磁盘的吞吐量增长的缓慢,那么将原有计算框架中文件落地磁盘替换为文件落地内存,也是提高技术效率的优化点。
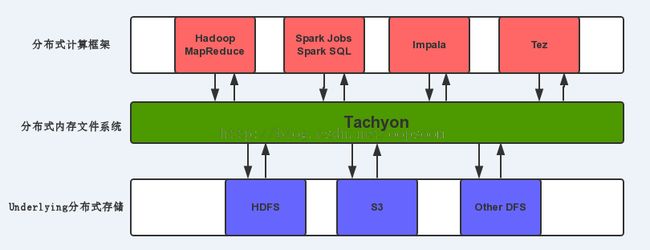
目前已经使用基于内存计算的分布式计算框架有:Spark,Impala以及SAP的HANA以及DBMS2。但是其中不乏有一些还是有文件落地磁盘的操作,如果能让这些落地磁盘的操作全部落地到一个共享的内存中,这些基于内存的计算框架效率会更高。
Tachyon是一个分布式内存文件系统,可以在集群里以访问内存的速度来访问存在tachyon里的文件。把Tachyon是架构在最底层的分布式文件存储和上层的各种计算框架之间的一种中间件。主要职责是将那些不需要落地到DFS里的文件,落地到分布式内存文件系统中,来达到共享内存,从而提高效率。同时可以减少内存冗余,GC时间等。。
一、Why Tachyon:
Tachyon能解决什么问题:
1、不同FrameWork之间共享内存数据Slow问题
给定一个场景,我的MapReduce任务的输出结果会存入到Tachyon里,Spark的Job会从Tachyon里读取MapReduce任务的输出作为输入。如果把Disk当作文件的落地,那么写的性能是十分低下。但是如果把Memory当作落地,写的性能是非常高的,fast write,以便Spark Job不会感觉到这是2个计算框架的操作,因为写和读的速度都非常快。同样的你可以用Impala的输出结果当作Spark的输入。
2、Spark的Executor Crash问题
我们知道Spark的执行引擎和存储引擎都是在Executor进程里。即在一个Executor内会有多个Task在运行,并且这个Executor的内也会放入cache的RDD们。
问题来了,一旦我的Executor挂了,那么Tasks会失败,并且这些cache的RDD的Block也会丢失,这就会有ReCompute的过程,重新去取数据,根据血缘关系递归的去计算丢失的数据,这当然会很耗费资源,而且性能低下。
3、内存冗余问题
这里说的内存冗余是说,Spark中不同Job之间可能同时读取了同一个文件,比如:job1和job2的计算任务都需要读取到账号信息表中的数据,那么我们都在他们各自的Executor里都cache了这一张账号表,是不是就出现了一个数据,2个内存副本,其实这样做是完全没有必要的,是冗余的。
4、GC时间过长
有时候影响程序执行的并不是代码本身,而是由于内存中存了太多的Java Objects,如果Executor这个Jvm里cache的对象太多,比如:达到80G UP,这个时候出现几次FULL GC,你就会很纳闷我的程序怎么不动了?你去看GC log,原来在GC。。。。
解决方案:
解决这几个问题的方案就是需要
一个共享的、Off-heap的分布式内存文件系统作为底层存储和计算框架直接的中间件
。
二、Tachyon架构
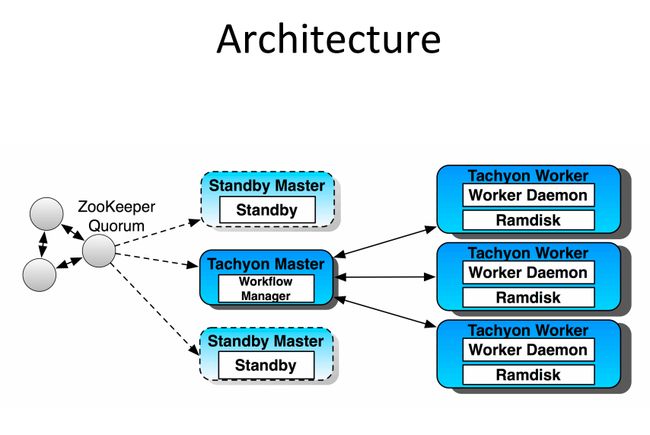
Tachyon的架构是传统的Master—slave架构,这里和Hadoop类似,TachyonMaster里WorkflowManager是Master进程,因为是为了防止单点问题,通过Zookeeper做了HA,可以部署多台Standby Master。Slave是由Worker Daemon和Ramdisk构成。这里个人理解只有Worker Daemon是基于JVM的,Ramdisk是一个off heap memory。Master和Worker直接的通讯协议是Thrift。
下图来自Tachyon的作者
Haoyuan Li:
三、Fault Tolerant
Tachyon是一个分布式文件存储系统,但是如果Tachyon里的容错机制是怎么样的呢?
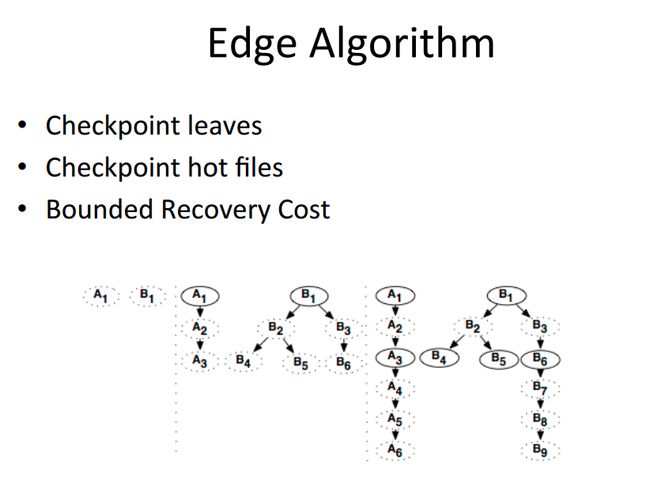
Tachyon使用血统这个我们在Spark里的RDD里已经很熟悉了,这里也有血统这一概念。会使用血统,通过异步的向Tachyon的底层文件系统做Checkpoint。
当我们向Tachyon里面写入文件的时候,Tachyon会在后台异步的把这个文件给checkpoint到它的底层存储,比如HDFS,S3.. etc...
这里用到了一个Edge的算法,来决定checkpoint的顺序。
比较好的策略是每次当前一个checkpoint完成之后,就会checkpoint一个最新生成的文件。当然想Hadoop,Hive这样的中间文件,需要删除的,是不需要checkpoint的。
下图来自Tachyon的作者
Haoyuan Li:
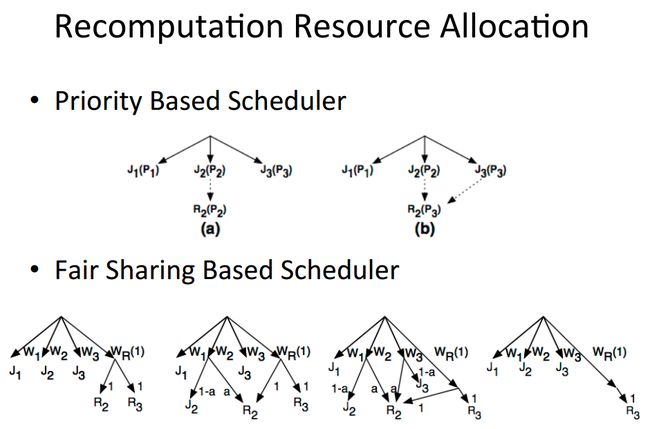
关于重新计算时,资源的分配策略:
目前Tachyon支持2种资源分配策略:
1、优先级的资源分配策略
2、公平调度的分配策略
四、总结
Tachyon是一个基于内存的分布式文件系统,通常位于分布式存储系统和计算框架直接,可以在不同框架内共享内存,同时可以减少内存冗余和基于Jvm内存计算框架的GC时间。
Tachyon也有类似RDD的血统概念,input文件和output文件都是会有血统关系,这样来达到容错。并且Tachyon也利用血统关系,异步的做checkpoint,文件丢失情况下,也能利用两种资源分配策略来优先计算丢失掉的资源。
参考文献: http://tachyon-project.org/index.html
http://goo.gl/DKrE4M
——EOF——
原创文章,转载请注明出自: http://blog.csdn.net/oopsoom/article/details/38438321