消息总线优化之PubSub
近段时间,暂缓了消息总线feature的开发,花了部分时间对原先的pubsub机制进行了针对性的优化与重构。这里记录一下优化的过程以及相比原来的设计有哪些改观。
PubSub在消息总线内部的作用
PubSub在消息总线内部主要用于对所有在线客户端进行实时管控的作用。每个客户端在使用消息总线时,都“被迫”注册到PubSub上,并“被迫”订阅了一些Channel,以便消息总线管控台实时下发一些管控指令及时生效。
之前的设计回顾
这里有必要回顾一下之前的设计。消息总线内部的Pub/Sub的机制是通过第三方技术组件的实现(目前支持Zookeeper跟Redis),关于Pub/Sub这里首先普及几个概念,首先组件根据自身业务定义Channel,某个组件如果需要关注某Channel的变更就注册对某Channel的关注(subscribe),当有组件因为业务需要向Channel发送变更(publish),凡是subscribe该Channel的所有组件都会获取到变更。这里因为Zookeeper跟Redis都支持数据存储,所以这里的publish的内容其实既可以被Push给subscribe该Channel的所有组件,也可以使得其他组件根据Channel pull下来。
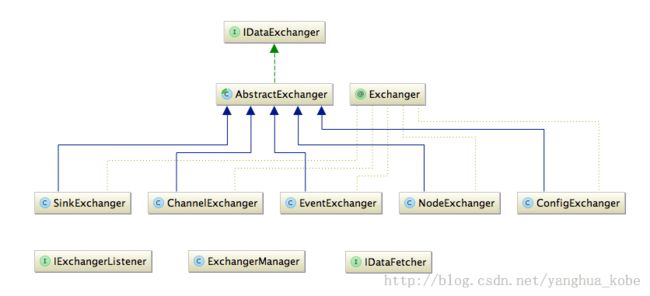
其实之前的做法的关注点在“自动化”以及“扩展性”。为了所谓的扩展性,我们利用Java注解扫描的方式来使得整个Channel的定义“自动化”,这样就无需硬编码了。并且当后续业务扩展,新增一个Channel的时候,之前Channel的定义无需作任何改变。另外为了客户端首次获取(目前的推送机制zookeeper以及redis都支持KV数据存储)以及后续更新推送数据的对客户端的一致性,我们让一个Channel对应数据库的一张表,同时每个Channel都对应自己的数据自动获取方式。
当然Pub/Sub从服务端角度来看是数据的上行(从数据库提取数据,push到subscribe的客户端),从客户端角度来看是数据的下行。因此这里我们定义了一个IDataExchange接口,用来与Pub/Sub组件进行数据交换: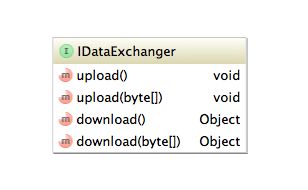
然后定义了一个@Exchanger注解,它包含两个属性:
- table:表示对应的表;
- path:也即channel,对应频道名称;
public interface IDataFetcher {
public byte[] fetchData(IDataConverter converter);
}
该接口接收一个数据序列化器,然后将获取到的数据进行序列化并以byte[]作为统一的返回值,因为需要将数据存储到Pub/Sub组件里去(它们大都支持字节数组的API接口)。
这样的设计对最初的关注点(自动化、扩展性、客户端首次获取数据以及后续获取变更数据导致代码处理上的一致性)而言,确实够了。但就性能而言,却非常低效。因为是一张表对应一个Channel,所以其实是全表推送,既然是全表推送,那么就无法鉴别客户端,无法鉴别客户端,就可能代码无效推送(跟某个客户端无关的关系数据,也会被推送过来),从而产生频繁推送,无效解析等一系列恶性循环。另外全表数据,相对来说是原始数据,还需要各个客户端做相应的解析,计算出合适的视图,用于内部控制以及权限校验等,并且所有的客户端在这一步执行的逻辑几乎是一样的。需要解析生成的视图如下:
private Map<String, Node> proconNodeMap;
private Map<String, Node> reqrespNodeMap;
private Map<String, Node> rpcReqRespNodeMap;
private Map<String, Node> pubsubNodeMap;
private Map<String, Node> idNodeMap;
private Map<String, Node> secretNodeMap;
private Map<String, Config> clientConfigMap;
private ExchangerManager exchangeManager;
private Map<String, Sink> tokenSinkMap;
private Map<String, String> pubsubChannelMap;
private Node notificationExchangeNode;
优化之后的设计
对于Pub/Sub重新设计之后采用——推拉结合的模式。不再推送数据,只推送变更通知以及变更的KEY(secret)。然后客户端按需拉取。
优化后的设计,带来如下一些优点:
减少客户端内存占用
之前Pub/Sub的设计是“首次拉取,变更全推”的做法。而且拉取的是全表数据,这对于客户端内存的占用是个极大的损耗。而优化之后,将只存储跟当前secret相关的数据视图。
服务端准备“数据视图”,减少客户端计算时间
优化之后针对客户端使用的数据专门定制了数据结构,在服务端按照键值对的形式计算出某个secret对应的客户端需要使用的视图数据并缓存在pub/sub组件的内存中。这个数据视图的数据结构如下:

这样,客户端在验证通信权限的时候,将会非常快。
减少远程访问通信开销
通信次数
减少通信次数的主要手段是本地缓存(local cache),客户端获取数据的方式是:如果本地有,则从本地取,如果本地没有,则从远端获取获取完之后缓存在本地内存里。部分代码如下所示:
public synchronized NodeView getNodeView(String secret) {
if (Strings.isNullOrEmpty(secret)) {
throw new NullPointerException("the secret can not be null or empty");
}
if (this.secretNodeViewMap.containsKey(secret)) { //local cache
return this.secretNodeViewMap.get(secret);
} else { //remote data then local cache
NodeView nodeViewObj = this.pubsuberManager.get(secret, NodeView.class);
this.secretNodeViewMap.put(secret, nodeViewObj);
return nodeViewObj;
}
}
当然通信次数的减少,还得益于特地为客户端定制的“数据视图”,并且是按照每个队列的secret拆分成key/value的。管控台导致的数据变更将过渡为变更通知事件,然后再按序更新本地缓存。而不会像原来那样,推送数据变更,从而导致太多无效网络交互以及数据计算。
通信数据量
减少通信数据量的主要手段是只获取有效数据,比如当调用消息总线API的时候,每个API都要求传入一个secret来指示当前对应的队列节点,因此我们只需要从远程获取客户端需要的跟当前secret相关的“数据视图”。当然这里我们作了一个假设:大部分场景下,一个客户端在某个JVM进程内通常只使用一个secret。因为API被设计为某个使用者只需要知道自己队列对应的secret即可使用,因此这样的假设是合理的。当然也不排除某个应用涉及到多个队列的操作,这种情况最多多获取几个secret的数据视图。但基本的原则是:不取多余数据,按需取用。并且,推送也从原来的数据变成了现在的变更通知,该通知虽然是广播式的,但却是“自认领”的机制:
public void onChannelDataChanged(String channel, Object obj) {
logger.debug("=-=-=-=-=-=- received change from channel : " + channel + " =-=-=-=-=-=-");
if (channel.equals(Constants.PUBSUB_NODEVIEW_CHANNEL)) {
String secret = obj.toString();
this.updateNodeView(secret);
} else if (channel.equals(Constants.PUBSUB_SERVER_STATE_CHANNEL)) {
String serverState = obj.toString();
this.setServerState(serverState);
} else if (channel.equals(Constants.PUBSUB_CONFIG_CHANNEL)) {
this.updateConfig(obj.toString());
} else if (channel.equals(Constants.PUBSUB_NOTIFICATION_EXCHANGE_CHANNEL)) {
this.updateNotificationNode();
}
}
拉取更新:
public synchronized void updateNodeView(String secret) {
if (this.secretNodeViewMap.containsKey(secret)) {
this.secretNodeViewMap.remove(secret);
this.getNodeView(secret);
}
}
可以看到,只有在推送的secret在本地有缓存时,才会去远端拉取更新。否则,将直接丢弃该变更通知。
取舍
当然,这种完全定制化的机制,也彻底废弃了之前关注的自动化以及扩展性的特性。这是必要的,因为我们队消息总线的定位还是希望它具有更好的性能。