车牌识别技术详解五--采用LBP+HOG SVM做目标分类,车牌检测,字符检测等
在样本数量比较少的情况下,可以采用HOG、SVM对样本进行初步的筛选出,正负样本,本文接着上一节二值化出来部分样本后,用pictureRelate做初步筛选出正负样本各500,准确训练。
1、pictureRelate使用http://www.walthelm.net/picture-relate/
可以用来比较图片的相似程度,或找出类似的图片文件的图像处理工具。在同一个视窗里浏览不同文件夹和硬盘驱动器中的图片文件#支持查看,改名,删除,剪贴,拖动,切换至文件管理器等操作#可处理多达50000多张图片!支持JPG, BMP, PNG, TIFF, PPM, PGM, PBM, RAS等格式#可以通过导入过滤命令行读取任何其它格式。
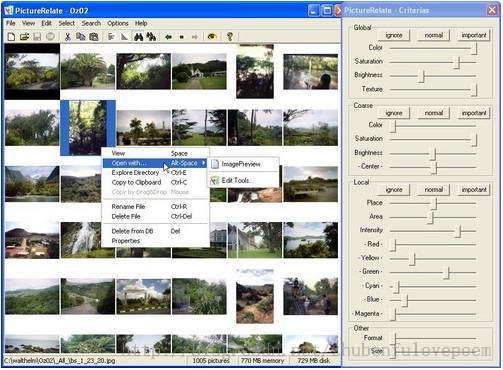
这里HOG LBP特征可以采用VLfeat(http://www.vlfeat.org/)这个开源库里面的特征,或者用OpenCV里面的也可以,分类器SVM采用的是OpenCV里面的。
2、下面介绍下VLfeat里面的HOG特征

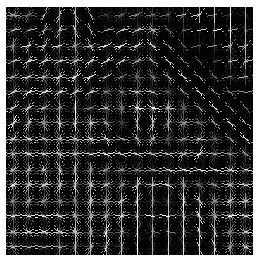
左图是原图,右图是HOG变化后的可视化效果。可以仔细对比,房子的轮廓还是可见的。
3、HOG+SVM训练目标检测的流程(OpenCV自带):
http://blog.csdn.net/carson2005/article/details/7841443
(1)准备训练样本集合;包括正样本集和负样本集;
(2)收集到足够的训练样本之后,你需要手动裁剪样本。例如,你想用Hog+SVM来对商业步行街的监控画面中进行行人检测,那么,你就应该用收集到的训练样本集合,手动裁剪画面中的行人(可以写个简单程序,只需要鼠标框选一下,就将框选区域保存下来--这一步在上一节有介绍)。
(3)裁剪得到训练样本之后,将所有正样本放在一个文件夹中;将所有负样本放在另一个文件夹中;并将所有训练样本缩放到同样的尺寸大小。本文是采用90*24的区域训练的。
(4)提取所有正样本的Hog特征;
(5)提取所有负样本的Hog特征;
(6)对所有正负样本赋予样本标签;例如,所有正样本标记为1,所有负样本标记为0;
(7)将正负样本的Hog特征,正负样本的标签,都输入到SVM中进行训练;Dalal在论文中考虑到速度问题,建议采用线性SVM进行训练。这里,不妨也采用线性SVM;
(8)SVM训练之后,将结果保存为文本文件。
(9)线性SVM进行训练之后得到的文本文件里面,有一个数组,叫做support vector,还有一个数组,叫做alpha,有一个浮点数,叫做rho;将alpha矩阵同support vector相乘,注意,alpha*supportVector,将得到一个列向量。之后,再该列向量的最后添加一个元素rho。如此,变得到了一个分类器,利用该分类器,直接替换opencv中行人检测默认的那个分类器(cv::HOGDescriptor::setSVMDetector()),就可以利用你的训练样本训练出来的分类器进行检测了。
效果显示:

JDI工作室主要从事视频图像处理,安防监控,机器视觉等项目开发,工作室成员都毕业与国内顶级高校,工作室现成员5个,其中2个专注于安防监控已有8年经验,3人专注于图像处理,应用开发2年。
JDI工作室的核心技术在于安防监控系统开发,实时高帧率视频采集,软件应用开发,图像视频处理与算法开发。从基于PC机器的开发到嵌入式开发,从android开发到Linux下的应用开发,从软件开发到硬件控制系统,从摄像头前段采集到处理到后端的识别等等,我们工作室都可以在较快的速度内实现并保质的完成,具体合作模式见附件开发合同,JDI工作室的所有开发严格按照合同执行,并提供2-6个月的软件后续维护和升级功能。
承接机器视觉检测,图像处理,OCR,车牌识别,人脸识别等等,各类项目开发。QQ:896922782
http://blog.csdn.net/zhubenfulovepoem/article/details/12343219