Shadow Caster Culling
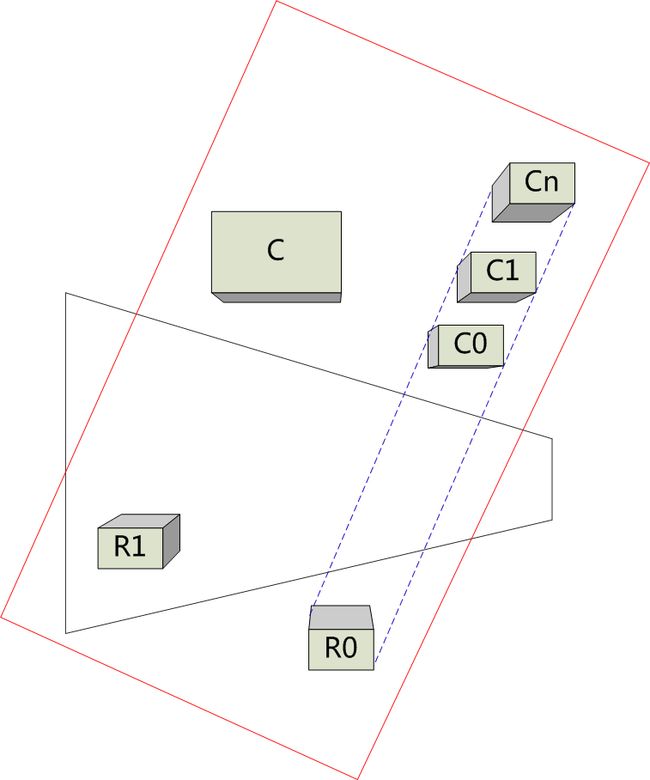
最近读到去年I3D上面的一篇论文,Shadow Caster Culling for Efficient Shadow Mapping,觉得不错,这里简单总结一下。对于算法的基本原理还是比较容易理解的,可以见下图所示。从图中可以看出对于当前某特定帧下的Camera来说,其可见的几何体元是整个场景的一个有限子集,而需要做阴影计算的也必然是这些可见几何体元集的一个子集,因而在生成Shadow Map时就可以只将那些对于当前需要计算SM的Shadow receiver有所影响的Shadow Caster投影绘制到SM中去(比如在下图所示中就可以只绘制C到SM中去,而C0,C1...Cn都是可省去的)。
这个算法的核心就是计算出这样一个优化的Caster集合来避免无谓的Caster绘制。算法的基本流程如下所列:
- 首先需要确定Shadow Receiver的集合
- 利用Receiver来创建Caster的Mask以供下一步Caster向SM中的渲染时使用
- 利用Caster Mask并结合Culling操作来进行高效的Caster渲染
- 常规的Shadow Mapping操作
其中最关键的就是第二步,即如何使用Receiver集合来创建Caster的Mask以供下一步阴影投射体的渲染时使用。这里的Mask其实也就是一张包含需要绘制的Caster的投影的Stencil Buffer或贴图,其使用原理与Occlusion Culling是一样的。这里的Receiver集合是对场景在当前Camera下进行裁剪的结果集,这也就要求引擎的裁剪系统有这么样的一个集合提取功能。关于Caster mask的生成文中给出了四种方法:
Bounding Volume Mask
这是一种最直接同时也最为保守的方法,直接使用几何体元的包围体来投影生成Mask。这里包围体的类型也就可以有多种选择,比如AABB,Sphere,OBB等,当然不同类型的包围盒对最终的精度也是会产生不同影响的。
Geometry Mask
这种方法在包围体的基本上进一步提高了精度,直接使用几何体元本身进行绘制来生成Mask。其相对于BVM来说精度提高了很多,但随之而来的问题就是渲染的效率,但是其也有另外的一个好处就是对于那些既是Caster又同时是Receiver的体元来说在生成Mask的同时就可以更新写入depth到SM中去,省去了下一步SM生成时的一些操作。
Geometry & Bounding Volume Mask
鉴于BVM与GM两者的优缺点,也可以将两者进行结合进行使用。这种方法需要将Reciver集合进行分类并从中提取出Receiver和Caster的交集,对于这些几何体使用GM的方法来操作,这样就避免了下一步SM中的depth写入;而对于其它的几何体则直接使用BVM的方法进行操作。这里对于需要使用Geometry Mask进行绘制的体元的判断采用了Temporal coherence的方法来实现,如果一个Receiver在上一帧的SM中可见那么在当前帧中将其视为既是Receiver&Caster,使用GM的方法来更新Mask。
Fragment Mask
在上述三种方法是最为精确的应该是Geometry Mask的方法了,但是其在某些情况下仍然会得到过于保守的Mask结果,这样就对后续的SM生成并没有多少效率上的提升,比较极端且典型的情况如下图所示:
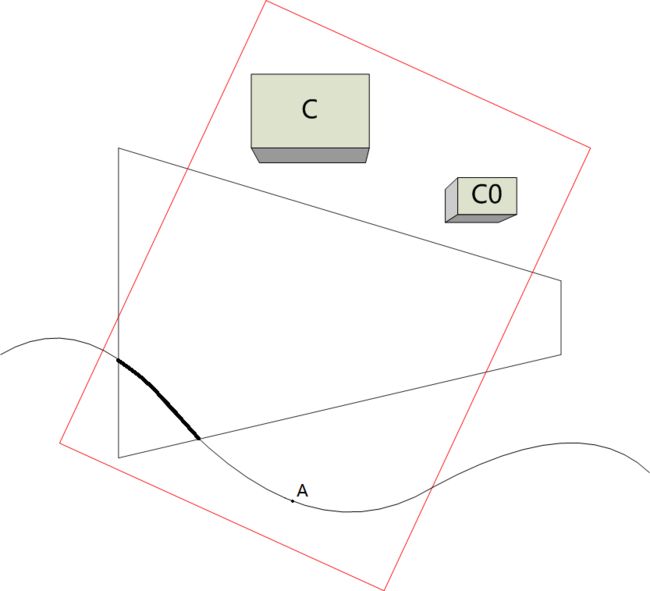
图中很大的曲面可能是场景中的一个较大的地形(整个地形属于一个单一的几何体元,也即上述的一个Geometry单位),在当前的Camera下,其可能只有很少一部分可见。但是这种情况下不管是BVM还是GM都需要将其完全绘制到Mask 中去,而由于其本身很大,所以可能直接将整个Mask填满,如此一来所有的Caster就都需要绘制,没有起到Caster culling的作用。此时更加精确的方法是提取出其中的Camera可见部分并将其写入到Mask中去。这里又有两种方法:
- 将较大的物体进行细分然后处理成多个独立的、较小的几何体元来进行操作。这样虽然不能达到完全精确,但却至少可以减少写入到Mask中的无用区域的范围以便提高下一步Caster culling的裁剪力度。
- 使用逐Pixel比较的操作来精确提取可见部分,这其实也相当于提前进行了一次Quasi Shadow Mapping的操作。比如对于上图中几何体元中的像素A,需要判断其是否是Camera中的Receiver点,这可能就需要记录一些当前Camera下的几何体元投影信息(如果有G-Buffer就可以直接使用),然后在Light Space中投影A到Camera space下并做一系列的判断得到结果。如果其是Receiver则将其更新到Mask中,若不是则丢弃之。如此一来就可以计算了精确的Mask。
上述几种方法中,最后一种方法虽然精度高但是操作起来较为复杂,而且对引擎的改动影响较大,最后得到的结果可能会得不偿失。个人觉得还是第三种方法比较实用些,如果现有的引擎中有比较完善的Culling系统的话那么其应用起来不是太复杂,而且性能应该有不错的提升。