memcached内存管理(1) ----------------slabs
slabs.{h,c}
slab的数据结构如下:
typedef struct {
unsigned int size; /* sizes of items 每个item的大小*/
unsigned int perslab; /* how many items per slab 每个slabs中能容纳多少个item*/
void *slots; /* list of item ptrs 空闲列表*/
unsigned int sl_curr; /* total free items in list 空闲列表空闲item个数*/
unsigned int slabs; /* how many slabs were allocated for this class 已经分配来多少个slabs*/
void **slab_list; /* array of slab pointers 指向一个void *数组,该数组指向实际分配的内存*/
unsigned int list_size; /* size of prev array 最大允许slabs个数*/
unsigned int killing; /* index+1 of dying slab, or zero if none */
size_t requested; /* The number of requested bytes 这个slabclass中已经分配使用了多少bytes的内存*/
} slabclass_t;
s
下面是网上找的一张图,从上面字段可以看出,已经没有来end_page_ptr这个指针
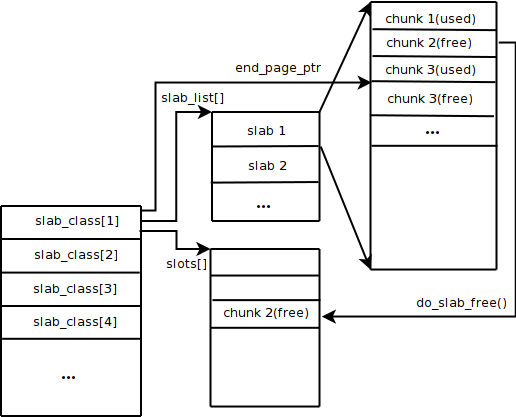
slabs.c中几个重要的全局变量
static slabclass_t slabclass[MAX_NUMBER_OF_SLAB_CLASSES]; //slabs数组 static size_t mem_limit = 0; //最大的内存使用,超过就不分配内存 static size_t mem_malloced = 0; //当前已经从系统分配来多少内存
下面看几个主要的函数
init函数
/**
* Determines the chunk sizes and initializes the slab class descriptors
* accordingly.
*/
void slabs_init(const size_t limit, const double factor, const bool prealloc) {
int i = POWER_SMALLEST - 1;
unsigned int size = sizeof(item) + settings.chunk_size;
mem_limit = limit;
memset(slabclass, 0, sizeof(slabclass));
while (++i < POWER_LARGEST && size <= settings.item_size_max / factor) {
/* Make sure items are always n-byte aligned */
if (size % CHUNK_ALIGN_BYTES)
size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES);
slabclass[i].size = size;
slabclass[i].perslab = settings.item_size_max / slabclass[i].size;
size *= factor;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
}
power_largest = i;
slabclass[power_largest].size = settings.item_size_max;
slabclass[power_largest].perslab = 1;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
/* for the test suite: faking of how much we've already malloc'd */
{
char *t_initial_malloc = getenv("T_MEMD_INITIAL_MALLOC");
if (t_initial_malloc) {
mem_malloced = (size_t)atol(t_initial_malloc);
}
}
}
为了不影响看主要的逻辑,我已经将prealloc(预分配)部分的代码删除了。
limit是最大允许分配的空间,factor是增长因子,即每个slabclass的item size比上一个大 factor倍,不考虑对齐的话。
初始值
unsigned int size = sizeof(item) + settings.chunk_size;item是个struct稍后看item的时候再解释,主要是作为链表元素使用,同时放实际的数据。
init函数主要就是设置来mem_limit, 每个slabclass的item大小和item数量,这里并没有使用prealloc,所有没有分配内存,每个slabclass的list_size和sl_curr都为0
alloc函数:
在slabclass[id]上分配size个字节
void *slabs_alloc(size_t size, unsigned int id) {
void *ret;
pthread_mutex_lock(&slabs_lock);
ret = do_slabs_alloc(size, id);
pthread_mutex_unlock(&slabs_lock);
return ret;
}
直接调用的do_slabs_alloc函数,是do_slabs_alloc的线程安全版吧,因为它操作的slabclass ,mem_limit都是全局static的变量
static void *do_slabs_alloc(const size_t size, unsigned int id) {
slabclass_t *p;
void *ret = NULL;
item *it = NULL;
//确保id在有效范围
if (id < POWER_SMALLEST || id > power_largest) {
MEMCACHED_SLABS_ALLOCATE_FAILED(size, 0);
return NULL;
}
p = &slabclass[id];
assert(p->sl_curr == 0 || ((item *)p->slots)->slabs_clsid == 0); //要么sl_curr空闲列表为空,不为空时slots指向的头一个item的cslid值必须为0
/* fail unless we have space at the end of a recently allocated page,
we have something on our freelist, or we could allocate a new page */
//如果空闲列表不为空,直接从空闲列表中分配
//如果空闲列表为空,则do_slabs_newslab来增加该slabclass的slabs
// 如果do_slabs_newslab失败则返回null
if (! (p->sl_curr != 0 || do_slabs_newslab(id) != 0)) {
/* We don't have more memory available */
ret = NULL;
} else if (p->sl_curr != 0) {
/* return off our freelist */
//返回slots,slots指向下一个item
it = (item *)p->slots;
p->slots = it->next;
if (it->next) it->next->prev = 0;
p->sl_curr--;
ret = (void *)it;
}
if (ret) {
p->requested += size;
MEMCACHED_SLABS_ALLOCATE(size, id, p->size, ret);
} else {
MEMCACHED_SLABS_ALLOCATE_FAILED(size, id);
}
return ret;
}函数的逻辑在代码注释中也解释得差不多,就是返回slots指向的item,并使slots指向下一个item,,可以看出其实slots指向的是一个item为元素的双向链表
如果slots为空,则需要调用do_slabs_newslab来分配一个新的slab
static int do_slabs_newslab(const unsigned int id) {
slabclass_t *p = &slabclass[id];
int len = settings.slab_reassign ? settings.item_size_max
: p->size * p->perslab;
char *ptr;
//成功:如果没有超出mem_limit,并且grow_slab_list返回1,则调用memory_allocate分配内存
//其余情况似失败,返回0
if ((mem_limit && mem_malloced + len > mem_limit && p->slabs > 0) ||
(grow_slab_list(id) == 0) ||
((ptr = memory_allocate((size_t)len)) == 0)) {
MEMCACHED_SLABS_SLABCLASS_ALLOCATE_FAILED(id);
return 0;
}
//将新分配的内存全部置0,通过split_slab_page_into_freelist,将新分配的内存放到slots中
//这就是为什么取消来end_page_ptr的原因了
memset(ptr, 0, (size_t)len);
split_slab_page_into_freelist(ptr, id);
//slabs加1
p->slab_list[p->slabs++] = ptr;
mem_malloced += len;
MEMCACHED_SLABS_SLABCLASS_ALLOCATE(id);
return 1;
}
再看看grow_slab_list
static int grow_slab_list (const unsigned int id) {
slabclass_t *p = &slabclass[id];
//slabs == list_size表明已经到了分配的最大slabs个数来,需要realloc来重新分配空间
if (p->slabs == p->list_size) {
//*2倍增长,初始为16
//即初始时,slab_list指向一个函数16个void *的数组
size_t new_size = (p->list_size != 0) ? p->list_size * 2 : 16;
void *new_list = realloc(p->slab_list, new_size * sizeof(void *));
if (new_list == 0) return 0;
p->list_size = new_size;
p->slab_list = new_list;
}
return 1;
}
1表示成功,0表示重新分配slab_list指向的void *数组失败,则list_size不能增长。这个分配的是指向实际chunk块的void *数组(slabs),并不是真正分配供item使用的内存的地方。可以参考上面的图片。
memory_allocate这个函数最简单来,就是调用malloc来分配内存
static void *memory_allocate(size_t size) {
void *ret;
if (mem_base == NULL) {
/* We are not using a preallocated large memory chunk */
ret = malloc(size);
} else {
ret = mem_current;
if (size > mem_avail) {
return NULL;
}
/* mem_current pointer _must_ be aligned!!! */
if (size % CHUNK_ALIGN_BYTES) {
size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES);
}
mem_current = ((char*)mem_current) + size;
if (size < mem_avail) {
mem_avail -= size;
} else {
mem_avail = 0;
}
}
return ret;
}
没有prealloc的情况下,实际执行的只是
ret = malloc(size); return ret;
分配的最后一个函数,将新分配的内存直接放到slots中
static void split_slab_page_into_freelist(char *ptr, const unsigned int id) {
slabclass_t *p = &slabclass[id];
int x;
for (x = 0; x < p->perslab; x++) {
do_slabs_free(ptr, 0, id);
ptr += p->size;
}
}
就是每p->size个字节为一个item放到slots中,通过调用do_slabs_free来实现。这个函数在后面解释。
到此为止,slab分配全部完成。
free函数
free并不是将内存返回给系统,而是将不使用的item占用的空间重新放到相对应的slabclass的slots中
/** Free previously allocated object */
void slabs_free(void *ptr, size_t size, unsigned int id) {
pthread_mutex_lock(&slabs_lock);
do_slabs_free(ptr, size, id);
pthread_mutex_unlock(&slabs_lock);
}
跟slabs_alloc一样,调用do_slabs_free来完成,是线程安全的。
static void do_slabs_free(void *ptr, const size_t size, unsigned int id) {
slabclass_t *p;
item *it;
assert(((item *)ptr)->slabs_clsid == 0);
assert(id >= POWER_SMALLEST && id <= power_largest);
if (id < POWER_SMALLEST || id > power_largest)
return;
MEMCACHED_SLABS_FREE(size, id, ptr);
p = &slabclass[id];
it = (item *)ptr;
it->it_flags |= ITEM_SLABBED;
it->prev = 0;
it->next = p->slots;
if (it->next) it->next->prev = it;
p->slots = it;
p->sl_curr++;
p->requested -= size;
return;
}
可以看出,是将ptr指向的内存空间加到slots的头,slots指向这个ptr,即ptr变成slots的头item。修改相应的属性如iitem->it_flags |= ITEM_SLABBED
sl_curr加1等。
这就是大概memcached的内存池吧。