【网络挖掘:成就与未来方向】之网络结构挖掘
四、网络结构挖掘(Web Structure Mining)
1、定义
一个典型的网络图形结构是把网页作为节点,把链接两个相关网页的超链接作为边。
网络结构挖掘是从网络中发现结构信息的过程。
这种挖掘可以在文档级别(页内)也可以在超链接级别(页间)。
超链接级别的研究也叫做超链接分析(HyperlinkAnalysis)。
研究超链接结构的动机(Motivation):
超链接有两个主要目的——纯粹的导航和指向与页面拥有同一主题的权威页面。
可以用来检索网络中有用的信息。
2、网络结构术语(Web Structure Terminology)
网络图(Web-graph):表示网络的有向图。
节点(Node):每个网页都是网络图的一个节点。
链接(Link):网络上的每个超链接都是网络图中的一个有向边。
入度(In-degree):节点p的入度是指向p的不同链接的数量。
出度(Out-degree):节点p的出度是p指向其他节点的不同超链接的数目。
有向路径(Directed Path):从节点p到q的可跟踪的一个链接序列。
最短路径(Shortest Path):在节点p到q的所有路径中拥有最短长度的路径,如链接的数量最少。
直径(Diameter):网络图中任意两个节点p和q之间的所有最短路径中的最大值。
3、感兴趣的网络结构(Interesting Web Structures[ERC+2000])
蝴蝶结网络结构(The Bow-TieModel of the Web [BKM+2000])

4、超链接分析技术(Hyperlink Analysis Techniques[DSKT2002])
1)知识模型(Knowledge Models):这种低层的表示是进行应用程序特定任务的基础。
2)分析范围和性质(Analysis Scope and Properties):分析范围表明任务是与一个节点还是一组节点还是整个图有关;性质是一个节点或一组节点或整个网络的特征。
3)措施与算法(Measures and Algorithms):措施是性质的标准,如质量、节点间相关性或距离;算法是这些措施的有效计算。
这三个方面构成了建立基于超链接分析的应用程序(Application)的基础。

5、主要概念
1)Google的PageRank[BP1998]
核心思想:一个网页的排名依赖于指向它的网页的排名。

算法:

2)Hubs andAuthorities [K1998]
核心思想:一个好的hub页面指向很多好的Authority页面,一个好的Authority页面被很多好的hub页面指向。
算法:

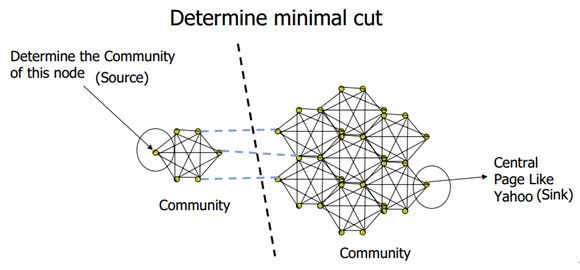
3)网络社区(WebCommunities [FLG2000])
定义:网络社区可以被描述为一个网页集合,集合内部的每一个网页在社区内比社区外有更多的超链接(不管是链入的还是链出的)。
方法:最大流模型(Maximal-flowModel),图子结构识别(GraphSubstructure Identification)。
最大流最小分割算法(Max Flow- MinCut Algorithm):
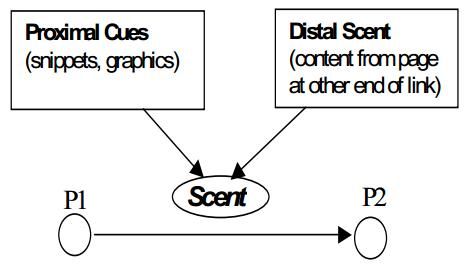
4)信息线索(InformationScent [CPCP2001])
核心思想:一个用户在“觅食(foraging)”信息的时候会“闻到(smell)”那种信息,跟踪链接的可能性取决于那个链接的“气味(scent)”的强度。
6、结论(Conclusions)
网络结构是抽取信息的有用来源。这些信息包括:
1)网页质量(Quality of Web Page)——页面关于某个主题的权威性,网页的排名;
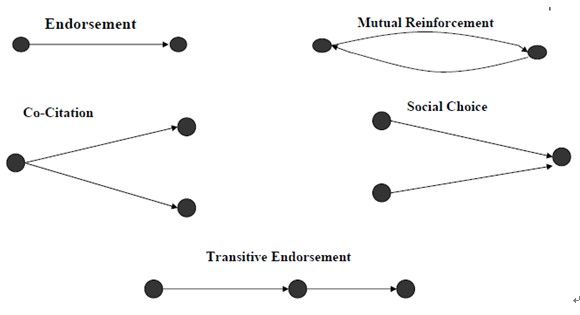
2)感兴趣的网络结构(Interesting Web Structures)——像共引用(Co-citation)、社会选择(SocialChoice)、完全二分图(Completebipartite graphs)等图模式;
3)网页分类(Web Page Classification)——根据不同主题对网页进行分类;
4)爬行哪个网页(Which pages to crawl)——决定把哪些网页添加到网页集合中;
5)找到相关页面(Finding Related Pages)——给定一个页面,找到所有相关页面;
6)检测重复页面(Detection of duplicated pages)——检测同镜像网站以消除重复。
翻译有不当之处,敬请指正!原文地址:http://www.ieee.org.ar/downloads/Srivastava-tut-pres.pdf