Spark修炼之道(进阶篇)——Spark入门到精通:第二节 Hadoop、Spark生成圈简介
作者:周志湖
网名:摇摆少年梦
微信号:zhouzhihubeyond
本节主要内容
- Hadoop生态圈
- Spark生态圈
1. Hadoop生态圈
原文地址:http://os.51cto.com/art/201508/487936_all.htm#rd?sukey=a805c0b270074a064cd1c1c9a73c1dcc953928bfe4a56cc94d6f67793fa02b3b983df6df92dc418df5a1083411b53325
下图给出了Hadoop生态圈中的重要产品:
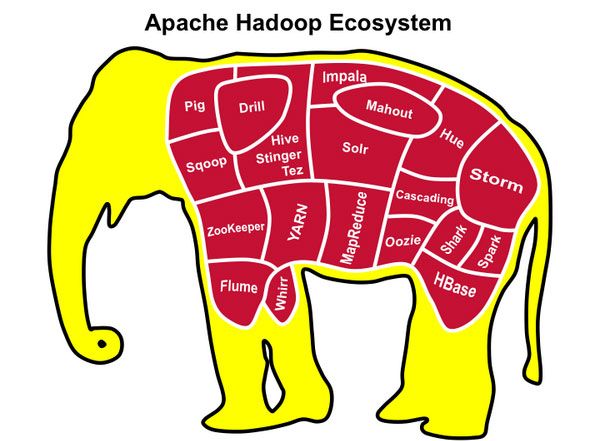
图片来源:http://www.36dsj.com/archives/26942
下面对各产品进行简要介绍
1 Hadoop
Apache的Hadoop项目已几乎与大数据划上了等号。它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算。
支持的操作系统:Windows、Linux和OS X。
相关链接:http://hadoop.apache.org
2 Ambari
作为Hadoop生态系统的一部分,这个Apache项目提供了基于Web的直观界面,可用于配置、管理和监控Hadoop集群。有些开发人员想把Ambari的功能整合到自己的应用程序当中,Ambari也为他们提供了充分利用REST(代表性状态传输协议)的API。
支持的操作系统:Windows、Linux和OS X。
相关链接:http://ambari.apache.org
3 Avro
这个Apache项目提供了数据序列化系统,拥有丰富的数据结构和紧凑格式。模式用JSON来定义,它很容易与动态语言整合起来。
支持的操作系统:与操作系统无关。
相关链接:http://avro.apache.org
4 Cascading
Cascading是一款基于Hadoop的应用程序开发平台。提供商业支持和培训服务。
支持的操作系统:与操作系统无关。
相关链接:http://www.cascading.org/projects/cascading/
5 Chukwa
Chukwa基于Hadoop,可以收集来自大型分布式系统的数据,用于监控。它还含有用于分析和显示数据的工具。
支持的操作系统:Linux和OS X。
相关链接:http://chukwa.apache.org
6 Flume
Flume可以从其他应用程序收集日志数据,然后将这些数据送入到Hadoop。官方网站声称:“它功能强大、具有容错性,还拥有可以调整优化的可靠性机制和许多故障切换及恢复机制。”
支持的操作系统:Linux和OS X。
相关链接:https://cwiki.apache.org/confluence/display/FLUME/Home
7 HBase
HBase是为有数十亿行和数百万列的超大表设计的,这是一种分布式数据库,可以对大数据进行随机性的实时读取/写入访问。它有点类似谷歌的Bigtable,不过基于Hadoop和Hadoop分布式文件系统(HDFS)而建。
支持的操作系统:与操作系统无关。
相关链接:http://hbase.apache.org
8 Hadoop分布式文件系统(HDFS)
HDFS是面向Hadoop的文件系统,不过它也可以用作一种独立的分布式文件系统。它基于Java,具有容错性、高度扩展性和高度配置性。
支持的操作系统:Windows、Linux和OS X。
相关链接:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
9 Hive
Apache Hive是面向Hadoop生态系统的数据仓库。它让用户可以使用HiveQL查询和管理大数据,这是一种类似SQL的语言。
支持的操作系统:与操作系统无关。
相关链接:http://hive.apache.org
10 Hivemall
Hivemall结合了面向Hive的多种机器学习算法。它包括诸多高度扩展性算法,可用于数据分类、递归、推荐、k最近邻、异常检测和特征哈希。
支持的操作系统:与操作系统无关。
相关链接:https://github.com/myui/hivemall
11 Mahout
据官方网站声称,Mahout项目的目的是“为迅速构建可扩展、高性能的机器学习应用程序打造一个环境。”它包括用于在Hadoop MapReduce上进行数据挖掘的众多算法,还包括一些面向Scala和Spark环境的新颖算法。
支持的操作系统:与操作系统无关。
相关链接:http://mahout.apache.org
12 MapReduce
作为Hadoop一个不可或缺的部分,MapReduce这种编程模型为处理大型分布式数据集提供了一种方法。它最初是由谷歌开发的,但现在也被本文介绍的另外几个大数据工具所使用,包括CouchDB、MongoDB和Riak。
支持的操作系统:与操作系统无关。
相关链接:http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
13 Oozie
这种工作流程调度工具是为了管理Hadoop任务而专门设计的。它能够按照时间或按照数据可用情况触发任务,并与MapReduce、Pig、Hive、Sqoop及其他许多相关工具整合起来。
支持的操作系统:Linux和OS X。
相关链接:http://oozie.apache.org
14 Pig
Apache Pig是一种面向分布式大数据分析的平台。它依赖一种名为Pig Latin的编程语言,拥有简化的并行编程、优化和可扩展性等优点。
支持的操作系统:与操作系统无关。
相关链接:http://pig.apache.org
- Sqoop
企业经常需要在关系数据库与Hadoop之间传输数据,而Sqoop就是能完成这项任务的一款工具。它可以将数据导入到Hive或HBase,并从Hadoop导出到关系数据库管理系统(RDBMS)。
支持的操作系统:与操作系统无关。
相关链接:http://sqoop.apache.org
- Spark
作为MapReduce之外的一种选择,Spark是一种数据处理引擎。它声称,用在内存中时,其速度比MapReduce最多快100倍;用在磁盘上时,其速度比MapReduce最多快10倍。它可以与Hadoop和Apache Mesos一起使用,也可以独立使用。
支持的操作系统:Windows、Linux和OS X。
相关链接:http://spark.apache.org
- Tez
Tez建立在Apache Hadoop YARN的基础上,这是“一种应用程序框架,允许为任务构建一种复杂的有向无环图,以便处理数据。”它让Hive和Pig可以简化复杂的任务,而这些任务原本需要多个步骤才能完成。
支持的操作系统:Windows、Linux和OS X。
相关链接:http://tez.apache.org
- Zookeeper
这种大数据管理工具自称是“一项集中式服务,可用于维护配置信息、命名、提供分布式同步以及提供群组服务。”它让Hadoop集群里面的节点可以彼此协调。
支持的操作系统:Linux、Windows(只适合开发环境)和OS X(只适合开发环境)。
相关链接:http://zookeeper.apache.org
2. Spark 生态圈
Hadoop将Spark作为自己生态圈的一部分,但Spark完全可以脱离Hadoop平台,不单依赖于HDFS、Yarn,例如它可以使用Standalone、Mesos进行集群资源管理,它的包容性使得Spark拥有众多的源码贡献者和使用者,其生态系统也日益繁荣。Spark官方组件如图所示。
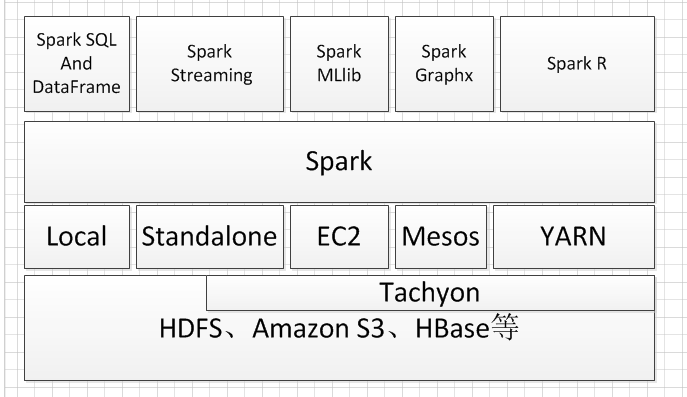
Spark SQL And DataFrame
Spark SQL用于对结构化数据进行处理,它提供了DataFrame的抽象,作为分布式平台数据查询引擎,可以在此组件上构建大数据仓库。DataFrame是一个分布式数据集,在概念上类似于传统数据库的表结构,数据被组织成命名的列,DataFrame的数据源可以是结构化的数据文件,也可以是Hive中的表或外部数据库,也还可以以是现有的RDD。Spark Streaming.
Spark Streaming用于进行实时流数据的处理,它具有高扩展、高吞吐率及容错机制,数据来源可以是 Kafka, Flume, Twitter, ZeroMQ, Kinesis或TCP,其操作依赖于discretized stream(DStream),Dstream可以看作是多个有序的RDD组成,因此它也只通过map, reduce, join and window等操作便可完成实时数据处理,另外一个非常重要的点便是,Spark Streaming可以与Spark MLlib、Graphx等结合起来使用,功能十分强大,似乎无所不能。

3 Spark Machine Learning
Spark集成了MLLib库,其分布式数据结构也是基于RDD的,与其它组件能够互通,极大地降低了机器学习的门槛,特别是分布式环境下的机器学习。目前Spark MLlib支持下列几种机器学习算法:
(1 ) classification(分类)与 regression(回归)
目前实现的算法主要有:linear models (SVMs, logistic regression, linear regression)、naive Bayes(朴素贝叶斯)、decision trees(决策树)、ensembles of trees (Random Forests and Gradient-Boosted Trees)(组合模型树)、isotonic regression(保序回归)
(2) clustering(聚类)
目前实现的算法有:k-means、Gaussian mixture、power iteration clustering (PIC)、latent Dirichlet allocation (LDA)、streaming k-means
(3) collaborative filtering(协同过滤)
目前实现的算法只有:alternating least squares (ALS)
(4) dimensionality reduction(特征降维)
singular value decomposition (奇异值分解,SVD)
principal component analysis (主成分分析,PCA)
除上述机器学习算法之外,还包括一些统计相关算法、特征提取及数值计算等算法。Spark 从1.2版本之后,机器学习库作了比较大的发动,Spark机器学习分为两个包,分别是mllib和ml,ML把整体机器学习过程抽象成Pipeline(流水线),避免机器学习工程师在训练模型之前花费大量时间在特征抽取、转换等准备工作上。
4 Spark GraphX
Graphx是Spark专门用来进行分布式图计算,Graph的抽象也是通过扩展Spark RDD实现,提供subgraph, joinVertices及aggregateMessages等基础的图操作。
5 SparkR
R语言在数据分析领域内应用十分广泛,但以前只能在单机环境上使用,Spark R的出现使得R摆脱单机运行的命运,将大量的数据工程师可以以非常小的成本进行分布式环境下的数据分析。 Spark R提供了RDD的API,R语言工程师可以通过R Shell进行任何的提交。
目前其它比较著名的Spark 生态圈产品包括(参见http://spark-packages.org/):
1 Astro
华为开源的Spark SQL on HBase package。Spark SQL on HBase package项目又名Astro,端到端整合了Spark,Spark SQL和HBase的能力,有助于推动帮助Spark进入NoSQL的广泛客户群,并提供强大的在线查询和分析以及在垂直企业大规模数据处理能力。见http://www.ctiforum.com/news/guonei/458028.html
2 Apache Zeppelin
开源的基于Spark的Web交互式数据分析平台,它具有如下特点:
(1)自动流入SparkContext and SQLContext
(2) 运行时加载jar包依赖
(3) 停止job或动态显示job进度
最主要的功能包括: Data Ingestion、Data Discovery、Data Analytics、Data Visualization & Collaboration
目前Zeppelin还只是孵化项目,但我相信未来它一定有广阔的前景,参见http://zeppelin.incubator.apache.org/
3 Apache Pig on Apache Spark(Spork)
这个很容易理解,具体参见http://blog.cloudera.com/blog/2014/09/pig-is-flying-apache-pig-on-apache-spark/
更多Spark 生态圈产品参见http://spark-packages.org/
添加公众微信号,可以了解更多最新Spark、Scala相关技术资讯
