mahout in Action2.2-给用户推荐图书(1)-直观分析和代码
This chapter covers
What recommenders are, within Mahout
A first look at a recommender in action
Evaluating the accuracy and quality of
recommender engines
Evaluating a recommender on a real
data set: GroupLens
1.mahout in Action2.2第一个例子
Running a first recommender engine
数据:
第一个数字是用户ID 第二个是书的ID,第三个是用户对书的评分,1-5 越高,表示用户越喜欢
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
1-5 用户对不同书的喜好程度如下图所示:
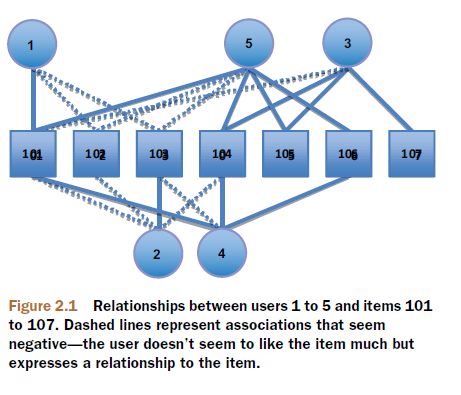
直觉上看这个图,用户1和用户5喜好很相似,都喜欢101,对102,103只是喜欢那么一点点。可以说非常相似。1和4其次,也很相似,都很喜欢101,不怎么喜欢103。
1和2的喜好貌似完全相反,1喜欢101,而2不喜欢。等等。。。
那么。考察用户1,我们推荐什么书给他呢?
101 102 103他已经知道了,在剩下的书中,我们选取哪几个呢?直觉告诉我们,1和4,5号用户很相似,因此,我们应该用4.5的喜好推测1的喜好,进行推荐。那么4,5都很喜欢104,106,我们就应该推荐这两本书给1.
人的内心是这么思考的,代码怎么表示出来呢?
publicstaticvoid main(String[] args)throwsException{File modelFile =null;if(args.length >0)modelFile =newFile(args[0]);if(modelFile ==null||!modelFile.exists())modelFile =newFile("intro.csv");加载文件if(!modelFile.exists()){System.err.println("Please, specify name of file, or put file 'input.csv' into current directory!");System.exit(1);}DataModel model =newFileDataModel(modelFile);UserSimilarity similarity =newPearsonCorrelationSimilarity(model);UserNeighborhood neighborhood =newNearestNUserNeighborhood(2, similarity, model);Recommender recommender =newGenericUserBasedRecommender(model, neighborhood, similarity);List<RecommendedItem> recommendations =recommender.recommend(1,1);推荐,对于用户1 推荐一个for(RecommendedItem recommendation : recommendations){System.out.println(recommendation);}}
程序输出:
RecommendedItem [item:104, value:4.257081]
结果说明 推荐104 因为相应的评分为4.25
下一章节讲述怎么评价这个结果,这个和我们做生物研究实验一样,就是检验自己的结果的可信性。如果检验可信度高,就可以认为我们的理论是正确的。我们生物经常用到的是T检验,K检验等等,都是经典的理论。
Charles 于2015-12-17 Phnom Penh
版权说明:
本文由Charles Dong原创,本人支持开源以及免费有益的传播,反对商业化谋利。
CSDN博客:http://blog.csdn.net/mrcharles
个人站:http://blog.xingbod.cn
EMAIL:[email protected]