sparkSQL1.1入门之三:sparkSQL组件之解析
- 概念:
- LogicalPlan
- 组件:
- SqlParser
- Analyzer
- Optimizer
- Planner
在LogicalPlan里维护者一套统计数据和属性数据,也提供了解析方法。同时延伸了三种类型的LogicalPlan:abstract class LogicalPlan extends QueryPlan[LogicalPlan] { self: Product => case class Statistics( sizeInBytes: BigInt ) lazy val statistics: Statistics = { if (children.size == 0) { throw new UnsupportedOperationException(s"LeafNode $nodeName must implement statistics.") } Statistics( sizeInBytes = children.map(_.statistics).map(_.sizeInBytes).product) } /** * Returns the set of attributes that this node takes as * input from its children. */ lazy val inputSet: AttributeSet = AttributeSet(children.flatMap(_.output)) /** * Returns true if this expression and all its children have been resolved to a specific schema * and false if it is still contains any unresolved placeholders. Implementations of LogicalPlan * can override this (e.g. * [[org.apache.spark.sql.catalyst.analysis.UnresolvedRelation UnresolvedRelation]] * should return `false`). */ lazy val resolved: Boolean = !expressions.exists(!_.resolved) && childrenResolved /** * Returns true if all its children of this query plan have been resolved. */ def childrenResolved: Boolean = !children.exists(!_.resolved) /** * Optionally resolves the given string to a [[NamedExpression]] using the input from all child * nodes of this LogicalPlan. The attribute is expressed as * as string in the following form: `[scope].AttributeName.[nested].[fields]...`. */ def resolveChildren(name: String): Option[NamedExpression] = resolve(name, children.flatMap(_.output)) /** * Optionally resolves the given string to a [[NamedExpression]] based on the output of this * LogicalPlan. The attribute is expressed as string in the following form: * `[scope].AttributeName.[nested].[fields]...`. */ def resolve(name: String): Option[NamedExpression] = resolve(name, output) /** Performs attribute resolution given a name and a sequence of possible attributes. */ protected def resolve(name: String, input: Seq[Attribute]): Option[NamedExpression] = { val parts = name.split("\\.") val options = input.flatMap { option => val remainingParts = if (option.qualifiers.contains(parts.head) && parts.size > 1) parts.drop(1) else parts if (option.name == remainingParts.head) (option, remainingParts.tail.toList) :: Nil else Nil } options.distinct match { case Seq((a, Nil)) => Some(a) // One match, no nested fields, use it. // One match, but we also need to extract the requested nested field. case Seq((a, nestedFields)) => a.dataType match { case StructType(fields) => Some(Alias(nestedFields.foldLeft(a: Expression)(GetField), nestedFields.last)()) case _ => None // Don't know how to resolve these field references } case Seq() => None // No matches. case ambiguousReferences => throw new TreeNodeException( this, s"Ambiguous references to $name: ${ambiguousReferences.mkString(",")}") } } }
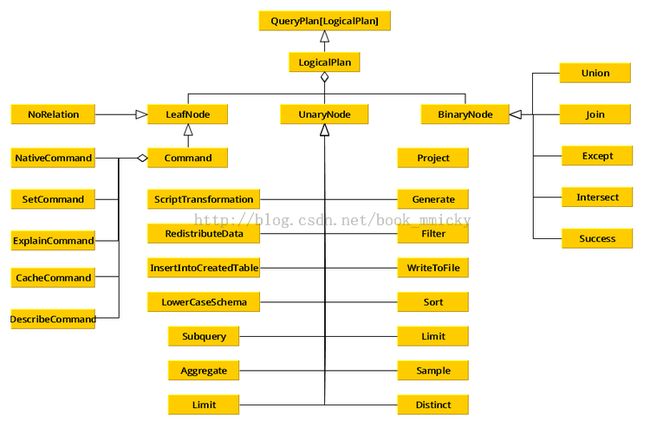
- LeafNode:对应于trees.LeafNode的LogicalPlan
- UnaryNode:对应于trees.UnaryNode的LogicalPlan
- BinaryNode:对应于trees.BinaryNode的LogicalPlan
- basicOperators:一些数据基本操作,如Ioin、Union、Filter、Project、Sort
- commands:一些命令操作,如SetCommand、CacheCommand
- partitioning:一些分区操作,如RedistributeData
- ScriptTransformation:对脚本的处理,如ScriptTransformation
- LogicalPlan类的总体架构如下所示
- 词法读入器SqlLexical,其作用就是将输入的SQL语句进行扫描、去空、去注释、校验、分词等动作。
- SQL语法表达式query,其作用定义SQL语法表达式,同时也定义了SQL语法表达式的具体实现,即将不同的表达式生成不同sparkSQL的Unresolved LogicalPlan。
- 函数phrase(),上面个两个组件通过调用phrase(query)(new lexical.Scanner(input)),完成对SQL语句的解析;在解析过程中,SqlLexical一边读入,一边解析,如果碰上生成符合SQL语法的表达式时,就调用相应SQL语法表达式的具体实现函数,将SQL语句解析成Unresolved LogicalPlan。
然后,直接在SqlParser的apply方法中对输入的SQL语句进行解析,解析功能的核心代码就是:/*源自 sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
protected[sql] val parser = new catalyst.SqlParser
protected[sql] def parseSql(sql: String): LogicalPlan = parser(sql)
/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */
class SqlParser extends StandardTokenParsers with PackratParsers { def apply(input: String): LogicalPlan = { if (input.trim.toLowerCase.startsWith("set")) { //set设置项的处理
...... } else { phrase(query)(new lexical.Scanner(input)) match { case Success(r, x) => r case x => sys.error(x.toString) } } }
......
/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */
// Use reflection to find the reserved words defined in this class. protected val reservedWords = this.getClass .getMethods .filter(_.getReturnType == classOf[Keyword]) .map(_.invoke(this).asInstanceOf[Keyword].str) override val lexical = new SqlLexical(reservedWords)
运行结果:import scala.util.parsing.combinator.PackratParsers import scala.util.parsing.combinator.syntactical._ object mylexical extends StandardTokenParsers with PackratParsers { //定义分割符 lexical.delimiters ++= List(".", ";", "+", "-", "*") //定义表达式,支持加,减,乘 lazy val expr: PackratParser[Int] = plus | minus | multi //加法表示式的实现 lazy val plus: PackratParser[Int] = num ~ "+" ~ num ^^ { case n1 ~ "+" ~ n2 => n1.toInt + n2.toInt} //减法表达式的实现 lazy val minus: PackratParser[Int] = num ~ "-" ~ num ^^ { case n1 ~ "-" ~ n2 => n1.toInt - n2.toInt} //乘法表达式的实现 lazy val multi: PackratParser[Int] = num ~ "*" ~ num ^^ { case n1 ~ "*" ~ n2 => n1.toInt * n2.toInt} lazy val num = numericLit def parse(input: String) = {
//定义词法读入器myread,并将扫描头放置在input的首位
val myread = new PackratReader(new lexical.Scanner(input)) print("处理表达式 " + input) phrase(expr)(myread) match { case Success(result, _) => println(" Success!"); println(result); Some(result) case n => println(n); println("Err!"); None } } def main(args: Array[String]) { val prg = "6 * 3" :: "24-/*aaa*/4" :: "a+5" :: "21/3" :: Nil prg.map(parse) } }
处理表达式 6 * 3 Success! //lexical对空格进行了处理,得到6*3 18 //6*3符合乘法表达式,调用n1.toInt * n2.toInt,得到结果并返回
处理表达式 24-/*aaa*/4 Success! //lexical对注释进行了处理,得到20-4 20 //20-4符合减法表达式,调用n1.toInt - n2.toInt,得到结果并返回 处理表达式 a+5[1.1] failure: number expected //lexical在解析到a,发现不是整数型,故报错误位置和内容 a+5 ^ Err! 处理表达式 21/3[1.3] failure: ``*'' expected but ErrorToken(illegal character) found //lexical在解析到/,发现不是分割符,故报错误位置和内容 21/3 ^ Err!
- p ~ q p成功,才会q;放回p,q的结果
- p ~> q p成功,才会q,返回q的结果
- p <~ q p成功,才会q,返回p的结果
- p | q p失败则q,返回第一个成功的结果
- p ^^ f 如果p成功,将函数f应用到p的结果上
- p ^? f 如果p成功,如果函数f可以应用到p的结果上的话,就将p的结果用f进行转换

- 扩展了scala.util.parsing.combinator.Parsers所提供的parser,做了内存化处理;
- Packrat解析器实现了回溯解析和递归下降解析,具有无限先行和线性分析时的优势。同时,也支持左递归词法解析。
- 从Parsers中继承出来的class或trait都可以使用PackratParsers,如:object MyGrammar extends StandardTokenParsers with PackratParsers;
- PackratParsers将分析结果进行缓存,因此,PackratsParsers需要PackratReader(内存化处理的Reader)作为输入,程序员可以手工创建PackratReader,如production(new PackratReader(new lexical.Scanner(input))),更多的细节参见scala库中/scala/util/parsing/combinator/PackratParsers.scala文件。
- 增加了词法的处理能力(Parsers是字符处理),在StdTokenParsers中定义了四种基本词法:
- keyword tokens
- numeric literal tokens
- string literal tokens
- identifier tokens
- 定义了一个词法读入器lexical,可以进行词法读入
在解析过程中,一般会定义多个表达式,如上面例子中的plus | minus | multi,一旦前一个表达式不能解析的话,就会调用下一个表达式进行解析:/*源自 scala/util/parsing/combinator/PackratParsers.scala */
/** * A parser generator delimiting whole phrases (i.e. programs). * * Overridden to make sure any input passed to the argument parser * is wrapped in a `PackratReader`. */ override def phrase[T](p: Parser[T]) = { val q = super.phrase(p) new PackratParser[T] { def apply(in: Input) = in match { case in: PackratReader[_] => q(in) case in => q(new PackratReader(in)) } } }
表达式解析正确后,具体的实现函数是在 PackratParsers中完成:/*源自 scala/util/parsing/combinator/Parsers.scala */
def append[U >: T](p0: => Parser[U]): Parser[U] = { lazy val p = p0 // lazy argument Parser{ in => this(in) append p(in)} }
StandardTokenParsers增加了词法处理能力,SqlParers定义了大量的关键字,重写了词法读入器,将这些关键字应用于词法读入器。/*源自 scala/util/parsing/combinator/PackratParsers.scala */
def memo[T](p: super.Parser[T]): PackratParser[T] = { new PackratParser[T] { def apply(in: Input) = { val inMem = in.asInstanceOf[PackratReader[Elem]] //look in the global cache if in a recursion val m = recall(p, inMem) m match { //nothing has been done due to recall case None => val base = LR(Failure("Base Failure",in), p, None) inMem.lrStack = base::inMem.lrStack //cache base result inMem.updateCacheAndGet(p,MemoEntry(Left(base))) //parse the input val tempRes = p(in) //the base variable has passed equality tests with the cache inMem.lrStack = inMem.lrStack.tail //check whether base has changed, if yes, we will have a head base.head match { case None => /*simple result*/ inMem.updateCacheAndGet(p,MemoEntry(Right(tempRes))) tempRes case s@Some(_) => /*non simple result*/ base.seed = tempRes //the base variable has passed equality tests with the cache val res = lrAnswer(p, inMem, base) res } case Some(mEntry) => { //entry found in cache mEntry match { case MemoEntry(Left(recDetect)) => { setupLR(p, inMem, recDetect) //all setupLR does is change the heads of the recursions, so the seed will stay the same recDetect match {case LR(seed, _, _) => seed.asInstanceOf[ParseResult[T]]} } case MemoEntry(Right(res: ParseResult[_])) => res.asInstanceOf[ParseResult[T]] } } } } } }
其次丰富了分隔符、词法处理、空格注释处理:/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */
protected val ALL = Keyword("ALL") protected val AND = Keyword("AND") protected val AS = Keyword("AS") protected val ASC = Keyword("ASC") ...... protected val SUBSTR = Keyword("SUBSTR") protected val SUBSTRING = Keyword("SUBSTRING")
最后看看SQL语法表达式query。/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */
delimiters += ( "@", "*", "+", "-", "<", "=", "<>", "!=", "<=", ">=", ">", "/", "(", ")", ",", ";", "%", "{", "}", ":", "[", "]" ) override lazy val token: Parser[Token] = ( identChar ~ rep( identChar | digit ) ^^ { case first ~ rest => processIdent(first :: rest mkString "") } | rep1(digit) ~ opt('.' ~> rep(digit)) ^^ { case i ~ None => NumericLit(i mkString "") case i ~ Some(d) => FloatLit(i.mkString("") + "." + d.mkString("")) } | '\'' ~ rep( chrExcept('\'', '\n', EofCh) ) ~ '\'' ^^ { case '\'' ~ chars ~ '\'' => StringLit(chars mkString "") } | '\"' ~ rep( chrExcept('\"', '\n', EofCh) ) ~ '\"' ^^ { case '\"' ~ chars ~ '\"' => StringLit(chars mkString "") } | EofCh ^^^ EOF | '\'' ~> failure("unclosed string literal") | '\"' ~> failure("unclosed string literal") | delim | failure("illegal character") ) override def identChar = letter | elem('_') | elem('.') override def whitespace: Parser[Any] = rep( whitespaceChar | '/' ~ '*' ~ comment | '/' ~ '/' ~ rep( chrExcept(EofCh, '\n') ) | '#' ~ rep( chrExcept(EofCh, '\n') ) | '-' ~ '-' ~ rep( chrExcept(EofCh, '\n') ) | '/' ~ '*' ~ failure("unclosed comment") )
/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */
protected lazy val query: Parser[LogicalPlan] = ( select * ( UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) } | INTERSECT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Intersect(q1, q2) } | EXCEPT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Except(q1, q2)} | UNION ~ opt(DISTINCT) ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) } ) | insert | cache )
/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */
protected lazy val select: Parser[LogicalPlan] = SELECT ~> opt(DISTINCT) ~ projections ~ opt(from) ~ opt(filter) ~ opt(grouping) ~ opt(having) ~ opt(orderBy) ~ opt(limit) <~ opt(";") ^^ { case d ~ p ~ r ~ f ~ g ~ h ~ o ~ l => val base = r.getOrElse(NoRelation) val withFilter = f.map(f => Filter(f, base)).getOrElse(base) val withProjection = g.map {g => Aggregate(assignAliases(g), assignAliases(p), withFilter) }.getOrElse(Project(assignAliases(p), withFilter)) val withDistinct = d.map(_ => Distinct(withProjection)).getOrElse(withProjection) val withHaving = h.map(h => Filter(h, withDistinct)).getOrElse(withDistinct) val withOrder = o.map(o => Sort(o, withHaving)).getOrElse(withHaving) val withLimit = l.map { l => Limit(l, withOrder) }.getOrElse(withOrder) withLimit }
/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala */
val batches: Seq[Batch] = Seq( Batch("MultiInstanceRelations", Once, NewRelationInstances), Batch("CaseInsensitiveAttributeReferences", Once, (if (caseSensitive) Nil else LowercaseAttributeReferences :: Nil) : _*), Batch("Resolution", fixedPoint, ResolveReferences :: ResolveRelations :: ResolveSortReferences :: NewRelationInstances :: ImplicitGenerate :: StarExpansion :: ResolveFunctions :: GlobalAggregates :: UnresolvedHavingClauseAttributes :: typeCoercionRules :_*), Batch("Check Analysis", Once, CheckResolution), Batch("AnalysisOperators", fixedPoint, EliminateAnalysisOperators) )
- MultiInstanceRelations
- NewRelationInstances
- CaseInsensitiveAttributeReferences
- LowercaseAttributeReferences
- Resolution
- ResolveReferences
- ResolveRelations
- ResolveSortReferences
- NewRelationInstances
- ImplicitGenerate
- StarExpansion
- ResolveFunctions
- GlobalAggregates
- UnresolvedHavingClauseAttributes
- typeCoercionRules
- Check Analysis
- CheckResolution
- AnalysisOperators
- EliminateAnalysisOperators
又比如rule之StarExpansion,其作用就是将Select * Fom tbl中的*展开,赋予列名:/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala */
object ResolveReferences extends Rule[LogicalPlan] { def apply(plan: LogicalPlan): LogicalPlan = plan transformUp { case q: LogicalPlan if q.childrenResolved => logTrace(s"Attempting to resolve ${q.simpleString}") q transformExpressions { case u @ UnresolvedAttribute(name) => // Leave unchanged if resolution fails. Hopefully will be resolved next round. val result = q.resolveChildren(name).getOrElse(u) logDebug(s"Resolving $u to $result") result } } }
/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala */
object StarExpansion extends Rule[LogicalPlan] { def apply(plan: LogicalPlan): LogicalPlan = plan transform { // Wait until children are resolved case p: LogicalPlan if !p.childrenResolved => p // If the projection list contains Stars, expand it. case p @ Project(projectList, child) if containsStar(projectList) => Project( projectList.flatMap { case s: Star => s.expand(child.output) case o => o :: Nil }, child) case t: ScriptTransformation if containsStar(t.input) => t.copy( input = t.input.flatMap { case s: Star => s.expand(t.child.output) case o => o :: Nil } ) // If the aggregate function argument contains Stars, expand it. case a: Aggregate if containsStar(a.aggregateExpressions) => a.copy( aggregateExpressions = a.aggregateExpressions.flatMap { case s: Star => s.expand(a.child.output) case o => o :: Nil } ) } /** * Returns true if `exprs` contains a [[Star]]. */ protected def containsStar(exprs: Seq[Expression]): Boolean = exprs.collect { case _: Star => true }.nonEmpty } }
/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala */
object Optimizer extends RuleExecutor[LogicalPlan] { val batches = Batch("Combine Limits", FixedPoint(100), CombineLimits) :: Batch("ConstantFolding", FixedPoint(100), NullPropagation, ConstantFolding, LikeSimplification, BooleanSimplification, SimplifyFilters, SimplifyCasts, SimplifyCaseConversionExpressions) :: Batch("Filter Pushdown", FixedPoint(100), CombineFilters, PushPredicateThroughProject, PushPredicateThroughJoin, ColumnPruning) :: Nil }
- Combine Limits 合并Limit
- CombineLimits:将两个相邻的limit合为一个
- ConstantFolding 常量叠加
- NullPropagation 空格处理
- ConstantFolding:常量叠加
- LikeSimplification:like表达式简化
- BooleanSimplification:布尔表达式简化
- SimplifyFilters:Filter简化
- SimplifyCasts:Cast简化
- SimplifyCaseConversionExpressions:CASE大小写转化表达式简化
- Filter Pushdown Filter下推
- CombineFilters Filter合并
- PushPredicateThroughProject 通过Project谓词下推
- PushPredicateThroughJoin 通过Join谓词下推
- ColumnPruning 列剪枝
/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala */
object CombineLimits extends Rule[LogicalPlan] { def apply(plan: LogicalPlan): LogicalPlan = plan transform { case ll @ Limit(le, nl @ Limit(ne, grandChild)) => Limit(If(LessThan(ne, le), ne, le), grandChild) } }
对于具体的优化方法可以使用下一章所介绍的hive/console调试方法进行调试,用户可以使用自定义的优化函数,也可以使用sparkSQL提供的优化函数。使用前先定义一个要优化查询,然后查看一下该查询的Analyzed LogicalPlan,再使用优化函数去优化,将生成的Optimized LogicalPlan和Analyzed LogicalPlan进行比较,就可以看到优化的效果。/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala */
object NullPropagation extends Rule[LogicalPlan] { def apply(plan: LogicalPlan): LogicalPlan = plan transform { case q: LogicalPlan => q transformExpressionsUp { case e @ Count(Literal(null, _)) => Cast(Literal(0L), e.dataType) case e @ Sum(Literal(c, _)) if c == 0 => Cast(Literal(0L), e.dataType) case e @ Average(Literal(c, _)) if c == 0 => Literal(0.0, e.dataType) case e @ IsNull(c) if !c.nullable => Literal(false, BooleanType) case e @ IsNotNull(c) if !c.nullable => Literal(true, BooleanType) case e @ GetItem(Literal(null, _), _) => Literal(null, e.dataType) case e @ GetItem(_, Literal(null, _)) => Literal(null, e.dataType) case e @ GetField(Literal(null, _), _) => Literal(null, e.dataType) case e @ EqualNullSafe(Literal(null, _), r) => IsNull(r) case e @ EqualNullSafe(l, Literal(null, _)) => IsNull(l) ...... } } }