【北大天网搜索引擎TSE学习笔记】第11节——倒排索引等数据文件的建立(预处理子系统)
前面的章节详细的介绍了查询服务子系统,可以发现查询服务子系统是基于一些”数据文件“实现查询功能的,这些”数据文件“在第2节中介绍过,包括:词典文件(words.dict)、原始网页数据库文件(Tianwang.raw.2559638448)、网页索引文件(Doc.idx)、URL索引文件(Url.idx.sort_uniq)、倒排索引文件(sun.iidx),其中words.dict是已经有的、Tianwang.raw.2559638448是爬虫抓取生成的,其他的文件就需要程序生成出来,这就是预处理子系统的工作。预处理程序对原始网页数据库文件进行分析生成这些数据文件,其中最重要的是倒排索引文件,因为查询服务子系统就是在该文件中查找关键词的。
那么预处理程序如何运行生成这些数据文件呢?在TSE的源代码中有一个文档(TSE/index/readme.txt)进行了说明。
============================================== readme.txt ===============================================
1. The document index (Doc.idx) keeps information about each document. It is a fixed width ISAM (Index sequential access mode) index, orderd by docID.The information stored in each entry includes a pointer into the repository, a document length, a document checksum. The url index (url.idx) is used to
convert URLs into docIDs. It is a list of URL checksums with their corresponding docIDs and is sorted by checksum. In order to find the docID of a
particular URL, the URL's checksum is computed and a binary search is performed on the checksums file to find its docID.
./DocIndex
got Doc.idx, Url.idx, DocId2Url.idx
2. sort Url.idx|uniq > Url.idx.sort_uniq
3. Segment document to terms, (with finding document according to the url)
./DocSegment Tianwang.raw.2559638448
got Tianwang.raw.2559638448.seg
4. Create forward index (docic-->termid)
./CrtForwardIdx Tianwang.raw.2559638448.seg > moon.fidx
5.# set | grep "LANG" LANG=en;
export LANG;
sort moon.fidx > moon.fidx.sort
6. Create inverted index (termid-->docid)
./CrtInvertedIdx moon.fidx.sort > sun.iidx
----------------------------------------------------
provding service
at http://162.105.80.60/TSE/
TSESearch CGI program for query
Snapshot CGI program for page snapshot
=====================================================================================================
该文件说明了生成倒排文件等重要数据文件的操作过程。 在index目录下执行make后,可以看到目录中生成的可执行程序有: CrtForwardIdx、CrtInvertedIdx、DocIndex、DocSegment、Snapshot、TSESearch。其中TSESearch和Snapshot是查询和网页快照功能的CGI程序,而其他几个便是在本地执行的生成数据文件的程序。这里简单介绍一下这些程序怎么执行,index目录下有一个Data目录,里面有Tianwang.raw.2559638448文件,而且查询服务子系统也是在该目录中读取数据文件的,所以我们把所有的数据文件都生成在index/Data中,所以第一步需要把可执行程序CrtForwardIdx、CrtInvertedIdx、DocIndex、DocSegment拷贝到index/Data中,然后在该目录中通过命令行执行程序。
1> ./DocIndex
执行该命令后会生成Doc.idx(网页索引), Url.idx(Url索引), DocId2Url.idx(Docid到Url的索引),执行该程序时,没有输入参数,因为程序中固定读取当前目录的 Tianwang.raw.2559638448文件,后面分析源代码时可以看到。实际上,该程序应该像其他几个程序一样通过命令行 参数传入要分析的原始网页数据文件。
2> sort Url.idx|uniq > Url.idx.sort_uniq
sort是linux命令,这一步是对Url.idx按字典顺序排序,而Url.idx中的记录第一个字段是Url的MD5值,所以是按 Url的MD5值排序,uniq是去除重复的Url记录。所以最终得到的Url.idx.sort_uniq是去重的按Url的MD5值排序的 索引表,排序是为了更高效的查找(第2节中介绍过了)。
3> ./DocSegment Tianwang.raw.2559638448
这一步对原始网页数据文件中的网页正文内容进行分词,先将网页的HTML中去除HTML标签得到正文部分,然后调用 中文分词模块将正文内容切分成独立的词。命令运行后得到Tianwang.raw.2559638448.seg,该文件的内容如图1所示,每条记录占两行,第一行为网页的docid,第二行为分词(用"/ "分割)以后的正文内容。

图1
4>./CrtForwardIdx Tianwang.raw.2559638448.seg > moon.fidx
这一步是对上一步生成的切分后的网页正文(Tianwang.raw.2559638448.seg)创建正向索引文件,该命令输入参数是 Tianwang.raw.2559638448.seg,输出是标准输出,这里用linux的重定向(>)符号将输出内容重定向到moon.fidx文件。如图2所示,每行第一字段为网页中的词,第二字段为所在网页的docid,中间用 \t隔开。

图2
5> sort moon.fidx > moon.fidx.sort
这一步对上一步生成的正向索引文件按关键字排序(字典顺序),sort是linux命令,sort之前是以docid的排序的,sort 之后按关键词排序,所有相同的关键词排在一起,为了方便下一步建立倒排索引。排序后的索引文件moon.fidx.sort 内容如图3所示。
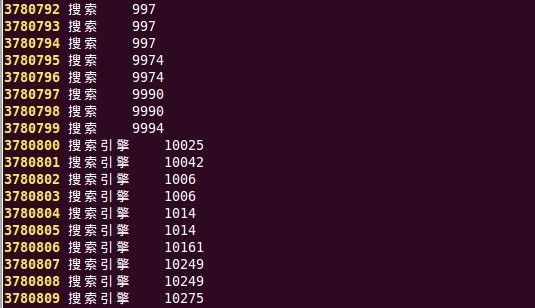
图3
6> ./CrtInvertedIdx moon.fidx.sort > sun.iidx
这一步建立倒排索引,把上一步排序后的索引文件中所有相同关键词组合起来,该命令输入参数为moon.fidx.sort, 输出结果重定向到而文件sun.iidx中,sun.iidx的内容如图4所示,每条记录占一行,第一个字段 为关键词,第二个字段是该关键词出现的网页的docid序列(docid之间用空格分开)。图4中就是"搜索"这个词的倒排索引了。 因此,查询服务子系统之用查询该倒排表就能得到关键词出现的所有网页的docid了。
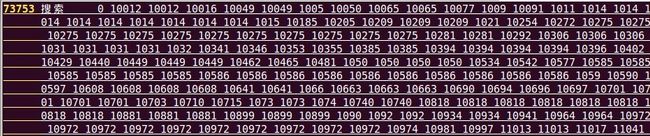
图4
至此,查询服务子系统需要的搜索数据文件都已生成,预处理子系统的工作也就完成了。上面执行的程序CrtForwardIdx、CrtInvertedIdx、DocIndex、DocSegment对应的源代码为index目录中的CrtForwardIdx.cpp、CrtInvertedIdx.cpp、DocIndex.cpp、DocSegment.cpp。这些源代码都非常简单,就是简单的文本分析,本系列笔记就不详细解释了,读者朋友们可以自己阅读。至此,预处理子系统的介绍就全部结束。
By:
