OpenStack高可用 -- DRBD块镜像 + Pacemaker心跳机制实现Active/Passive模式的高可用mysql集群 ( by quqi99 )
OpenStack高可用 --
DRBD块镜像 + Pacemaker心跳机制实现Active/Passive模式的高可用mysql集群 ( by quqi99 )
作者:张华 发表于:2013-07-20
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明
http://blog.csdn.net/quqi99 )
这个属于HA(高可用)的范畴。
对于高可用,一般得将应用区分为有状态和无状态:
1)对于无状态的服务,如nova-api, nova-conductor, glance-api, keystone-api, neutron-api, nova-schduler,这个简单了,因为无状态,在多个计算节点多启动几个这样的服务,然后前端在通过LB (such as HAProxy)加入VIP就行了。
2)对于有状态的服务,像horizon, db, mq之类。根据情况可以有Active/Passive和Active/Active的模式。
Active/Passive,一般作为standby的从节点的服务是不启动的,使用DRBD在主从节点之间做镜像然后再结合心跳heartbeat用pacemaker作切换。
Active/Active, 可用Galera,可同时对主从节点进行读写,主从节点的数据一致性由Galera来异步保证。
DRBD (distribute replication block device,分布式复制块设备),经常用来代替共享磁盘。它的工作原理是:在A主机上有对指定磁盘设备写请求时,数据发送给A主机的kernel,然后通过kernel中的一个模块,把相同的数据传送给B主机的kernel中一份,然后B主机再写入自己指定的磁盘设备,从而实现两主机数据的同步,也就实现了写操作高可用。DRBD一般是一主一从,并且所有的读写操作,挂载只能在主节点服务器上进行,但是主从DRBD服务器之间是可以进行调换的。
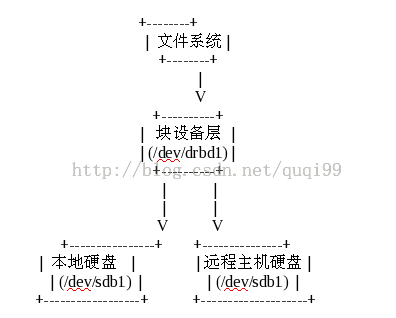
除了DRBD可以做块镜像保持同步外,mysql自身的Replication功能也是可以保持master/slave的数据库之间的同步的。http://www.cnblogs.com/hustcat/archive/2009/12/19/1627525.html
Pacemaker支持任何冗余配置,包括:Active/Active, Active/Passive,N+1, N+M, N-to-1 and N-to-N
VIP, 192.168.99.122
node1 192.168.99.100
node2 192.168.99.101
两台机器上分别配置无密码访问:
[hua@node1 ~]$ ssh-keygen -t rsa
[hua@node1 ~]$ ssh-copy-id -i .ssh/id_rsa.pub hua@node2
[hua@node2 ~]$ ssh-keygen -t rsa
[hua@node2 ~]$ ssh-copy-id -i .ssh/id_rsa.pub hua@node1
1 在主从两台机器上均安装mysql, 确保就用默认支持事务的InnoDB引擎(mysql -uroot -e "show engines")
DATABASE_USER=root
DATABASE_PASSWORD=password
sudo yum install mysql
sudo cp /usr/share/mysql/my-huge.cnf /etc/my.cnf
sudo service mysqld start
# Set the root password - only works the first time.
sudo mysqladmin -uroot password $DATABASE_PASSWORD || true
sudo mysql -uroot -p$DATABASE_PASSWORD -e "GRANT ALL PRIVILEGES ON *.* TO '$DATABASE_USER'@'%' identified by '$DATABASE_PASSWORD';"
2 在主从两台机器上均安装DRBD
sudo yum install kernel-devel-`uname -r`
sudo yum install brdb8.3.11
sudo modprobe drbd
cat /etc/drbd.d/mysql.res
resource mysql_res {
device /dev/drbd0;
disk "/dev/loop0";
meta-disk internal;
on node1{
address 192.168.99.100:7788;
}
on node2{
address 192.168.99.101:7788;
}
}
说明如下:
1)最好用一块干净的分区做backing file, 如sdb,查看分区:sudo fdisk -l /dev/sda
这里我们用文件系统模拟一块:
dd if=/dev/zero of=/bak/images/myql_backing_file bs=10M count=10
sudo losetup -f --show /bak/images/myql_backing_file
/dev/loop0
2) meta-disk为internal意思是说将DRBD-specific metadata安装backing file自己上面
3) /dev/drbd0是定义的DRBD设备的名字
4) 在/etc/hosts文件中写义host, (hostname一个是node1, 一个是node2)
192.168.99.100 node1
192.168.99.101 node2
5) resource mysql_res, 一个drbd设备即/dev/loop0也是一个资源
6) 防火墙打开7788端口,或:sudo iptables -F
接着创建一个DRBD资源,它会初始化元数据到backing file中,删除资源用命令:sudo drbdadm detach all
sudo drbdadm create-md mysql_res
sudo drbdadm up mysql_res #attach DRBD设备到backing file上,两个节点均要做
启动master上的drbd服务,sudo service drbd restart,它会等从节点上的服务也启动,那就再启动从节点上的服务,ok
查看状态:
[hua@laptop ~]$ cat /proc/drbd
version: 8.4.2 (api:1/proto:86-101)
srcversion: 736E684C7C139044D743D35
0: cs:SyncSource ro:Secondary/Secondary ds:UpToDate/Inconsistent C r---n-
ns:98692 nr:0 dw:0 dr:98940 al:0 bm:6 lo:0 pe:3 ua:3 ap:0 ep:1 wo:f oos:3800
[===================>] sync'ed:100.0% (3800/102360)K
finish: 0:00:01 speed: 2,788 (2,592) K/sec
主节点执行:sudo drbdadm -- --force primary mysql_res #只是master节点上设置它为primary(即可读可写)
从节点执行:sudo drbdadm secondary mysql_res)
3, 使用DRBD设备:
sudo mkfs -t xfs /dev/drbd0 (这个命令只能在master节点上做,因为只有master节点的角色是可读可写的)
对于已存在的mysql数据库,数据目录位于/var/lib/mysql,最简单的就是将这个目录移到DRBD设备。确保关闭mysql的时候做下列步骤:
sudo mount /dev/drbd0 /var/lib/mysql
sudo mv /var/lib/mysql/* /var/lib/mysql
对于新建的mysql数据库,因为无数以的,可以:
sudo mount /dev/drbd0 /var/lib/mysql
sudo mysql_install_db --datadir=/var/lib/mysql
随便建一个测试文件: sudo touch /var/lib/mysql/test.txt,
现在应该/var/lib/mysql/test.txt文件已经复制到从节点上了。那么想要挂载从主节只读的DRBD设备,我们现在它从节点升级成可读可写的主节点:
在现在的主节点上, 先sudo umount /var/lib/mysql, 然后降级:sudo drbdadm secondary mysql_res
然后在从节点上,升级成主节点:sudo drbdadm -- --force primary mysql_res, sudo mount /dev/drbd0 /var/lib/mysql,用 ll mnt命令查看你会看到文件已经复制过来了。
4, ok, 上述的过程已经说明了,出现故障,就是要通过心跳机制将出故障的机器降级成主节点,然后将从节点升级成主节点而已。
1)pacemaker可以调用hearbeat做心跳,它的底层使用了组通讯框架Corosync
2) 两台机器均安装:sudo yum install pacemaker corosync heartbeat -y
生成相同的密钥(所谓的相同是指在一台机器上生成再拷到其他的机器)(/etc/corosync/authkey):sudo corosync-keygen
3) 两节点均要配置Corosync. 在此我们使用单播模式, 这样可以减少网络广播.
sudo cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
cat /etc/corosync/corosync.conf
totem {
version: 2
secauth: off
interface {
member {
memberaddr: 192.168.99.100
}
member {
memberaddr: 192.168.99.101
}
ringnumber: 0
bindnetaddr: 192.168.99.0
mcastport: 5405
ttl: 1
}
transport: udpu
}
service {
name: pacemaker
ver: 1
}
logging {
fileline: off
to_logfile: yes
to_syslog: yes
debug: on
logfile: /var/log/cluster/corosync.log
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
}
}
且要设置属性no-quorum-policy, 因为quorum只有一半节点在线才算合法的,不设置无法模拟。下面的CLI命令相当于直接修改文件/var/lib/heartbeat/crm/cib.xml
[hua@laptop ~]$ sudo crm
crm(live)# configure
crm(live)configure# property no-quorum-policy="ignore"
crm(live)configure# commit
4) 分别在两台机器上查看状态,如果看到的不是两个节点可检查密钥是否相同。
总结健康:
[hua@node2 ~]$ sudo corosync-cfgtool -s
Printing ring status.
Local node ID 1701030080
RING ID 0
id = 192.168.99.101
status = ring 0 active with no faults
dump成员:
[hua@node1 ~]$ sudo corosync-cmapctl |grep member |grep ip
runtime.totem.pg.mrp.srp.members.1684252864.ip (str) = r(0) ip(192.168.99.100)
runtime.totem.pg.mrp.srp.members.1701030080.ip (str) = r(0) ip(192.168.99.101)
查看引擎是否启动
[hua@node1 ~]$ sudo grep -e "Corosync Cluster Engine" -e "configuration file" /var/log/messages
Jul 20 09:54:14 laptop corosync[3373]: [MAIN ] Corosync Cluster Engine ('2.3.0'): started and ready to provide service.
Jul 20 09:54:15 laptop corosync[3367]: Starting Corosync Cluster Engine (corosync): [ OK
查看初始成员是否加入
[hua@node1 ~]$ grep TOTEM /var/log/messages
Jul 20 17:48:24 laptop corosync[15233]: [TOTEM ] adding new UDPU member {192.168.99.101}
Jul 20 17:48:24 laptop corosync[15233]: [TOTEM ] adding new UDPU member {192.168.99.100}
查看是否有错误发生
[hua@node1 ~]$ sudo grep ERROR: /var/log/messages | grep -v unpack_resources
使用Crm status命令, 查看两个节点的信息,看该服务是否已经同
[hua@node1 ~]$ sudo service pacemaker restart
Restarting pacemaker (via systemctl): [ OK ]
[hua@laptop ~]$ sudo crm status
============
Last updated: Sat Jul 20 18:36:52 2013
Last change: Sat Jul 20 18:33:06 2013
Current DC: NONE
0 Nodes configured, unknown expected votes
0 Resources configured.
============
这里一直有错,不清楚是怎么回事,导致实验没有做下去,但心里清楚是怎么一回事就行了。
5) 启动pacemaker, sudo service pacemaker start
6) 最后通过上面已提到过的crm confiugre命令来为mysql配置VIP等信息:
primitive p_ip_mysql ocf:heartbeat:IPaddr2 params ip="192.168.99.122" cidr_netmask="24" op monitor interval="30s"
primitive p_drbd_mysql ocf:linbit:drbd params drbd_resource="mysql_res" op start timeout="90s" \
op stop timeout="180s" op promote timeout="180s" op demote timeout="180s" \
op monitor interval="30s" role="Slave" op monitor interval="29s" role="Master"
primitive p_fs_mysql ocf:heartbeat:Filesystem params device="/dev/loop0" directory="/var/lib/mysql" fstype="xfs" \
options="relatime" op start timeout="60s" op stop timeout="180s" op monitor interval="60s" timeout="60s"
primitive p_mysql ocf:heartbeat:mysql params additional_parameters="--bind-address=50.56.179.138"
config="/etc/my.cnf" pid="/var/run/mysqld/mysqld.pid" socket="/var/run/mysqld/mysqld.sock" \
log="/var/log/mysql/mysqld.log" op monitor interval="20s" timeout="10s" \
op start timeout="120s" op stop timeout="120s"
group g_mysql p_ip_mysql p_fs_mysql p_mysql
ms ms_drbd_mysql p_drbd_mysql meta notify="true" clone-max="2"
colocation c_mysql_on_drbd inf: g_mysql ms_drbd_mysql:Master
order o_drbd_before_mysql inf: ms_drbd_mysql:promote g_mysql:start
上面的方法只是Active/Passive模式的,如果要配Active/Active的mysql模式需要用到Galera,它的特点的能往每个Active的活动节点读和写,Galera自己的组通信框架来保证数据的一致性,略。
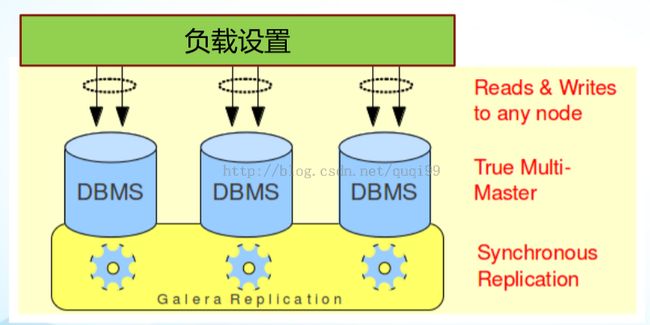
Reference: Openstack-ha-guide-trunk.pdf