Google后Hadoop时代的新“三驾马车”——Caffeine、Pregel、Dremel
http://www.csdn.net/article/2012-08-20/2808870
Mike Olson是Hadoop运动背后的主要推动者,但这还远远不够,目前Google内部使用的大数据软件Dremel使大数据处理起来更加智能。
Mike Olson目前任职于世界上最热的软件专业公司——Cloudera(硅谷的创业企业),并担任Cloudera的首席执行官。Cloudera围绕开源软件平台Hadoop发展自身的业务,开源软件平台Hadoop已经使得Google变身网络上最主导的力量。
预计到2016年Hadoop将会推动软件市场,并创造8.13亿美元的价值。不过Mike Olson表示这已经是老新闻了。
Hadoop的火爆要得益于Google在2003年底和2004年公布的两篇研究论文,其中一份描述了GFS(Google File System),GFS是一个可扩展的大型数据密集型应用的分布式文件系统,该文件系统可在廉价的硬件上运行,并具有可靠的容错能力,该文件系统可为用户提供极高的计算性能,而同时具备最小的硬件投资和运营成本。
另外一篇则描述了MapReduce,MapReduce是一种处理大型及超大型数据集并生成相关执行的编程模型。其主要思想是从函数式编程语言里借来的,同时也包含了从矢量编程语言里借来的特性。基于MapReduce编写的程序是在成千上万的普通PC机上被并行分布式自动执行的。8年后,Hadoop已经被广泛使用在网络上,并涉及数据分析和各类数学运算任务。但Google却提出更好的技术。
在2009年,网络巨头开始使用新的技术取代GFS和MapReduce。Mike Olson表示“这些技术代表未来的趋势。如果你想知道大规模、高性能的数据处理基础设施的未来趋势如何,我建议你看看Google即将推出的研究论文”。
自Hadoop兴起以来,Google已经发布了三篇研究论文,主要阐述了基础设施如何支持庞大网络操作。其中一份详细描述了Caffeine,Caffeine主要为Google网络搜索引擎提供支持。
在Google采用Caffeine之前,Google使用MapReduce和分布式文件系统(如GFS)来构建搜索索引(从已知的Web页面索引中)。在2010年,Google搜索引擎发生了重大变革。Google将其搜索迁移到新的软件平台,他们称之为“Caffeine”。Caffeine是Google出自自身的设计,Caffeine使Google能够更迅速的添加新的链接(包括新闻报道以及博客文章等)到自身大规模的网站索引系统中,相比于以往的系统,新系统可提供“50%新生”的搜索结果。
在本质上Caffeine丢弃MapReduce转而将索引放置在由Google开发的分布式数据库BigTable上。作为Google继GFS和MapReduce两项创新后的又一项创新,其在设计用来针对海量数据处理情形下的管理结构型数据方面具有巨大的优势。这种海量数据可以定义为在云计算平台中数千台普通服务器上PB级的数据。
另一篇介绍了Pregel,Pregel主要绘制大量网上信息之间关系的“图形数据库”。而最吸引人的一篇论文要属被称之为Dremel的工具。
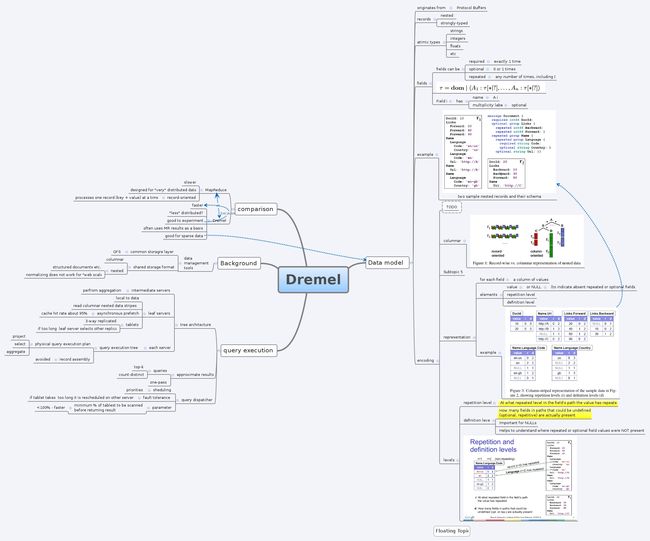
点击查看大图
专注于大型数据中心规模软件平台的加利福尼亚伯克利分校计算机科学教授Armando Fox表示“如果你事先告诉我Dremel可以做什么,那么我不会相信你可以把它开发出来”。
Dremel是一种分析信息的方式,Dremel可跨越数千台服务器运行,允许“查询”大量的数据,如Web文档集合或数字图书馆,甚至是数以百万计的垃圾信息的数据描述。这类似于使用结构化查询语言分析传统关系数据库,这种方式在过去几十年被广泛使用在世界各地。
Google基础设施负责人Urs Hölzle表示“使用Dremel就好比你拥有类似SQL的语言,并可以无需任何编程的情况下只需将请求输入命令行中就可以很容易的制定即席查询和重复查询”。
区别在于Dremel可以在极快的速度处理网络规模的海量数据。据Google提交的文件显示你可以在几秒的时间处理PB级的数据查询。
目前Hadoop已经提供了在庞大数据集上运行类似SQL的查询工具(如Hadoop生态圈中的项目Pig和Hive)。但其会有一些延迟,例如当部署任务时,可能需要几分钟的时间或者几小时的时间来执行任务,虽然可以得到查询结果,但相比于Pig和Hive,Dremel几乎是瞬时的。
Holzle表示Dremel可移执行多种查询,而同样的任务如果使用MapReduce来执行通差需要一个工作序列,但执行时间确实前者的一小部分。Dremel可在大约3秒钟时间里处理1PB的数据查询请求。
Armando Fox表示Dremel是史无前例的,Hadoop作为大数据运动的核心一直致力构建分析海量数据工具的生态圈。但就目前的大数据工具往往存在一个缺陷,与传统的数据分析或商业智能工具相比,Hadoop在数据分析的速度和精度上还无法相比。但目前Dremel做到了鱼和熊掌兼得。
Dremel做到了“不可能完成的任务”,Dremel设法将海量的数据分析于对数据的深入挖掘进行有机的结合。Dremel所处理的数据规模的速度实在令人印象深刻,你可以舒适的探索数据。在Dremel出现之前还没有类似的系统可以做的像Dremel这样出色。
据Google提交的文件来看,Google从2006年就在内部使用这个平台,有“数千名”的Google员工使用Dremel来分析一切,从Google各种服务的软件崩溃报告到Google数据中心内的磁盘行为。这种工具有时会在数十台服务器上使用,有时则会在数以千计的服务器上使用。
Mike Olson表示尽管Hadoop取得的成功不容置疑,但构建Hadoop生态圈的公司和企业显然慢了,而同样的情况也出现在Dremel上,Google在2010年公布了Dremel的相关文档,但这个平台还没有被第三方企业充分利用起来,目前以色列的工程团队正在建设被称为OpenDremel的克隆平台。David Gruzman表示OpenDremel目前仅仅还在开始阶段,还需要很长时间进行完善。
换句话说即使你不是Google的工程师你同样可以使用Dremel。Google现在提供的BigQuery的服务就是基于Dremel。用户可通过在线API来使用这个平台。用户可以把数据上传到Google,并在Google基础设施中运行用户的查询服务。而这只是Google越来越多云服务的一部分。
早期用户通过Google App Engine构建、运行、并将应用托管在Google基础设施平台之上。而现今Google提供了包括BigQuery和Google Compute Engine等服务和基础设施,这些服务和基础设施可使用户瞬时接入虚拟服务器。
全球很多技术都落后于Google,而Google自身的技术也正在影响全球。(李智/编辑)
原文链接:wired.com