observer、listener模式的推与拉
导读:
1. observer模式简介
2. 两种实现方式:推与拉
observer模式简介
observer模型,又被称作listener模式。这里统一用observer来称呼。
设计模式里对其结构的描述:
意图:
一个对象变化,通知其他被依赖的对象。
适用性:
两种对象subject与observers,相对相互独立,有单向依赖关系,observer依赖subject。
不知道具体有多少observer对象被通知。
采用这种方式,主要针对接口编程,抽象。
有可能一对多,也有可能是多对一,多对多。
两种实现:推与拉
推模式的结构:
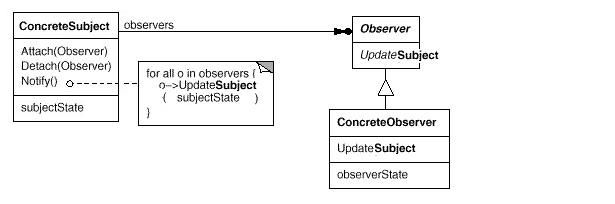
拉模式的结构:
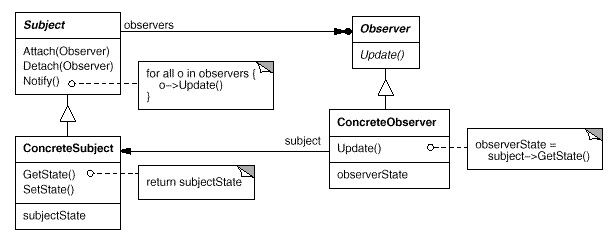
推模式与拉模式,各有优缺点:
对于单线程方式,推模式与拉模式的响应方式,一般都需要定义数据结构,都能保证信息传递(update代码被执行)。
推模式,需要定义push传递数据的接口。
优点:采用const引用的方式push数据,client端保存到本地。数据一般只需一次复制。专门定义的接口,便于程序理解,如notifyPriceDataChanged(Price &p);
缺点:但需要专门的接口定义。抽象接口,及继承类中的实现。复用性较差。
拉模式,需要定义get传递数据的接口。
优点:抽象的接口可以复用,update(subject *changedSubject); update的通知信息可以达到最小,且observer类可以被复用。
缺点:对于定义get接口返回数据,一般需要两次隐式的临时对象复制。或者直接返回构造函数,至少需要一次复制。more effective c++ 19.且程序结构较复杂。如果对象繁多,查看起来就比较费劲。 程序结构上变的复杂,不如推模式直观。
我自己的使用心得:
1. 在多subject对一observer的情况下,应用拉模式,虽然update传递的信息最小,就需要很多if条件语句,来确认是哪个concretesubject。
而推模式使用不同的接口来区分,若一个subject就有多个接口,每个接口就要写比较类似的实现及发送数据的代码,也是比较烦的事。
而一个subject对多个observer的情况下,拉模式与推模式的差别就没那么大了。
2. 程序逻辑上,在有多个subject或多个observer的情况下,推模式的结构比拉模式的结构更清晰些,只不过 推模式的代码要比拉模式多几行,但在以后回顾或查bug时,结构清晰,就轻松多了。
如果subject的接口不是很多的情况下,我会优先使用推模式的。(个人使用心得,仅供参考)
------------以下是摘自网络文章,在不同领域的应用-----------
对于服务器,非本地方式:
推模式的好处是能够及时响应,想要提供给Observer端什么数据,就将这些数据封装成对象,传递给Observer,缺点是需要创建自定义的事件关联信息,而且它必须关联到EventArgs对象。
缺点:精确性较差,不能保证能把信息送到客户器。但一般不会噪声阻塞。
拉模式的好处则是不需要另外定义对象,直接将自身的引用传递进去就可以了。
缺点:不能够及时获取系统的变更。可能因为IO事件,造成阻塞。
拉模型
最简单的是阻塞模型,对一个 socket 发起读请求后,程序会阻塞直到读请求调用完成后再返回。这是一个直白的拉模型,编写最为方便,当然,效率也是最低的。程序会经常阻塞在 IO 事件上,不能充分利用 CPU。
推模型
Windows 平台上性能最好的当数完成端口(IOCP)模型。当网络事件完成后,系统会把事件投递到完成端口的工作队列中,等待在队列另一端的处理线程会被唤醒进行相应的处理。为什么完成端口的性能高呢?从最底层看,所有的 IO 事件都是通过网络“推”过来的。操作系统通过中断相量(可以理解为最底层的回调函数)响应网络包数据。
从另外的角度来看,推、拉模型,是两种设计风格,他们在不同的层次都有出现,这里重点是observer的推与拉的应用理解。
参考:
http://alexyang.sinaapp.com/?p=50
http://www.cnblogs.com/rush/archive/2011/11/30/2269738.html