本文演示spark源码在idea编辑器上编译和提交任务
1、从网站上下载spark源码,在idea中 点击 VCS->CheckOut form Version Control->Git 把代码下载到本地
https://github.com/apache/spark

2、为了能让本地编译更快一些,设置父pom.xml 中加上oschina的maven源
<repository>
<id>nexus</id>
<name>local private nexus</name>
<url>http://maven.oschina.net/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
3、执行 mvn clean idea:idea 顺便说一下本地的mvn环境要在3.3.x以上
4、打开idea,点击菜单 File->Open-> 在弹出窗口中找spark源码然后打开
5、找到Master.scala然后点击运行;
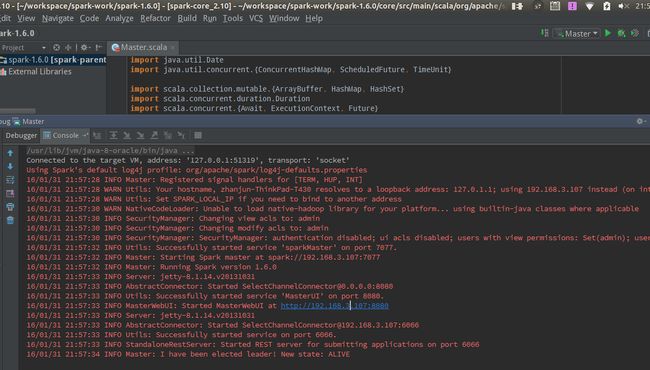
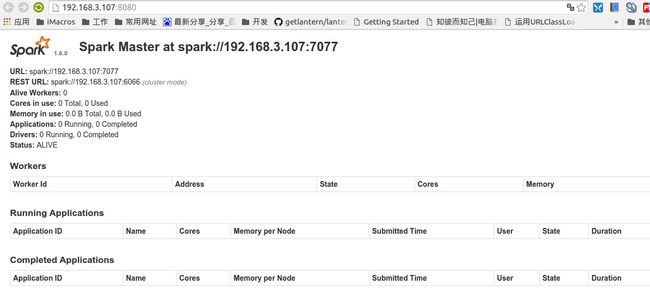
然后在浏览器中查看是否运行成功
6、接着运行worker,找到Worker.scala,右键运行,但是这里需要做点设置,在Program arguments:加上参数 --webui-port 8081 spark://192.168.3.107:7077 (注:有时候localhost不是很管用,要看系统的设置,最好使用ip)
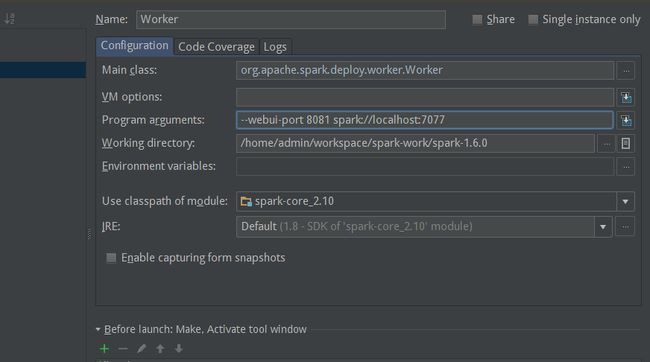
这时候刷新浏览器会发现worker 已经被注册进来了

8、我们写个spark程序提交执行试试看,新建一个scala maven工程,用于统计用户信息,工程下载见附件,核心代码如下:
package com.zhanjun.spark.learn
import org.apache.spark.{SparkConf, SparkContext}
object UserInfoCount {
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: UserInfoCount <file1> <file2>")
System.exit(1)
}
val conf = new SparkConf().setAppName("UserInfoCount")
val sc = new SparkContext(conf)
// 读取数据源,以“,”号分隔数据,过滤每行数据为8个字段
val userInfoRDD = sc.textFile(args(0)).map(_.split(",")).filter(_.length == 8)
// 按照地区进行统计,其中地区字段为第4个字段,合计后按照统计量进行排序
val blockCountRDD = userInfoRDD.map(x => (x(3), 1)).reduceByKey(_ + _).map(x => (x._2, x._1)).sortByKey(false).map(x => (x._2, x._1))
// 按手机号照前三位号码进行统计,其中手机号为第3个字段,合计后按照手机号码前三位数字排序(从小到大)
val phoneCountRDD = userInfoRDD.map(x => (x(2).substring(0, 3), 1)).reduceByKey(_ + _).sortByKey(true)
// 对两部分数据进行合并,然后输出到HDFS
val unionRDD = blockCountRDD.union(phoneCountRDD)
//repartition设置RDD中partition数量
unionRDD.repartition(1).saveAsTextFile(args(1))
sc.stop()
}
}
通过 mvn clean package 对工程打包,把users_txt.zip解压到相应的目录中。
9、我们回到spark源码的idea,通过idea提交job试试 找到org.apache.spark.deploy.SparkSubmit,右键运行,然后设置对应的参数
--class com.zhanjun.spark.learn.UserInfoCount --master local /home/admin/workspace/spark-work/UserInfoCount/target/UserInfoCount-1.0-SNAPSHOT.jar file:///home/admin/temp/users.txt file:///home/admin/temp/output/

我们可以发现 /home/admin/temp/output目录下面会生成对应的计算结果.

过程中使用了spark官网下载的源码 在sparksubmit时一直报错貌似是akka的初始化失败,后然从git上下载代码一切没有问题