Heterogeneous Parallel Programming(异构并行编程)学习笔记(四)
这次的内容主要集中在Reduction模型上。
1. Reduction
Reduction是一种广泛使用的计算模型,特别是在并行计算领域。简单地来说,Reduction就是一系列的划分(Partition)和汇总(Summarize)操作的集合:对输入数据分块,对每一个分块汇总,然后再将汇总后的数据视为新的输入数据,重复分块和汇总,直到得到最终结果,可以想象为一个倒置的树。Google和Hadoop的Map/Reduce中的Reduce计算就是一个很好的例子。
Reduction模型满足联合性和交换性:联合性:(a + b) + c = a + (b + c),交换性:a + b = b + c。换言之,Reduction模型对输入数据的顺序没有特定的要求。模型满足这两个性质,则里面的算符也必须满足这两个性质。常见的Reduction算符,也可以说是Reduction操作,包括了Max,Min,Sum,Product等,用户也可以自定义算符,但一定要注意,自定义的算符首先需要满足上述两个性质,其次需要定义单位值(Identity Value)。单位值是指一种特殊的值,它的存在对计算结果没有影响,比如,对Sum计算,0就是单位值。单位值常常被用来填充数据,使得数据长度为2的幂方值或某一特定值的整数倍。
一个Max算符的Reduction树如下图所示:
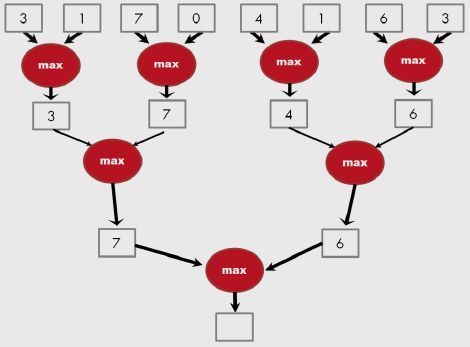
2. Reduction树的性能考虑
这里以一个求向量元素之和的计算任务为例来说明如何提高Reduction模型的性能。
向量求和可以如下图表示:

显而易见,这个过程包含了O(llogN)步,一共有O(N)的算符操作,每一步都会让活动的线程数减半。
现在来考虑性能。假设一个Warp大小为2个Thread(仅仅是假设,大多数情况下Warp大小为32T),那么一共需要2个Warp。在STEP1时,所有的4个Thread都处于活动状态,而到了STEP2,就只有T0和T2处于活动状态。但是,前面有提到过,Warp是调度的最小单位,所以,只要在Warp中有任何的活动线程,整个Warp就处于活动状态,其中的非活动状态的线程仍然会占用计算资源。因此,在STEP2时,尽管只有2个活动线程,但是仍然会占用4个线程的计算开销。
通过改变Reduction树计算方式可以解决这个问题。注意到上面的计算中,随着计算步骤增加,待计算的两个数据之间的距离是增加的。比如STEP1中3+1=4,3和1间距离为1,而STEP2中4+7=11,4和7间的距离为2。活动线程间的距离是数据距离的2倍,在它们之间是非活动线程。这样在计算中间过程中总有活动线程被非活动线程所分隔,就总会有多余1个的Warp同时包含了活动和非活动线程。
现在将上面的计算步骤反过来,先从距离为4的数据开始计算,即STEP1中T0会计算3+4=7而不是3+1=4。可以验证,这样的计算步骤所有的活动线程都集中在前部,所有的非活动线程都在后部。因此,至多只会有1个Warp同时包含了活动和非活动线程。
从上述例子可以看出,尽管Reduction模型对数据顺序没有要求,不同的计算顺序对性能是有影响的。
3. 代码示例
上述优化后的求和计算实现如下:
// just the kernel function
void sumOfVec(float *input) {
// take advantage of shared memory to speed up calculation
// each thread take 2 elements from input to shared memory
__shared__ float partialSum[2 * BLOCK_SIZE]
int t = threadIdx.x;
int start = 2 * blockIdx.x * blockDim.x;
partialSum[t] = input[start + t];
partialSum[t + blockDim.x] = input[start + t + blockDim.x];
// reduction begin
for (int i = blockDim.x; i > 0; i /= 2) {
__syncthreads();
if (t < i) {
partialSum[t] = partialSum[t + i];
}
}
}