K-means算法
K-means算法
输入input:data X
输出output:data(X,S)
解释:输入没有标签的数据data X,经过训练,给每一个数据添上一个标签S{s1,s2,...,sk},对应的聚类中心为U{u1,u2,...,uk}。
效果:将输入数据分为k类,并得到其相应类别的中心点。
========================================================================================
step 1 初始化聚类中心(u1,u2,...,uk)
--- 采用随机从train data中选取k个样本点作为初始的聚类中心(u1,u2,...,uk);
-----------------------------------------------------------------------------------------------------------------------------------------------------------
step 2 进行最近邻归类和更新聚类中心的动作
--- 根据聚类中心,遍历所有样本点,以最近邻原则(样本点距离哪一个聚类中心近就归为哪一类),计算样本点 与所有聚类中心点的距离,选择最小距离的聚类中心,并归属为那一个类别;
--- 聚类完毕后,再次计算聚类中心,计算同一类中所有样本点的平均值作为新的聚类中心;
-----------------------------------------------------------------------------------------------------------------------------------------------------------
step 3 重复step 2 直到收敛为止即聚类不再发生变化为止。
-----------------------------------------------------------------------------------------------------------------------------------------------------------
收敛的条件是:S和U不再发生变化。
K-means理论推导过程
一个约定:如果x1≈x2的时候,我们可以很简单的利用 u ≈ x1 ≈ x2这样一个简单的标准进行聚类。
利用这个约定我们对数据集X{xn}进行聚类可以得到{S1,S2,...,Sk},同时对应的选择U{u1,u2,...,uk}。
这样我们可以利用平方误差形式的聚类误差提出一个最优化问题,其定义和推导过程如下图所示:

具体的推导思想就是先固定聚类中心,优化数据分类,方法就是最近邻思想;然后固定分类,优化聚类中心通过求解梯度最小的方式得到了聚类中心的最优解就是类别的平均值(mean);最优化问题的解决往往不是一步解析的,大多数时候是通过逐步迭代递推得到的,这类方法最终都要给出一个迭代终止或者递归终止的条件。而K-means的方法就是迭代终止条件就是聚类不再发生改变就对应了算法的收敛。
K-means实验结果
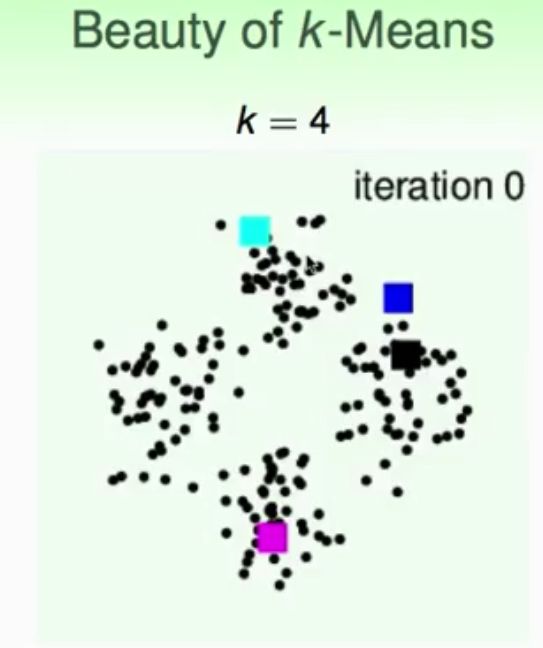
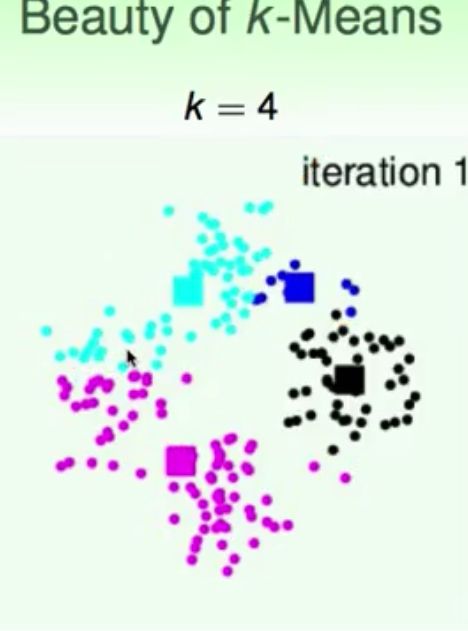
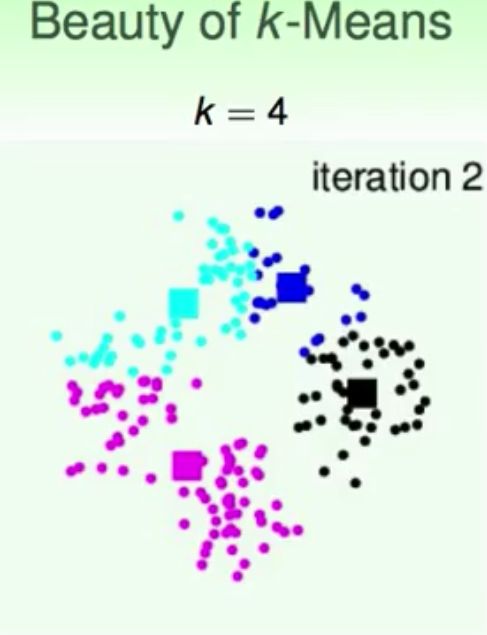

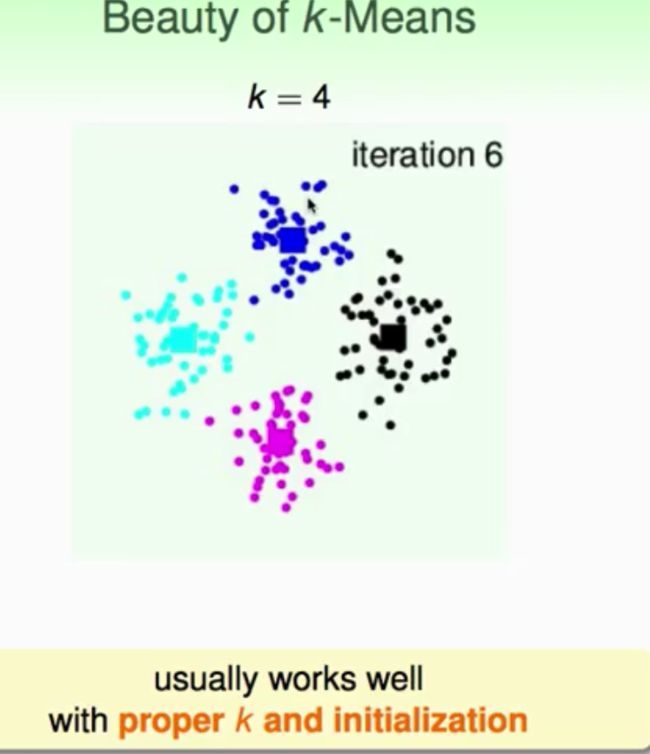

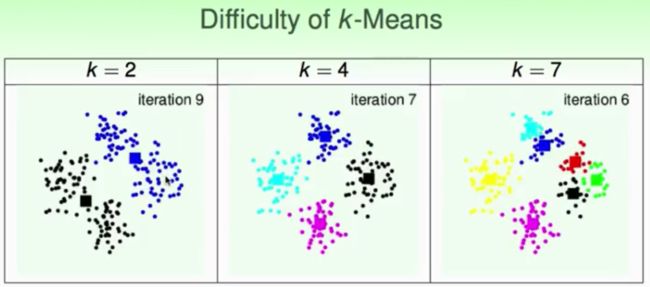

结果分析与说明:可以看到,k-means算法是一种非常有效的聚类算法,通常使用中需要注意的就是随机初始化聚类中的位置和设定的分类数K,从实验结果中可以看出k-means算法对这些初始化条件是比较敏感的。
*************************************************************************************************************************************
从上面的分析中可以总结,K-means算法是一种比较简单而且有效地聚类算法,在实际应用中是一种比较流行和常用的,其具体的代码实现也应当是简单朴素的。直观的从算法的名称中就能理解算法的核心。