项目分享-限流框架的实现
[置顶] 项目分享-限流框架的实现
目录(?)[+]
背景
开篇之前我一直在想怎么把这个项目给讲清楚,如果在互联网公司有高并发场景对于这个内容的就比较容易接受。这里大概说一下背景:代码写于2013年四月份,最开始的雏形是在2012年写的,从另外一个项目上进行,代码侵入性比较强。我在今年四月份进行了剥离,实现可插拔式的监控。言归正传,当时对于性能领域非常有兴趣,所以就在想如何写一个框架对于现有项目对于"类级别(严格来讲是方法级别)"做性能监控。既然是性能监控,很容易就会发现需要回答三个问题:一、这个方法的并发请求数有多少?二、响应时间是多少?三、最佳并发请求数是多少?这三个问题其实就会衍生出我们今天要讲的这个框架意义:保证应用的可用性,实时监控各个节点的并发数,响应时间等。(吞吐量和响应时间相生相克,所以会在两者之前找一个最佳平衡点,就是常说的最佳并发数。理想状态下最佳并发请求数就是我们这里要设的限流上限阀值)。
限流的意义
下面先用一个简单的图来看看限流框架所处在的位置。
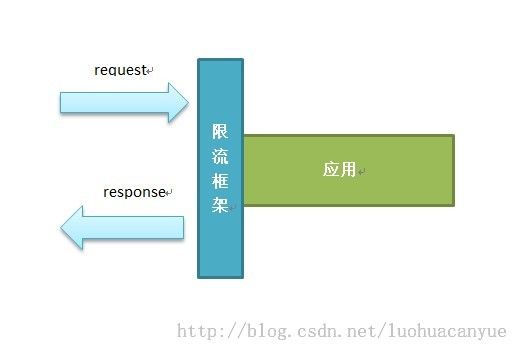
看到这张图的时候估计有很多人下意识的会想到Spring的拦截器,这里确实非常像,原理也类似。而且在我后面的实现中有两种方式:其中的一种就是基于Spring的拦截器实现的。另外一种其实是JDK的动态代理去实现的。讲到这里不知道有没有人会问为什么要限流?这里就做一些简单的解释。举一个浅显的例子:联想一下长江的三峡大坝,除了能发电之外另外一个作用就是防洪,如果洪水来了,没有三峡大坝,很有可能对于下游产生重大的洪涝灾害。引用到我们这里其实是一样的。当请求数异常升高时(洪水来了),对于应用来讲所承担的负载也会异常升高,这样直接的影响就是整个响应时间变慢,更糟糕的情况是系统直接崩溃。不仅如此,由于系统之前都是相关联的,所以很容易就会对其依赖的相关应用产生冲击(有点像多米诺骨牌)。限流的一个很重大的意义就是保证应用的可用性,讲到这里应该明白为什么需要限流了。
UML类图
接下来看一下整个UML类图:
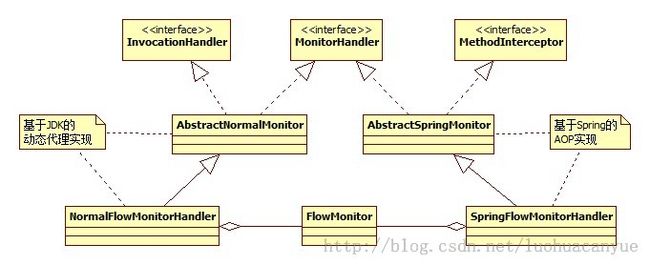
这个图是比较简单。在这里我把整个限流做了一些简化,在完整版里面会有数据的存储和响应时间的监控。开始的数据是存储在DB里面,后面为了学习数据库的一些核心知识所以自己在写一个很简单的存储(写存储的意义仅仅只是为了学习,只是希望了解一下整个存储在于空间分配的一些思想,对于SQL协议那一块没有更多的涉及)。这里将不在讨论有关于存储的细节。
回到上面这张图,如我前面所说的,我用了两种方式去实现:一种就是Spring的拦截器方式,另外一种就是JDK的Proxy方式。
代码展示
FlowMonitor类
- /**
- *限流的作用
- *实现一个缓冲队列,让一部分进入等待状态
- *区间监控
- *如果一个线程返回特别慢怎么办,比如在release之前抛了异常
- * @author 百恼 2013-04-11上午11:26:36
- *
- */
- public class FlowMonitor {
- //默认最大的并发数默认为100,可以配置
- private int maxFlowSize = 100;
- //最大并发数
- private int maxRunningSize = 0;
- //当前并发数
- private AtomicInteger runningSize = new AtomicInteger();
- //通过的数量
- private AtomicInteger passSize = new AtomicInteger();
- //失败的数量
- private AtomicInteger loseSize = new AtomicInteger();
- public FlowMonitor(){
- super();
- }
- public FlowMonitor(int maxFlowSize){
- this();
- this.maxFlowSize = maxFlowSize;
- }
- /**
- * 线程进入开关,即使这里用了一些Atomic类,这里仍然会有并发问题。
- * @return
- */
- public boolean entry(){
- //每个类中一个配置maxFlowSize
- if(maxFlowSize>0){
- if(maxFlowSize<=runningSize.get()){
- //已经超过最大限制
- loseSize.incrementAndGet();
- return false;
- }
- //并发数+1
- runningSize.incrementAndGet();
- if(runningSize.get()>maxRunningSize){
- //记录最大的并发数,有并发问题
- maxRunningSize = runningSize.get();
- }
- //记录通过的线程数
- passSize.incrementAndGet();
- }
- return true;
- }
- /**
- * 执行完后,并发数-1
- * @param key
- */
- public void release(){
- runningSize.decrementAndGet();
- }
- public AtomicInteger getRunningSize() {
- return runningSize;
- }
- public AtomicInteger getPassSize() {
- return passSize;
- }
- public AtomicInteger getLoseSize() {
- return loseSize;
- }
- public int getMaxRunningSize() {
- return maxRunningSize;
- }
- /**
- * 重置,可以分时段进行监控
- */
- public void reset(){
- passSize.set(0);
- loseSize.set(0);
- maxRunningSize = 0;
- }
- }
上面类中最核心的两个方法:一个是entry(),一个就是release()。entry()是在调用目标方法之前调用,release()是在调用目标方法之后调用。对于代码层面这里就不做太多的解读,代码里也有一些注释,估计学过Java的都能理解这上面所写的。在类的注释里面我写了几个问题:
第一个是实现一个缓冲队列。上面我的处理策略是一种最简单的方法:只要当前并发数大于当前所设定最大的并发数返回false,不做任何其他的处理。
第二个问题是如果在处理具体的逻辑的过程异常退出使得release()方法没有执行而导致当前监控的并发数不正常。所以这里需要一定的补救措施:可以实现一个队列,队列上每个节点都是一个并发请求,当执行entry()方法时,就会往队列上插入一个节点,然后当执行release()时就把这个节点移出,然后当发现这个并发请求异常(可以根据时间来判断,比如说超过5s还未返回就对它进行中断操作)就把这个节点移出。这样可以比较准确的监控到当前的并发数。
第三个问题是有关于监控数据的问题,目前来看只能监控几个数据:总的通过的数量,总的失败的数量,最大的并发数,当前并发数。如果我想实现这样一种需求:希望监控某一时间段的情况,这个意义在于一旦出现问题(比如说失败数量上升)我可以明显知道在哪个时间节点出了问题。而目前的实现方式下是无法做到的。在上面的类中我留了一个reset()方法,其意义就是为了实现分时间段进行监控提供一个重置几个参数的接口。
第四个问题是在这里我并不知道该方法的RT(响应时间:在这里就是执行完这个方法的时间)监控,这个也可以去实现。因为在此文中重点讲限流,所以不想讲太多有关于RT的的东西。各位有兴趣也可以自己去实现,原理也是一样:仍然是用拦截器来实现,具体的实现策略可以多种多样。
MonitorHandler类
- /**
- * TODO Comment of MonitorHandler
- * @author 百恼 2013-4-9上午10:16:43
- *
- */
- public interface MonitorHandler {
- public boolean before();
- public boolean after();
- }
AbstractSpringMonitor类
- /**
- * TODO Comment of AbstractSpringMonitor
- * @author 百恼 2013-4-9下午04:42:04
- *
- */
- public abstract class AbstractSpringMonitor implements MethodInterceptor,MonitorHandler{
- /* (non-Javadoc)
- * @see org.aopalliance.intercept.MethodInterceptor#invoke(org.aopalliance.intercept.MethodInvocation)
- */
- @Override
- public Object invoke(MethodInvocation method) throws Throwable {
- boolean result = before();
- if(result){
- try{
- method.proceed();
- }catch(Exception e){
- } finally{
- after();
- }
- }
- return null;
- }
- }
SpringFlowMonitorHandler类
- /**
- * 使用spring拦截器实现监控
- *
- * @author 百恼 2013-4-9下午06:36:24
- */
- public class SpringFlowMonitorHandler extends AbstractSpringMonitor {
- private FlowMonitor flowMonitor;
- /*
- * (non-Javadoc)
- * @see com.yuzhipeng.monitor.MonitorHandler#before()
- */
- @Override
- public boolean before() {
- if (!flowMonitor.entry()) {
- return false;
- }
- return true;
- }
- /*
- * (non-Javadoc)
- * @see com.yuzhipeng.monitor.MonitorHandler#after()
- */
- @Override
- public boolean after() {
- flowMonitor.release();
- return true;
- }
- public FlowMonitor getFlowMonitor() {
- return flowMonitor;
- }
- public void setFlowMonitor(FlowMonitor flowMonitor) {
- this.flowMonitor = flowMonitor;
- }
- }
上面贴出的两个类就是有关于Spring的方式来实现,因为这种方法是会在项目中也会用的比较多。另外一种有关于JDK动态代理的方法代码就不贴出来了,实现方式非常简单。