记一个文本分类系统的实现
基于信息检索课程,完成实现了一个文本分类系统,现记录一下整个实现过程。
文本分类以文本数据为分类对象,本质上是机器学习方法在信息检索领域的一种应用,可以继承机器学习领域的很多概念和方法,但同时也需要结合信息检索领域的特点进行处理。主要研究的方向是:文本分词方法、文本特征提取方法、分类算法。
本人主要使用了5种常用的分类算法,分别是kNN、Rocchio、NBC、SVM和ANN,对每种算法的结果进行了比较,使用了十折交叉验证绘制了各自的准确率曲线。由于本系统基于的搜狗语料库,是中文文本,因此使用的分词工具是Python实现的中文分词工具jieba。使用的特征提取方法是信息增益。
1、语料
选择搜狗语料库的Reduced版本,一共有9个类别每个类别1990篇文章。考虑到实现规模,从每个类别中选择了600篇文档一共5400篇文档作为训练样本。共有9个类别,标号对应如下:(搜狗语料类别– 分类标号 – 类别名称)
- C000008—— 1 —— 财经
- C000010—— 2 —— IT
- C000013—— 3 —— 健康
- C000014—— 5 —— 体育
- C000016—— 4 —— 旅游
- C000020—— 6 —— 教育
- C000022—— 7 —— 招聘
- C000023—— 8 —— 文化
- C000024—— 9 —— 军事
针对上述5400篇训练样本,首先使用jieba进行分词,共得到157269个词项。然后编写python程序,计算每个类别下的每篇文章的tf,得到所有文档集的倒排记录表。同时统计每个词项的df并计算idf保存到文件中供后续使用。
3、特征提取
对分词后得到的157269个词项,首先使用jieba工具的标签抽取函数,输入idf和停用词,得到初步的6445个候选特征。
接着使用信息增益(IG)这种特征提取方法,在候选特征中计算每个词项对9个类别的信息增益。信息增益计算如下: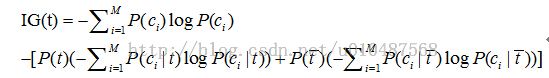
同时结合文档频率(DF)进行过滤,将小于DF小于5的词项过滤掉,然后设置IG的不同阈值得到不同阈值下特征,最终得出阈值为0.016,特征数目为967时分类效果最好。
4、向量化表示
根据上述得到的特征,对5400篇文档进行向量化表示,每篇文章都是一个967维的向量。第一种是使用tf(词项频率),分别计算出不同维数下的向量。第二种是使用tf-idf方式,对每篇文档的每个特征进行向量化,得到每个特征的tf-idf值。
5、分类器训练
所选择的五种分类算法中,kNN、Rocchio、NBC和ANN是使用python自行实现,SVM是使用python调用了libsvm程序实现。这写算法的具体实现在此不予赘述,具体可参考各类机器学习方法的书籍。
6、系统实现
最终基于python CGI实现了一个web应用系统,支持输入一个新闻url后,系统输入对应的分类结果,同时支持url文件上传进行批量分类。界面如下:

上传url文件后,分类结果显示如下:
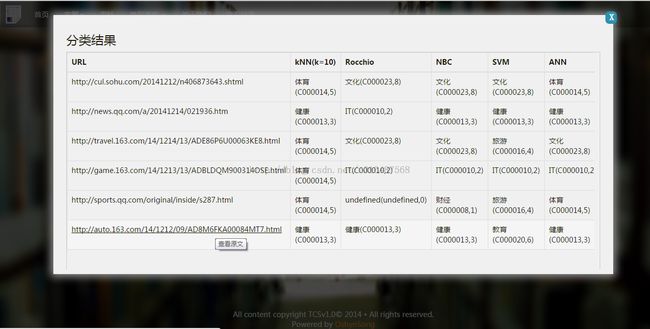
说明:分类url目前仅支持搜狐、腾讯、网易、新浪四个网站的新闻类页面的文章。
参考:
[1] Joachims, T. . Textcategorization with Support Vector Machines: Learning with many relevantfeatures. In Machine Learning[C]. ECML-98, Tenth European Conference on MachineLearning, 1998: 137--142.
[2] Wikipedia. Documentclassification [DB/OL].
http://en.wikipedia.org/wiki/Document_classification.2014
[3] Fandywang. 斯坦福大学自然语言处理第六课“文本分类(Text Classification)”[DB/OL].http://52opencourse.com/222/斯坦福大学自然语言处理第六课“文本分类(Text Classification). 2012.
[4] Li F., Yang Y. A LossFunction Analysis for Classification Methods in Text Categorization[C].International Conference on Machine Learning (ICML), 2003: 472-479.
[5] 申红,吕宝粮,内山将夫,井佐原均. 文本分类的特征提取方法比较与改进[J]. 计算机仿真, 2006, 23(3): 222-225