深度学习研究理解7:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
本文是MSRA何恺明研究员于14年撰写的论文,主要是把经典的Spatial Pyramid Pooling结构引入CNN中,从而使CNN可以处理任意size和scale的图片;这中方法不仅提升了分类的准确率,而且还非常适合Detection,比经典的RNN快速准确。
一:介绍
目前流行的CNN都需要固定size和scale的输入图片;所以基本上都是通过剪裁(crop)和wrap(这个不知道怎么翻译)。这种处理方式有三个弊端
1,剪裁的图图片可能不包含整个物体
2,wrap导致物体变形
3,当物体大小改变时,预定义的scale可能不适合物体的变化
CNN网络对于固定输入的要求,主要在全连接的分类器层,而特征提取层可以通过控制子采样比例和filter尺寸来调节,来接受各种scale和size的输入,得到固定的特征输出。
本文引入Spatial PyramidPooling 层SPP,通过SPP来移除CNN对于固定输入的要求,SPP操作类似深层的信息“融合”。这种深层的信息融合类似人脑的分级信息处理方式;当我们看到一个物体时,在一开始我们把物体看成一个整体而不是剪裁一个部分;通过融合先前处理的信息,大脑处理在深层阶段识别各种形状的物体。

SPP结构从细密和粗糙级别上分割图像,然后融合局部的特征。SPP有3个优势:
1,任任意size和scale输入下,产生固定的输出特征
2,使用多级spatial bins(多个尺寸的pooling),多级pooling对于物体形变具有鲁棒性。
SPP的优势,可以让我们:1,生产整个图片的特征,用于测试;2,允许我们在各种size和scale下训练网络,可以增加样本个数,防止过拟合。(类似数据增益)
二:SPP-net
SPP-layer
根据pooling规则,每个pooling bin(window)对应一个输出,所以最终pooling后特征输出由bin的个数来决定。本文就是分级固定bin的个数,调整bin的尺寸来实现多级pooling固定输出。
如图所示,layer-5的unpooled FM维数为16*24,按照图中所示分为3级,
第一级bin个数为1,最终对应的window大小为16*24;
第二级bin个数为4个,最终对应的window大小为4*8
第三级bin个数为16个,最终对应的window大小为1*1.5(小数需要舍入处理)
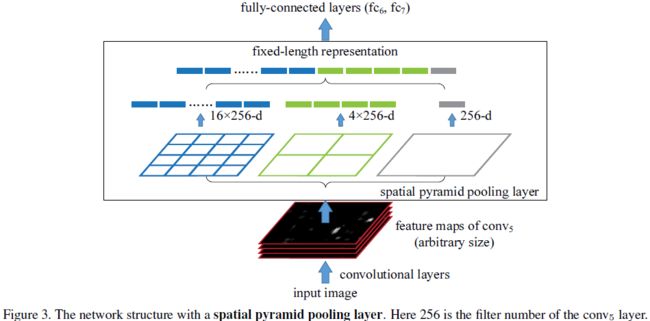
通过融合各级bin的输出,最终每一个unpooled FM经过SPP处理后,得到了1+4+16维的SPPed FM输出特征,经过融合后输入分类器。
这样就可以在任意输入size和scale下获得固定的输出;不同scale下网络可以提取不同尺度的特征,有利于分类。
训练SPP-net
单个size训练:
对于一个给定的size,可以预先计算SPP的bin窗口大小。Eg:unpooled FM size=a*a(13*13),n*n个bins。窗口的尺寸win=ceil(a/n)取整+1 ,间隔距离str=floor(a/n),取整。下图是一个13*13的unpooled FM,在3个级别,每个级别分别有9,4,1个bin;通过计算其对应窗口大小和间隔距离如下。

Multi-size 训练
把单个size中的224*224图片,缩小到180*180,而不是在原图上从新提取一个新的180*180的图片,这样可以保证两张图片内容一致。通过调整SPP的pooling 窗口和间隔距离得到相同的输出。
在训练中为了避免频繁更换网络的麻烦,采用先用224*224迭代训练一遍,然后复制参数用180*180的网络训练,如此循环。
三,实验结果
本文实在整个图片上取4个角和中心,进行网络训练(和Alex-net中在256*256上去法不同)。
本文采用的是以ZF fast作为基本框架,具体结构如下:
Input(224,224,3)→96F(7,7,3,2)→LRN→max-p(3,3,2)→256F(5,5,96,5)→LRN→max-p(3,3,2)→384(3,3,256,1) →384F(3,3,384,1) →256F(3,3,384,1) →max-p(3,3,2) →4096fc→4096fc-1000softmax
测试阶段采用10-view方法:

e2采用SPP-4,4个分级,分别为4*4,3*3,2*2,1*1 共计30维
e3采用SPP-6,,4个分级,分别为6*6,3*3,2*2,1*1 共计50维
结果分析:
1:(e1)获得了top-1 35.99%的错误率;比原论文中报告的38.4%降低了近3%,说明这种在原图像上截取224*224训练图片的方法比较好。
2:top-1,e3>e2>e1 ;top-5,e2>e3>e1;说明spp结构确实很有用,而且对比ZF-net,spp-4有更少的参数,最后一个特征层特征图,ZF为6*6=36,spp-4为30个,说明spp结构对于物体的空间位置和形变具有鲁棒性。
3:e4在180*180和224*224两种scale上训练网络,在224*224上测试分类,top-5结果达到了13.64%。所以multi-scale训练的方式很重要;根据ZF可视化论文中对平移和缩放不变形的探讨中,使用multi-scale可以增加网络对于平移和缩放的不变性。
4:e5,作者用原始整个图像(水平翻转)替换10-view中的连个中心剪裁图片,使得top-5达到了13.57%,这说明输入图片和物体的匹配程度确实影响分类结果(和OverFeat中使用offset和sliding window的原因相同,匹配的越好,分类月准确)
5:对比OverFeat中的fast和accurate两个模型对比来看,仅仅就分类来说,本文在没有采取更加复杂的网络情况下,没有使用sliding window和offset的情况下,利用一些相对简单的方法获得了较好的结果。
3.2 3.3在Pascal VOC 2007和Caltech 101上实验
通过在ImageNet上训练的特征提取器,应用在其他数据及上,在新的训练集上用SVM作为分类器,进行训练。作者刷新了这两个数据集VOC 2007上结果是80.1%,Caltech101上结果是91.44%
实验结果证明网络越深越好,SPP结构比一般的网络结构好;在全图上结构比剪裁的结果好;在不同比例上图片上训练会有不通过结果。说明卷积网络对于图像的scale有些敏感,SPPnet能够部分地解决问题。
四 SPP-net 用于检测
R-CNN用于检测,每张图片首先通过selective search找到2000个候选窗口,每个窗口缩放到227*227,然后输入到卷积网络提取每个window的特征。然后利用特征训练一个二元的SVM分类器来检测。
在整个图像上提取特征,然后在特征图上提取window,在window上进行Spatial Pyramid Pooling。这种方法只需要计算一次耗时的卷积过程,比R-CNN高效;OverFeat在检测时也是在特征图上采用offet pooling和sliding window 的方式,和本文的方法类似,但是OverFeat需要固定的window尺寸,但是spp结构则不需要固定大小的window。
4.1检测算法
在图片上通过selective search方法选择2000个候选window;利用spp-6网络在重置大小的整个图像上提取con-5特征。在每个window上用spp-6的pooling方式,每个window产生12800-d(256*50)。然后训练一个二元的SVM分类器。(后面的地方没怎么看懂,直接翻译了一部分;感觉没啥帮助,就等以后研究代码在补齐吧!)
同构spp来进行检测,可以通过multi-scale来改进效果,还可以通过模型平均来提升效果;总之通过spp-net的方法比R-CNN的方法要快很多,但是和OverFeat比较作者没有给出,此外本文是在VOC 2007数据集上做的测试,OverFeat实在ILSVRC 2013的数据集上做的测试。两种方法都是使用回归的方法来预测bounding box。
五 总结
Spp是一个处理multi-scale和multi-size灵活的方法,增加CNN的鲁棒性,提升分类效果。也同时证明一些经典的计算机视觉算法,在CNN中也是有用的。
一些想法和理解
SPP是一种可以提升CNN分类效果的实用方法,而且通过调整bin个数,还可以减少参数。感觉SPP结构使得最不同级别的bin对应的原始图像区域是不一样的,多个对应区域可以对应不同尺度的物体,从而使网络对于物体缩放的鲁棒性有所提升。感觉这个和GoogLeNet中的Inception多尺度提取信息,有些类似。通过调整filter或者pooling window的尺寸来调整每个激活值对应的区域,从而提取不同尺度的物体特征。
在ImageNet分类上,OverFeat中主要通过模型平均来得到好结果;而本文利用SPP结构可以让网络适合各种形状;和OverFeat中在测试阶段使用multi-scale,offsetmax-pooling 和sliding window方法不同的是,本文使用multi-scale方式来训练网络,使得网络本身具有很好的不变性。感觉OverFeat,通过充分发挥已经训练好模型的性能来提升效果,而SPP通过训练更好的模型来提升效果,而且感觉SPP模型参数更少,结果更好。此外,感觉本文在测试阶段使用multi-scale感觉还可以进一步提升结果(感觉作者应该意识到的,最后只用原图替换中心截取的图片,不知道作者为什么没有使用)。