快速理解 Omid: Yahoo在HBase上的分布式事务方案
作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
是什么
简单的说,OMID就是Yahoo构建在HBase上的一个分布式事务解决方案,用来拓展HBase所不支持跨行跨表级别的事务。其定位目标是OLTP类型的事务。类似的系统也有不少,他们或多或少都借鉴了谷歌的Percolator的思想,而omid则有较大的区别,具体区别在哪,下文详细分析。
以下关于Omid的理解主要参考Omid的各种文档和相关Paper,因为没有详细参考Omid的最新代码去比较文档描述的流程,所以如果理解有误的地方烦请指出
总体架构思想
同多数构建在类HBase的NoSql KV数据库上的分布式事务实现方案类似,OMID的总体思想是通过HBase提供的多版本数据支持,借助于MVCC来实现分布式事务,理论上只要是提供多版本数据支持的DataStore都能套用OMID的实现。与Percolator不同的是,Percolator通过BigTable自身存储锁信息进行两阶段提交来完成事务支持,而Omid的事务实现方式是基于中心服务器仲裁的无锁方案,下面具体看看他是怎么实现的。
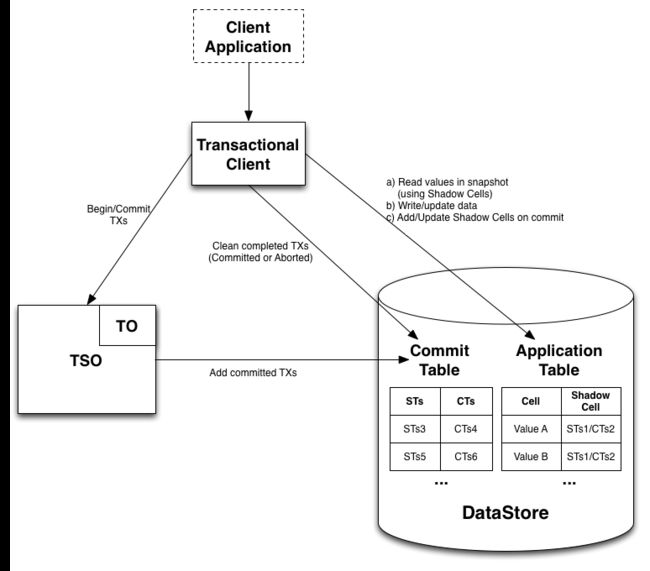
首先和多数MVCC方案一样,OMID需要一个TO(TimeOracle时间服务)来提供MVCC所需要的递增时间戳,在此基础上,OMID引入了一个全局的单点的TSO (TransactionStatus Oracle)来裁决事务冲突。客户端通过Transactional Client 客户端Library和HBase/TO/TSO进行交互,HBase本身不需要做修改。由于有全局仲裁服务来判断事务冲突,只要这个服务知晓所有数据历史上的变更过程,锁也就没有必要存在了。 一个事务的操作流程大体如下:
- Client通过Transactional Client请求开始一次事务操作,得到一个开始时间戳STs
- Client根据该时间戳读写数据,读数据后面说,写数据时每个单元Cell写的时候写入指定的STs Version时间错, 这一步保证不同的事务在写数据的时候不会冲突,也就是提供所说的无锁更新数据的能力。
- 数据写入完毕后,Client往TSO提交一个Commit请求,请求中包含了本次修改所涉及到的所有行的列表,TSO根据这些列表判断事务之间是否有冲突,而在Percolator类似的体系中,事务的冲突是由Client自己判断(因为有锁可以用来判断),如果成功,则返回一个事务提交的时间戳CTs
要判断事务冲突,首先看冲突的判定原则,基本思路就是如果事务的时间范围有交集,且提交的修改内容有交集,那么就认为事务是冲突的,反之,则认为事务之间没有冲突。
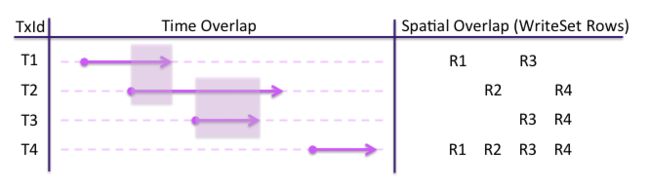
所以,上图中只有T2和T3两个事务之间是冲突的。其它的情况: T1和T2时间有交集但是修改内容没有交集,T1和T3修改内容有交集但是时间没有交集,T4和所有其它事务都有内容交集,但是时间没有交集。
TSO如何判断事务之间是否冲突,就需要看看 TSO内部的数据结构情况
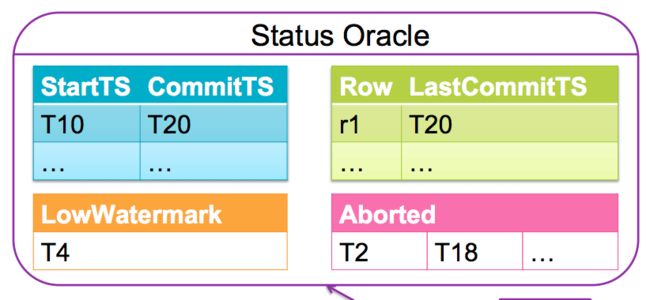
TSO内部有几个数据结构:
- 一个是事务开始时间戳 STs和事务提交时间戳CTs的映射关系表(Commit Table)。每个事务成功提交后都会增加一条STs和CTs的记录。
- 第二个是每个Cell最后一次成功提交的时间戳纪录,这个时间戳纪录称为冲突解决表(Conflict map)
TSO根据这个表来判断新的提交是否冲突,TSO根据待提交事务的STs来判断,如果存在行的STs小于冲突解决表里的行的最新提交纪录,那么说明有其他事务已经修改了该行的数据,进而判断事务存在冲突。
但是这个冲突解决表有一个很大的问题,就是容量。TSO不可能把历史上所有行的最新提交纪录都存储下来(那就约等于另一个Hbase集群的规模了。。。),尤其是在考虑到性能的情况下,这个冲突解决表最好还是能完全容纳在内存里的,所以这个表的结构,在OMID中是进行了阶段处理,仅仅保存了部分数据的。具体存储时对RowID进行Hash存储,一方面存在Hash碰撞问题,另一方面总容量尺寸也是受限的。当根据Hash进行线性索引选择位置时,没有可用空间,会替换掉表内最老的提交纪录。 总结下来,这种设计,一是可能造成False Conflict,二是由于数据变更纪录不全,可能会导致冲突检测时遗漏掉部分冲突的情况。
第一个问题,OMID假定发生的概率很低,不予处理(2014年的paper上对这部分内容完全没有提及,不知道是不是移除了Hash这一步算法),第二个问题,Omid引进了低水位这个概念来解决。
- lowWatermark 低水位
低水位存储的时一个时间戳信息,omid在每次Conflict Map里的最老的纪录被替换以后,会将对应的CTs替换原有的低水位时间戳信息,以后所有的事务提交,如果STs小于低水位,就会被直接舍弃,进入中断回滚流程。这种方式解决了前面说的漏判断的问题,但是也可能带来更多的误判的情况,对于这种情况引入的误判,OMID认为事务的时间跨度都不长,在一个事务很短的生命周期内,即使是在海量并发事务的的情况下,冲突判断表页足以保存对应时间周期内数据行的历史变更信息,所以误判发生的概率很低。(基本认为事务是秒级别的,也就是不涉及时间跨度超长的事务,实际上超长的事务,也会被OMID主动中断)
- 最后有一个Aborted的时间戳映射纪录的数据结构,主要原因也是应为Conflict Map被截断了,通过纪录被中断的事务,用来在读取数据的时候,判断特定版本的数据是否有效(因为数据本身不管有没有走commit流程,都已经写入到HBase中了。
- TSO判断事务成功的话,返回给Client该事务的STs- CTs,开始-提交时间戳映射。client将时间戳映射写入到每行数据的Shadow Cell里面,也就是每行数据额外附加的一个Column用来标识最新一次成功提交的数据。
前面说到事务中读取数据的判断,就是按照这个shadow Cell映射关系来处理的,应该是根据事务的起始时间戳,去寻找小于它的之前完成的事务的CTs,根据该CTs取得对应的STs(因为之前的事务的数据提交时间是CTs,但是实际写入到HBase的时间戳是STs),再根据该STs读取对应的数据,大概会是这样一个流程。之所以不能直接根据CTs去读Snapshot,会是因为可能存在同步改写的未完成的或者失败的事务的数据。
- 如果事务失败,client会回滚数据,也就是delete掉对应的HBase表里的STs版本的数据。
性能
TSO做为一个单点的存在,也就可能会变成整个系统的瓶颈,不管是容量上还是吞吐率上
实际上,Omid也是参考了之前的一些技术Paper的TSO的思想,主要的理论贡献也基本是解决单点的性能问题,如上面说的,一方面为了减少冲突解决表的容量采用的数据截断和引入低水位做辅助判断的解决方案,另一方面Omid做了一些额外的优化来改善吞吐率的问题,比如引入Commit Map和LowWatermark在Client端的只读缓存等,减少客户端和TSO的通讯开销。
小结:
总体感觉,为了实现无锁的分布式事务,Omid引入了一个TSO中心节点用来判断事务冲突,但是从效率上来说,冲突的事务的数据同样写了数据库,监测到冲突时,还需要回滚数据,所以效率上可能并不比Percolator通过Lock来处理冲突的机制来得高效。
不过,omid的出发点可能也不仅仅是因为效率,而是想规避Percolator的锁机制来带的无效锁清理的问题,没有锁就不需要清理了,同时也可以一定程度的规避将锁写入HBase带来的延迟,而中心节点的事务冲突判断机制,也有助于解决Locking方案中可能发生的锁竞争的问题。
但是实际实现中,事务交互逻辑上来说,还是会比较复杂,而在崩溃恢复机制上其实可能也不像Omid原先设想的那样比带锁的方案来得简单。 这一点从omid早期的ppt,到omid2014的paper,到omid最新的wiki文档,在事务冲突判断,在是否写入HBase附加数据等方面具体方案的的不断变更(比如shadow cell,之前paper上就明确说不往HBase写附加数据,减少一次交互,以提高效率,但是wiki上的实现文档则说使用了shadow cell来判断对应版本的数据是否是有效提交)在这种大的结构流程都出现了调整,显然是omid在实际工程实现中,效率,可靠性,可实现性等诸多因素影响下的结果
至于Locking V.S. Locking Free 哪种方案更优,没有经过大规模数据的实际业务验证比较,所以我也不能做出任何判断,单从理论上方案的完备性来说,个人还是略微倾向于Percolator的实现,但是2阶段提交各个Row之间上锁的顺序逻辑,如何减少互锁竞争等,具体实现时需要考虑的问题估计不少,这个相信小米在实现和使用Themis的时候会有所体会?
参考:
https://github.com/yahoo/omid/wiki
Paper: Omid: Lock-free Transactional Support forDistributed Data Stores
http://yahoo.github.io/omid/docs/hadoop-summit-europe-2013.pdf
相关系统
类似的在BigTable上实现分布式事务的方案,Percolator体系的,有兴趣的可以看我写的另一篇学习文档:Percolator Google的海量数据增量处理系统