期望 方差 协方差 协方差矩阵 (Expectation Variance Covariance)
在学习机器学习的算法时经常会碰到随机变量的数字特征,所以在这里做一个简单的总结。
1、 期望(Expectation)
离散: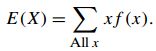
其中,f(x)为随机变量x的概率函数,事实上期望就是随机变量的平均数。
连续: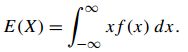
连续情况和离散的类似,只是把求和换成了积分。
求解关于自变量函数的期望的公式如下,其实自变量x的期望是r(x)=x的一个特例。
离散: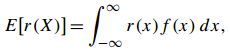
连续: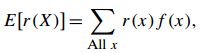
性质:
1. 如果Y=aX+b , E(Y)=aE(X)+b.
2. 如果x1, x2,…,xn为你个随机变量,![]()
2、 方差( Variance)
方差经常被用来度量数据和其数学期望之间的偏离程度,反映数据的分布结构,计算公式为:![]()
其中,μ=E(X),也可以用公式![]()
证明: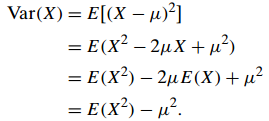
离散:![]()
性质:
1. 如果Y=aX+b ,![]()
2. 如果x1, x2,…,xn相互独立,![]()
3、 协方差(Covariance)
方差都是计算单一维度数据的统计特性,为计算多维数据,需要引入协方差。
![]()
其中,E(X)=μX, E(Y)=μY;也可以用公式![]() 计算。
计算。
证明:
协方差反应数据之间的线性相关性。如果协方差为正,表明两个维度的数据同时增加或减少;如果为负,表明一个维度的增加,另一个维度减少,反之亦然;如果为零,说明两个维度之间没有线性相关性。
离散:![]()
性质:
1. 如果X,Y为随机变量,![]()
证明:
2. ![]()
4、 协方差矩阵(Covariance Matrix)
在PCA中需要用到协方差矩阵,如果来看看什么是协方差矩阵,下面以三维数据为例:

需要注意的是,协方差矩阵中的每一个元素是表示的随机向量不同分量之间的协方差,而不是不同样本之间的协方差,上面公式中x,y,x分布表示一个数据的三个分量。
协方差矩阵有一些比较的特性:
1. 协方差矩阵是对阵矩阵
2. 协方差矩阵是半正定(非负定)阵
例子:给定10个三维数据,如何求协方差矩阵。
clc;clear; % produce ten data with three dimensions dataset = fix(rand(10,3)*10); dataset_m = bsxfun(@minus,dataset,mean(dataset)); cov1 = dataset_m' * dataset_m / (size(dataset_m,1)-1) cov2 = cov(dataset)