字节序及对堆栈的影响
何为大端序,小端序?
简单点说,就是字节的存储顺序,如果数据都是单字节的,那怎么存储无所谓了,但是对于多字节数据,比如int,double等,就要考虑存储的顺序了。注意字节序是硬件层面的东西,对于软件来说通常是透明的。再说白一点,字节序通常只和你使用的处理器架构有关,而和编程语言无关,比如常见的Intel x86系列就是小端序。
Big-endian(大端序)
数据的高位字节存放在地址的低端 低位字节存放在地址高端
Little-endian(小端序)
数据的高位字节存放在地址的高端 低位字节存放在地址低端
字节的高位与低位
举个例子,int a = 0x12345678 ; 那么左边12就是高位字节,右边的78就是低位字节,从左到右,由高到低,(注意,高低乃相对而言,比如56相对于78是高字节,相对于34是低字节)
地址的高端与低端
0x00000001
0x00000002
0x00000003
0x00000004
从上倒下,由低到高,地址值小的为低端,地址值大的为高端。
不同字节序如何存储数据?
看看两种方式如何存储数据,假设从地址0x00000001处开始存储十六进制数0x12345678,那么Bit-endian 如此存放(按原来顺序存储)
0x00000001 -- 12
0x00000002 -- 34
0x00000003 -- 56
0x00000004 -- 78
Little-endian 如此存放(颠倒顺序储存)
0x00000001 -- 78
0x00000002 -- 56
0x00000003 -- 34
0x00000004 -- 12
一个很好的记忆方法是,大端序是按照数字的书写顺序进行存储的,而小端序是颠倒书写顺序进行存储的。
编程判断大端序和小端序
方法一
bool IsBigEndian() { int a = 1 ; if ((( char * ) & a)[ 3 ] == 1 ) return true ; else return false ; }
打开VS的内存窗口,看一下a的存储方式,一目了然
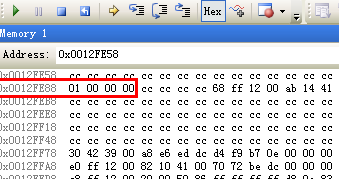
由于a是int,所以占四个字节,其值是00000001,存储方式如下。所以a[3]是0,不是大端序。一个更标准的写法是将a[3]替换为a[sizeof(int) - 1]。
0x0012FE88 01
0x0012FE89 00
0x0012FE8A 00
0x0012FE8B 00
方法二,使用union,原理见后面的面试题。
bool IsBigEndian() { union { unsigned short a ; char b ; } c; c.a = 0x0102 ; if (c.b == 1 ) return true ; else return false ; }
一道面试题
来道题巩固一下,下面代码输出什么?
union u { int i ; char x[ 2 ] ; } a ; int main(void) { a . x[ 0 ] = ' 1 ' ; a . x[ 1 ] = ' 2 ' ; cout << a . i << endl ; getchar() ; return 0 ; }
这个题,要看你使用的是什么系列的CPU,姑且假设是Intel系列的。Union是一个特殊的结构,其中所有成员共享结一个内存地址,任意时间只能存储一个成员,上面的Union大小为4个字节,所以上面的代码存储完字符1和2之后,Union的存储貌似应该是0x31320000,31和32分别是字符'1'和'2'的十六进制ASCII码(注意是字符1和2,而不是整数),但是Intel系列的CPU都是按照小端序存储的,所以,正确的顺序是0x00003231,对应的十进制数是12849,你答对了么?
==============================================================
大端、小端:
大小端是指CPU存储数据的方式,比如一个0x01020304这个整数,在WIN、Linux下在内存中的布局如下
[01][02][03][04] 注意左边是高地址,而右边是低地址
在UNIX下则是
[04][03][02][01] 注意左边是高地址,而右边是低地址
通俗的说,和WIN下的内存布局一致的就是小端,和UNIX下一致的就是大端。
其实在以前还出现过中端的的机型,不过这些机型也太“孤僻”了,已经落伍没人生产没人用了。
网络字节序:
其实是指网络传输的字节序,这个字节序可能是大端序或者小端序,这取决于软件开始时通讯双方的协议规定。
平时,如果有人说的网络字节序,那么大家就认为是大端序。
主机字节序:
是指主机处理数据时采用的字节序,虽然主机字节序和网络字节序是相对的概念,但是我们说主机字节序的时候,并不默认是之大端或者小端,而是结合机型来确定大小端的。
位序:
我们通常所说的字节序是指字节之间的关系,但是即使是一个字节中的某一位(bit)也是有排序的问题的。位序也有大端序,小端序,中端序,也还有其他的乱七八糟的位序的,但是都不常见。
开发的时候,我们是不用关心位序,编译器和CPU会自己处理这些事情。
算术运算与内存操作运算:
算术运算是不改变被运算数据的字节序的,此时我们不用关心所操作的数据到底是什么字节序的。但是内存操作运算就要注意了,比若我们将一个整数指针强制转换为一个字符指针类型,然后对字符指针类型的四个字节进行算数运算,此时我们必须知道是什么字节序。不然写出的代码要么是错误的,要么移植到其他机器的时候就不能正常运行。
常见的算术有+ - * / % & | ~ << >> = 等,请注意& | ~ << >> 这几个是算术运算而不是内存操作运算,所以他们进行混合运算的时候不用关心字节序或者位序问题。赋值运算符仅在数据类型兼容的时候才不涉及字节序问题,才能算作算术运算。
常见的内存操作运算有:强制转换后对碎片数据的算术运算,内存copy/write,读写文件等。
浮点数的字节序:
浮点数......我也不知道应该怎么处理其字节序问题,网上也查了很久但是没有很权威的答案。对于浮点数,我建议不要直接传内存值,按照字符串传输即可。
IP地址的字节序:
记住一条,IP地址的整数值,自IP地址生成的时刻起,就一定是网络字节序的,所以我们在转字节序的时候,IP 地址我们往往跳过对IP地址的字节序转换。呵呵,IP地址已经是网络字节序了,所以我们仅需要做算术赋值操作即可。
字节序转换函数:
OS一般都提供htons、htonl、ntohs、ntohl这四个字节序操作函数,这些函数的目的虽然相同,而且操作后内存布局也相同,但是从算术运算的角度来看这些函数的特性是与机型相关的:在WIN下这四个函数会改变所操作的数的数值,但是在UNIX下就不回改变数据的算术值,UNIX下这些函数是空操作。这个差别也可能是为什么UNIX服务器上程序的性能会高于WIN的一个小原因。
=========================================================
大小端与堆栈的生长方向
http://blog.csdn.net/wonengxing/article/details/8981789
问题:
1. 因为在目前的可执行代码结构中,堆栈总是由高地址向低地址生长,那么如果我定义一个临时变量a,它的地址是它所处块的高地址呢还是低地址?
2. 定义一个指针p指向a,如果p 加 1,p指向的地址是增加还是减少呢?
出现这两个问题的本质原因是因为堆栈的向下生长,令人产生了混淆。
根据测试:
1. 不论是在堆中申请变量还是在栈中申请变量,它的地址总是由该变量所处的低地址决定;
2. 问题2中的指针p加1,指向的地址会增加。
3. 这时再搀和大小端问题。我们假定机器为小端机。因为我们画堆栈时总是将高地址画在上端,然后将该变量在内存中的数据按照字节画在堆栈中;我们在观察一个变量的值的时候,却又往往以为上面是低地址,于是发现怎么变成大端了,这样就产生了一系列的混淆;其本质上还是小端,只是我们画堆栈的方式和理解数据存放的地址顺序的方式产生了一些颠倒而已。![]()
-------------------------------如何正确判断栈的增长方向???
栈的增长方向
版权声明:转载时请以超链接形式标明文章原始出处和作者信息及本声明
http://www.blogbus.com/dreamhead-logs/4840895.html
如何判断栈的增长方向?
对于一个用惯了i386系列机器的人来说,这似乎是一个无聊的问题,因为栈就是从高地址向低地址增长。不过,显然这不是这个问题的目的,既然把这个问题拿出来,问的就不只是i386系列的机器,跨硬件平台是这个问题的首先要考虑到的因素。
在一个物质极大丰富的年代,除非无路可退,否则我们坚决不会使用汇编去解决问题,而对于这种有系统编程味道的问题,C是一个不错的选择。那接下来的问题就是如何用C去解决这个问题。
C在哪里会用到栈呢?稍微了解一点C的人都会立刻给出答案,没错,函数。我们知道,局部变量都存在于栈之中。似乎这个问题立刻就得到了解答,用一个函数声明两个局部变量,然后比较两个变量的地址,这样就可以得到答案。
等一下,怎么比较两个变量的地址呢?
先声明的先入栈,所以,它的第一个变量的地址如果是高的,那就是从上向下增长。“先声明的先入栈”?这个结论从何而来?一般编译器都会这么处理。要是不一般呢?这种看似正确的方法实际上是依赖于编译器的,所以,可移植性受到了挑战。
那就函数加个参数,比较参数和局部变量的位置,参数肯定先入栈。那为什么不能局部变量先入栈?第一反应是怎么可能,但仔细想来又没有什么不可以。所以,这种方法也依赖于编译器的实现。
那到底什么才不依赖于编译器呢?
不妨回想一下,函数如何调用。执行一个函数时,这个函数的相关信息都会出现栈之中,比如参数、返回地址和局部变量。当它调用另一个函数时,在它栈信息保持不变的情况下,会把它调用那个函数的信息放到栈中。
似乎发现了什么,没错,两个函数的相关信息位置是固定的,肯定是先调用的函数其信息先入栈,后调用的函数其信息后入栈。那接下来,问题的答案就浮出了水面。
比如,设计两个函数,一个作为调用方,另一个作为被调用方。被调用方以一个地址(也就是指针)作为自己的入口参数,调用方传入的地址是自己的一个局部变量的地址,然后,被调用方比较这个地址和自己的一个局部变量地址,由此确定栈的增长方向。
给出了一个解决方案之后,我们再回过头来看看为什么之前的做法问题出在哪。为什么一个函数解决不了这个问题。前面这个大概解释了函数调用的过程,我们提到,函数的相关信息会一起送入栈,这些信息就包括了参数、返回地址和局部变量等等,在计算机的术语里,有个说法叫栈帧,指的就是这些与一次函数调用相关的东西,而在一个栈帧内的这些东西其相对顺序是由编译器决定的,所以,仅仅在一个栈帧内做比较,都会有对编译器的依赖。就这个问题而言,参数和局部变量,甚至包括返回地址,都是相同的,因为它们在同一个栈帧内,它们之间的比较是不能解决这个问题的,而它们就是一个函数的所有相关信息,所以,一个函数很难解决这个问题。
好了,既然有了这个了解,显然可以扩展一下前面的解决方案,可以两个栈帧内任意的东西进行比较,比如,各自的入口参数,都可以确定栈的增长方向。
狂想一下,会不会有编译器每次专门留下些什么,等下一个函数的栈帧入栈之后,在把这个留下的东西入栈呢?这倒是个破坏的好方法。如果哪位知道有这么神奇的编译器,不妨告诉我。我们可以把它的作者拉过来打一顿,想折磨死谁啊!
l