数据结构(复习)--------关于赫夫曼树和其编码
1、基本概念
a、路径和路径长度
若在一棵树中存在着一个结点序列 k1,k2,……,kj, 使得 ki是ki+1 的双亲(1<=i<j),则称此结点序列是从 k1 到 kj 的路径。
从 k1 到 kj 所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1.
b、结点的权和带权路径长度
在许多应用中,常常将树中的结点赋予一个有着某种意义的实数,我们称此实数为该结点的权,(如下面一个树中的蓝色数字表示结点的权)
结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘积。
c、树的带权路径长度
树的带权路径长度定义为树中所有叶子结点的带权路径长度之和,公式为:

其中,n表示叶子结点的数目,wi 和 li 分别表示叶子结点 ki 的权值和树根结点到 ki 之间的路径长度。
如下图中树的带权路径长度 WPL = 9 x 2 + 12 x 2 + 15 x 2 + 6 x 3 + 3 x 4 + 5 x 4 = 122
d、哈夫曼树
哈夫曼树又称最优二叉树。它是 n 个带权叶子结点构成的所有二叉树中,带权路径长度 WPL 最小的二叉树。
如下图为一哈夫曼树示意图。

2、构造哈夫曼树
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
如:对 下图中的六个带权叶子结点来构造一棵哈夫曼树,步骤如下:
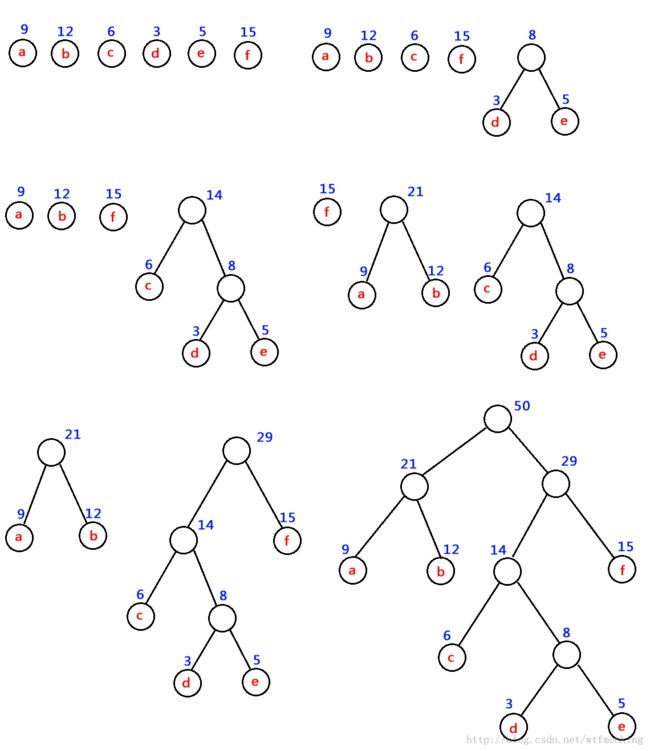
注意:为了使得到的哈夫曼树的结构尽量唯一,通常规定生成的哈夫曼树中每个结点的左子树根结点的权小于等于右子树根结点的权。
具体算法如下:
- //2、根据数组 a 中 n 个权值建立一棵哈夫曼树,返回树根指针 structint int struct sizeofstruct for
- sizeofstruct for
- int for
- if continue if break for
- if if elseif
- sizeofstruct
- return
- }
3、哈夫曼编码
在电报通信中,电文是以二进制的0、1序列传送的,每个字符对应一个二进制编码,为了缩短电文的总长度,采用不等长编码方式,构造哈夫曼树,
将每个字符的出现频率作为字符结点的权值赋予叶子结点,每个分支结点的左右分支分别用0和1编码,从树根结点到每个叶子结点的路径上
所经分支的0、1编码序列等于该叶子结点的二进制编码。如上文所示的哈夫曼编码如下:
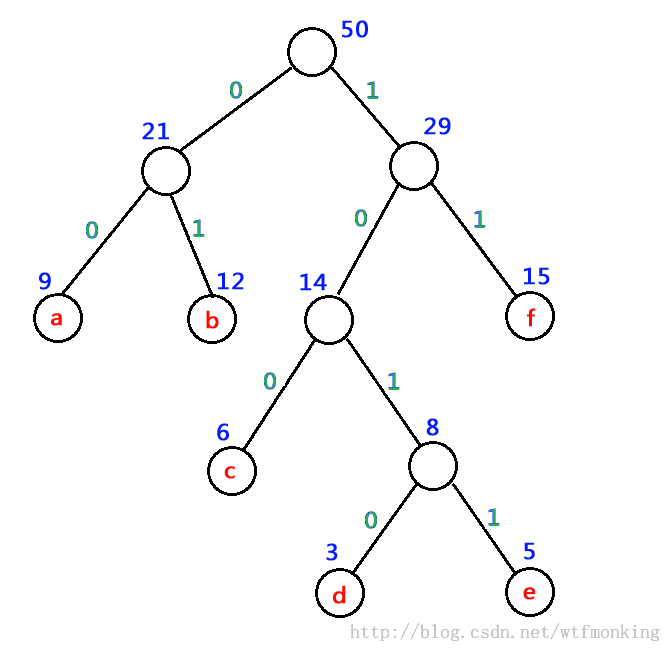
a 的编码为:00
b 的编码为:01
c 的编码为:100
d 的编码为:1010
e 的编码为:1011
f 的编码为:11
-------------------------------------------------------------------------------------------------------------------------------------------------------------
上述来自于:http://blog.csdn.net/yaoowei2012/article/details/18180769
--------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------------
主要是用自己的思维去构建一颗真实的赫夫曼树;将数组先排好序,
然后每次取前面两个元素相加得到分支点再将其插入到有序的数组中去;
----------------------------------------------------------------------------------------------------------------------------------------------------------
// // 关于数据结构的总结与复习 Coding
//关于二叉树的建立以及层次,其他遍历(递归,非递归)求深度等基本操作
//binary search tree ; balance binary tree ; bred and black tree ; huffmantree;
#include <cstdio>
#include <cstdlib>
//#define _OJ_
#define maxsize 100
static int code[30][30];
int t = 0;
typedef struct tree
{
int data;
struct tree *left;
struct tree *right;
} tree, *Bitree;
typedef struct stack1
{
Bitree *elem;
int base;
int top;
} stack1, *stack;
stack
Init_stack(void)
{
stack s;
s = (stack) malloc (sizeof(stack1));
s->elem = (Bitree*) malloc (sizeof(Bitree));
s->base = s->top = 0;
return s;
}
int
isempty(stack s)
{
if(s->base = s->top)
return 1;
else
return 0;
}
void
push(stack s, Bitree T)
{
if(s->top > maxsize) {
printf("栈已满:\n"); exit(1);
}
else
s->elem[s->top++] = T;
}
Bitree
pop(stack s)
{
if(s->top == s->base) {
printf("栈为空:\n"); exit(1);
}
else
return s->elem[--s->top];
}
Bitree
Creat_huffman(int a[], int n)
//用数组建立一颗赫夫曼树
{
int i, j, t;
Bitree *T;Bitree T1;
T = (Bitree*) malloc (100 * sizeof(Bitree));
for (i = 0; i < n; i++) {
for (j = 0; j < n - i - 1; j++) {
if(a[j] > a[j + 1]) {
t = a[j]; a[j] = a[j + 1]; a[j + 1] = t;
}//对数组进行排序待排完之后将其放置最后一个
}
T1 = (Bitree) malloc (sizeof(tree)); T1->left = T1->right = NULL;
T1->data = a[j]; T[j] = T1;
}
// ------------------------------------------------------------------
i = -1;
while (i < n - 2) {
T1 = (Bitree) malloc (sizeof(tree));
T1->left = T[++i]; T1->right = T[++i];
T1->data = T1->left->data + T1->right->data;
//已经排好序了则可以从最小的两个开始相加
for (j = i + 1; j < n; j++) {
if(T1->data < T[j]->data) {
for (int j1 = n; j1 > j; j1--)
T[j1] = T[j1 - 1]; break;
}//相加的结果作为新的数据插入数组其中
}
T[j] = T1; n++;
}
return T1;
}
void
huffman_coding(Bitree T, int len)
{
int i;
static int a[20];
if(T->left == NULL && T->right == NULL) {
printf("%d的赫夫曼编码为:\n", T->data); code[t][0] = T->data;
for (i = 0; i < len; i++) {
printf("%d", a[i]);
code[t][i + 1] = a[i];
}//第0个存入data数据第一个开始存入编码最后一个2用做结束的标志
code[t++][i + 1] = 2;
printf("\n");
}else{
a[len] = 0;
huffman_coding(T->left, len + 1);
a[len] = 1;
huffman_coding(T->right, len + 1);
}
}
int
deep_huffman(Bitree T)
//求huffman的深度(即为求二叉树的的深度一样)
{
int deep = 0, dept = 0, dept1 = 0;
if(T) {
dept = deep_huffman(T->left);
dept = deep_huffman(T->right);
deep = dept > dept1 ? dept + 1 : dept1 + 1;
}
return deep;
}
int
wpl_huffman(Bitree T, int len)
//求赫夫曼树的带权路径长度weight_path_length
{
if(T->left == NULL && T->right == NULL) {
return T->data * len;
}
else
return wpl_huffman(T->left, len + 1) + wpl_huffman(T->right, len + 1);
}
int main(int argc, char const *argv[]) {
#ifndef _OJ_ //ONLINE JUDGE
freopen("input.txt", "r", stdin);
//freopen("output.txt", "w", stdout);
#endif
Bitree T;
int i, j = 0, n;
int a[100];
scanf("%d", &n);
for (int i = 0; i < n; i++)
scanf("%d", &a[i]);
T = Creat_huffman(a, n);
printf("huffman_deep == %d\n", deep_huffman(T));
printf("wpl_huffman == %d\n", wpl_huffman(T, 0));
huffman_coding(T, 0);
int next[50], next1[50];
int max, l = 0;
for (i = 0; i < t; i++)
next[i] = code[i][0]; //将data给查询表
for (i = 0; i < t; i++) {
max = 0;
for (j = 0; j < t; j++)
if(next[max] > next[j])
max = j; //构建next1查询表以便从小到大开始输出
{next1[l++] = max; next[max] = 999;}
}
int i1;l = 0;
for (i = 0; i < t; i++) {
i1 = next1[l++]; printf("\n第%d个数的赫夫曼编码为:", l); j = 1;
while (code[i1][j] < 2)
printf("%d", code[i1][j++]);
}
return 0;
}
// int i, j;
// int a[100];
// for (i = 0; i < 26; i++)
// scanf("%d", &a[i]);
// Bitree T;
// T = Creat_huffman(a,26);
// huffman_coding(T, 0);
// int k, k1, k2;
// char str[20]; getchar();
// while (gets(str)) {
// // printf("%s\n", str);
// k = 0;
// while (str[k] != '\0') {
// // printf("k == %c\n", str[k]);
// if(str[k] == ' ') {printf(" ");k++;continue;}
// else {
// // next1[0] = 17;
// k1 = next1[str[k] - 'A']; // printf("k1 == %d", k1);
// k2 = 1;
// // printf("code == ");
// while (code[k1][k2] < 2)
// printf("%d", code[k1][k2++]);
// }
// k++;
// }
// // printf("ok");
// printf("\n");
// }
// 10111110101111011100
// 11111111101001010010111101110
// 11111111101001010010111101110 10111110101111011100