Loan default predictor(贷款违约预测)
Loan default predictor
(贷款违约预测)
--- dylan at 2014-3-16
一:背景
Kaggle发布了一个涉及贷款违约预测的比赛,时间周期2个月(2014/01/17 -- 2014/03/14)。 其实,之前kaggle很久之前有过关于贷款相关信用预测的比赛。但是,这次和上次的情况很不同,挑战也更大。传统的金融相关的算法,其实是个典型二分类问题,或者说就是预测用户是否违约,在金融风险领域二分类挑战是正负样本极不平衡。本次的比赛的目标是要求参赛者预测样本是否违约以及如果违约,违约的百分比是多少。所以,本次比赛可能让参赛者能设计出色的分类模型,也要能很好设计回归模型。
二:评估指标
说到评估指标值得提一下,本次比赛的评估指标是MAE,不是以往的RMSE,金融界貌似挺喜欢MAE来作为评估指标,MAE貌似能很好评估长尾。我们知道现在很多的模型,比如linear model用的是最小二乘来优化,random forest优化的是mse等,所以,如何找到一个优化mae的模型是本次的挑战。
MAE 评估指标如下:

三:训练集和测试集数据分布
训练集大约有10w个样本,loss= 0 / loss !=0 约等于 9:1
测试集大约有20w样本。
有780个左右的特征,其实,真正有用的特征不到200个左右,很多特征之间具有很强的相关性,有些特征在所有的训练样本上值都一样,这样的特征是没有用的。
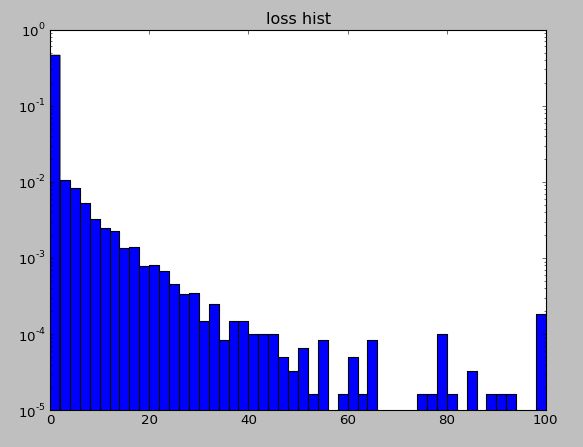
Loss值分布0-100,是数据集发布者对违约情况做了量化处理。
来看看loss分布,如Fig. 1,典型的长尾分布。如何预测长尾,同时不影响非长尾部门的预测精度是一直是学术界和工业界的难点。
Fig. 1 loss 直方图分布
四: 模型建立
整个预测模型分位2个部分: 分类预测和回归预测。第一步:分类预测,建立二值分类器,预测违约与否。第二步:在第一步基础上对那些已经预测是违约的样本,建立回归模型预样本违约量化值(1-100)。
4.1 分类模型
4.1.1 数据预处理
对那些loss >0 样本,目标值设为1.这样就构建了二分类数据集。
train_y_classify = np.asarray([1 if item > 0 else 0 for item in train_y])
4.1.2 特征提取
实验发现,有一个gold-feature对分类器auc的提高有个明显的提升,这些特征是f528 - f527 或着是f528- f274。f528,f527, f274几个特征具有明显的强相关性。这几特征其实就能让auc值达到0.9+。
X = np.array([datas[:,521] - datas[:,520]]).T
X =np.hstack((X,np.array([datas[:,521]+ datas[:,520]]).T))
X = np.hstack((X,np.array([datas[:,521]- datas[:,271]]).T))
X = np.hstack((X,np.array([datas[:,521] + datas[:,268]]).T))
X = np.hstack((X,datas[:,0:datas.shape[1]]))
对这些特征,我们最后根据重要性选取前150个特征。特征重要性计算方法:像randomforest, GBR模型都是能计算特征重要性的。
实验中,我用贪婪方式选取最大auc值得特征组合,但是发现在cv上效果反而降低了,所以后来就放弃这种特征选取方法了。
4.1.3 分类器模型
LogisticRegression 模型:
clf_model = LogisticRegression(penalty='l1', dual=False, tol=0.0001,C=1e20, fit_intercept=True, intercept_scaling=1.0,class_weight='auto', random_state=None)
GradientBoostingClassifier 模型:
clf_model = GradientBoostingClassifier(n_estimators=200, learning_rate=0.3,min_samples_split=30, min_samples_leaf= 5)
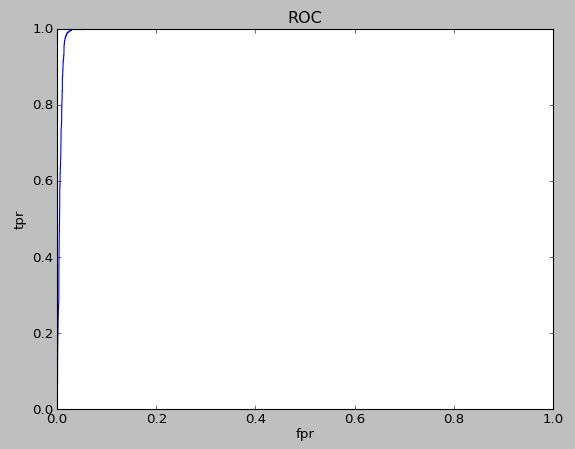
对于上面两个分类器模型, logistic regression auc值0.98左右, GBM分类器auc能达到0.997.
GBM ROC 曲线如下:
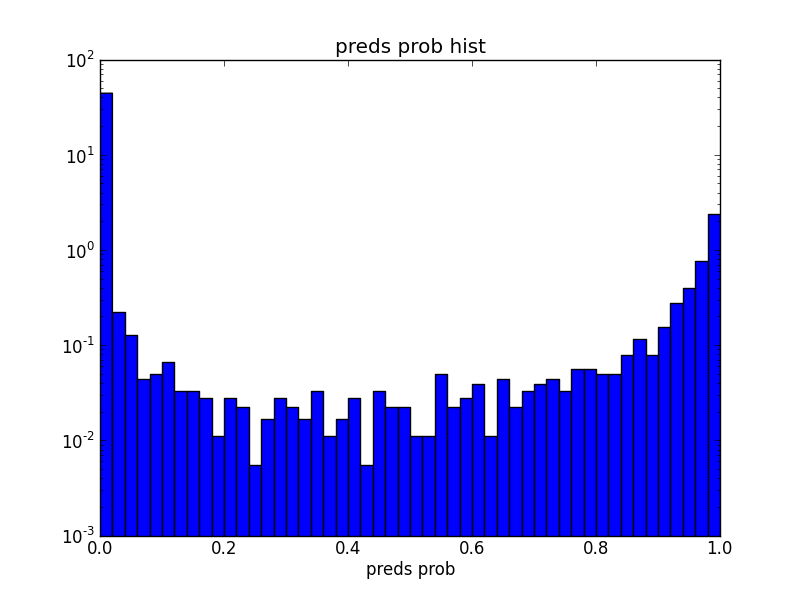
GBM 预测概率分布 曲线如下:
(注释: 看起来不像长尾分布)
4.2 回归模型
4.2.1 数据预处理
从原始训练集中取出用于回归模型的训练集: 把那些loss >0 样本作为本阶段的训练集,再加上少许loss =0 样本(主要是为了进一步降低上一步中分类器的错误)。
train_regressor_index = np.where(train_y >0)[0]
train_x_regressor = train_x[train_regressor_index]
train_y_regressor = train_y[train_regressor_index]
# add little y = 0 sampls;
y_zero_index = np.where(train_y == 0)[0]
zeor_sample_indx = random.sample(y_zero_index, 300)
train_x_regressor = np.vstack((train_x_regressor, train_x[zeor_sample_indx,]))
train_y_regressor = np.hstack((train_y_regressor, train_y[zeor_sample_indx]))
4.2.2 特征选取
X = np.array([datas[:,521] - datas[:,520]]).T
X = np.hstack((X,np.array([datas[:,521] + datas[:,520]]).T))
X = np.hstack((X,np.array([datas[:,521] - datas[:,271]]).T))
X = np.hstack((X,np.array([datas[:,521] + datas[:,268]]).T))
X = np.hstack((X,datas[:,0:datas.shape[1]]))
分类器特征和回归的特征是分开来计算的。
回归模型会取150个最重要的特征作为最后的特征。
4.2.3 模型
同样是采用GBM 模型。
regressor_model= GradientBoostingRegressor(n_estimators=200, learning_rate=0.1, min_samples_split=30, min_samples_leaf= 5, loss='lad')
值得提到是loss = 'lad', 因为本次评估目标是MAE,所以设定loss = 'lad'对最后的结果有很好的提升。
训练的时候,对目标值loss做一个log变换,这样会使结果mae值有一个0.01的提升(我的提交结果中没有包含这个变化,但是其他排在前面的参赛者采用该方法)。至于为什么? 有待研究。
还有值得一提的是,我不是直接对所有回归训练集对GBM训练,然后预测测试集,而是采用cv的方式来做预测,采用20级cv,每次取19/20回归训练集来训练,然后预测测试集。最后把取这20次cv预测结果的中值作为最后的测试集预测值,这种cv的方法能让mae值提升0.01。
五:预测结果
采用常用的5级cross-validation,没用采用对loss做log变换的前提下,我的cv结果大约是0.47,leaderboard结果是0.48526, 排名是39/677(一共提交26个结果),加上log变换的cv结果是mae=0.4619 , auc = 0.997, leaderboard的结果如下:

比赛结束后,loss加上log变换后:
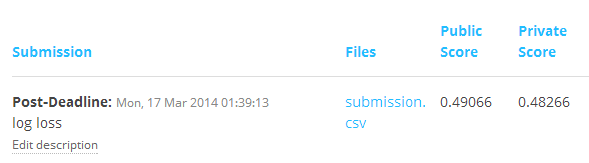
比赛结束前,我的结果:
Leaderboard 第一名成绩0.43732, baseline是0.833.
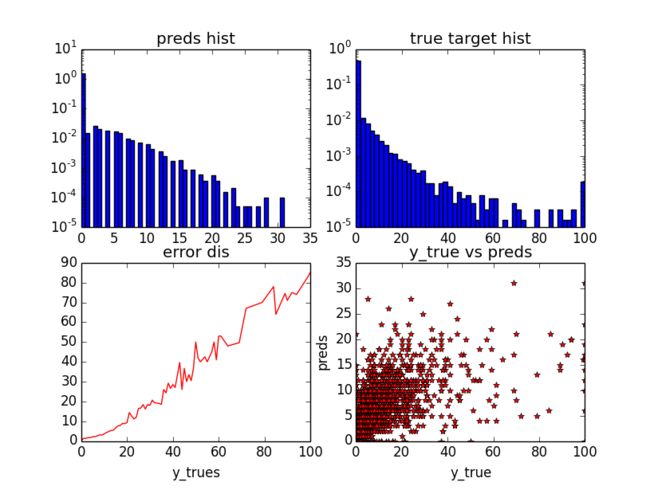
下面贴上实验结果(其中一个cv结果)如Fig. 2, 可以看到,我的模型在长尾预测上的效果并不好,同时,随着loss值得增加,误差呈现线性增长趋势。我曾经试过重采样的方法来降低长尾的误差,但是效果不理想,因为这个时候,长尾的误差是降低了,但是非长尾的部分结果变差了,导致最后的mae值变得更高。
Fig. 2 loan default 预测结果图
六:总结
通过这个比赛,我在分类方法和回归预测上的水平有了不错的提升,尤其是回归方法上。现在越来越觉得machine learning & data mining就是各种trick,有经验的人trick技巧就很丰富,比如,上面的提到对loss做log变换,然后再做回归。其实,对于本次比赛,数据是不平衡的,我曾经查阅过很多learning for imbalance data,上面提到的各种欠采样,重采样的技术,但是,我在这次的实验中,发现几乎对预测结果没什么帮助,反而让结果变得更差, what is happened? learning for imbalance data 是否靠谱?
七:参考文献
[1] http://www.kaggle.com/c/loan-default-prediction
[2] http://scikit-learn.org/
[3] Liang J. Predicting borrowers’ chance of defaulting on credit loans[J].
[4] Dmytro G, Katerina V. Loan Default Prediction in Ukrainian Retail Banking[R]. EERC Research Network, Russia and CIS, 2013.
[5] He H, Garcia E A. Learning from imbalanced data[J]. Knowledge and Data Engineering, IEEE Transactions on, 2009, 21(9): 1263-1284.
[6] Ting K M, Witten I H. Stacked Generalization: when does it work?[J]. 1997.
[7] Breiman L. Stacked regressions[J]. Machine learning, 1996, 24(1): 49-64.