Hadoop经典案例Spark实现(五)——求最大最小值问题
Hadoop经典案例Spark实现(五)——求最大最小值问题,同时在一个任务中求出来。
1、数据准备
eightteen_a.txt
eightteen_b.txt
结果预测
Reduce代码
Job提交
1、数据准备
eightteen_a.txt
102 10 39 109 200 11 3 90 28
eightteen_b.txt
5 2 30 838 10005
结果预测
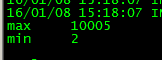
Max 10005 Min 2
2、MapRedue实现
Map代码
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxMinMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text keyText = new Text("Key");
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
if(line.trim().length()>0){
context.write(keyText, new LongWritable(Long.parseLong(line.trim())));
}
}
}
Reduce代码
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxMinReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
throws IOException, InterruptedException {
long max = Long.MIN_VALUE;
long min = Long.MAX_VALUE;
for(LongWritable val:values){// 10,20,8
if(val.get()>max){
max=val.get();//20
}
if(val.get()<min){
min = val.get();//8
}
}
context.write(new Text("Max"), new LongWritable(max));
context.write(new Text("Min"), new LongWritable(min));
}
}
Job提交
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobMain {
/**
* @param args
*/
public static void main(String[] args)throws Exception {
Configuration configuration = new Configuration();
Job job = new Job(configuration,"max_min_job");
job.setJarByClass(JobMain.class);
job.setMapperClass(MaxMinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setReducerClass(MaxMinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
Path path = new Path(args[1]);
FileSystem fs = FileSystem.get(configuration);
if(fs.exists(path)){
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
System.exit(job.waitForCompletion(true)?0:1);
}
}
3、Spark实现-Scala版本
val fifth = sc.textFile("/tmp/spark/fifth",3)
val res = fifth.filter(_.trim().length>0).map(line => ("key",line.trim.toInt)).groupByKey().map(x => {
var min = Integer.MAX_VALUE
var max = Integer.MIN_VALUE
for(num <- x._2){
if(num>max){
max = num
}
if(num<min){
min = num
}
}
(max,min)
}).collect.foreach(x => {
println("max\t"+x._1)
println("min\t"+x._2)
})
思路与Mr类似,先设定一个key,value为需要求最大与最小值的集合,然后再groupBykey聚合在一起处理。
结果与预期一样