日志收集之flume-ng源码分析
转自:http://blog.csdn.net/hpttlook/article/details/22760547
Flume-ng 源码分析
简介
近期由于项目需要开发独特的flume-source,因此简单看了下flume的源码。Flume的架构还是比较简单,各个模块功能源码比较清晰。
源码目录结构
flume-ng-channels
里面包含了filechannel和jdbcchannel的实现;没有追过早期的flume代码,不过从这目录结构看来,memorychannel并不在这个目录中,猜测file channel和jdbc channel是后期实现的功能;
flume-ng-clients
内部就实现了一个log4j相关的几个Appender,使得log4j的日志输出可以直接发送给flume-agent;其中有一个LoadBalancingLog4jAppender的实现,提供了多个flume-agent的load balance和ha功能,采用flume作为日志收集的可以考虑将这个appender引入内部的log4j中;
flume-ng-configuration
顾名思义,所有的配置均在此目录下。flume的配置设计的还是比较好的,内部在使用上抽象了ComponentConfiguration,多种角色(channel、channelselector、sink、sinkprocessor、source)都有自己的配置,因为flume的设计中在同一个process(flume-agent实例)中,可能会有多个source、sink、channel等角色,当配置多个source时,不同source会有自己的名字(component name)作为区分、会有自己的类型;阅读其他代码前,可以将conf的关系梳理清楚,有助于理解各个角色之间的关系;
flume-ng-core
flume整个核心框架,包括了各个模块的接口以及逻辑关系实现。其中instrumentation是flume内部实现的一套metric机制,metric的变化和维护,其核心也就是在MonitoredCounterGroup中通过一个Map<key, AtomicLong>来实现metric的计量。ng-core下几乎大部分代码任然几种在channel、sink、source几个子目录下,其他目录基本完成一个util和辅助的功能。
channel:
channel中实现了memorychannel;memory channel不提供数据可靠性,当agent down掉后,memory channel queue中的数据会丢失;在数据可靠性要求不高的情况下,可以使用。该目录下实现了重要的component:ChannelProcessor和ChannelSelector。对source暴露的可调用接口由ChannelProcessor的processEvent和processEventBatch完成。在ChannelProcessor处理前,会调用interceptor将一些用户配置的interceptor 对应meta信息(HOST\TIMESTAMP\STATIC\UUID等)放入到Event的header中。而ChannelSelector提供了两种实现:replicating和multiplexing:
replicating:将数据从source复制到多个channel中,每个channel有一份source的数据;
multiplexing:将数据根据配置的规则,将不同的消息路由到不同的channel中;所有channel的数据的集合为原始source的一份数据;
sink:
sink中实现了诸如:LoggerSink、NullSink、ThriftSink、AvroSink和RollingFileSink等。sink中出去最后的sink各种实现外,比较重要的几个component包括SinkGroup、SinkProcessor。其中SinkGroup表示可以将多个Sink组合到一起作为一个group,而group内的多个sink的工作行为由不同的sinkprocessor来控制,默认提供了三种SinkProcessor:
DefaultSinkProcessor:不配置processor时使用这种模式,此时SinkProcessor内部仅包含一个sink,无sinkgroup的概念;
FailOverSinkProcessor: 多个sink形成一个sinkgroup,group中只有一个sink出于active,消息由active的sink消费;配置多个sink时,需要配置每个sink的 priority,默认选用sink最高且可用的sink作为active sink;
LoadBalanceSinkProcessor:多个sink形成一个group,每次消费数据时,由OrderSelector选择某一个sink来消费数据,selector提供两种机制:random、round_robin。
Source:
Source中实现了基本的:Exec、Avro、Netcat、SequenceGenerator、SpoolDirectory、SyslogTcp、SyslogUDP以及ThrfitSource。对于source而言,唯一需要注意的是,一个source的数据可以发送到多个channel中(参考channel中的ChannelSelector描述)。
flume-ng-node
实现启动flume的一些基本类,包括main函数的入口(Application.java中)。在理解configuration之后,从application的main函数入手,可以较快的了解整个flume的代码。
Flume架构分析
通过上一节对各个模块的功能有了大致的了解,接下来理解整个架构就比较简单了。Flume从逻辑上来看,就分为如下三大模块:

这三者的关系为:
| Source { ChannelProcessor { Channel ch1 Channel ch2 … } } Sink { Channel ch; // only one channel for each sink! } SinkGroup { Channel ch; Sink s1;// failover or loadbalance strategy among these sinks Sink s2; … } |
Source: source负责产生数据,将数据“传入”到channel,一旦写入channel成功,source就认为数据已经可靠的传输。
Sink: sink不停的从属于自己的channel(此处有点类似于消息队列的消费者了)中获取数据,并且将数据写入到相应的后端中,如果数据写入失败则需要将相应的状况通知channel,让channel知道数据传输失败,下次获取时可以继续获取到这些数据;
Channel: 在flume的架构中,channel负责对数据提供可靠性保证。任何一种channel(memory,file,jdbc)都需要提供相应channel的transaction,保证实现如下几个操作:
doBegin: 事务开始;在source准备写入数据或sink准备读取数据之前调用;
doPut: 数据写入(生产者);由channelprocessor的processEvent或processEventBatch调用(rootcaller实际上是各种各样的source);
doTake: 数据读出(消费者);消费端(sink)调用,然后将数据做后端存储或转发处理;
doCommit: 数据操作(写入或读出消费)成功;
doRollback: 数据操作(写入或读出消费)失败,回滚;
doClose: 关闭事务;
三者之间简单的调用关系如下图:
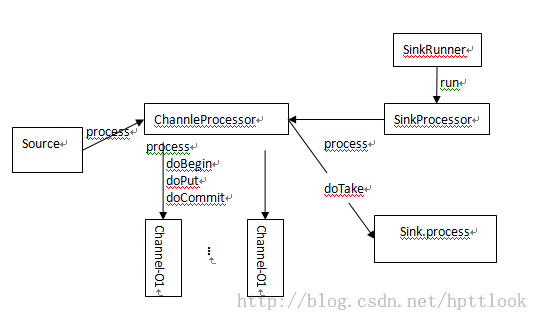
整个框架其实是以Channel为核心,source主动将数据写入到channel中,channel负责对数据提供持久化(file、jdbc channel),并提供读出操作(消费维护)。Sink也是主动的去channel获取数据,并作下一步处理。
Flume及类似系统对比
Flume的整个框架其实和消息队列的模型非常类似,source担任producer,sink担任consumer,而channel则担任broker的角色。其和消息队列的对比如下:
| 对比项 |
相同点 |
差异点 |
| Flume |
均提供消息的 produce-consumer功能(对于flume而言,单个process—包含source、channel、sink提供了mq类似的机制); 消息队列中的topic对应着flume中的channel(同一种消息数据); |
1、 Mq的consumer通常能够消费多个队列(或者topic)的消息;而flume的sink,只能从固定的channel获取; 2、 Mq一般可以较为方便的增加topic;broker等不需要做任何变更;而在flume的体系中,需要新增加相应的channel配置,然后增加相应的sink(consumer)配置; |
| 消息队列 |
总的说来,对于某个运行的flumeprocess(包含了source、channel及sink)而言,其类似于一个功能弱化版本的mq。在较为简单的应用中,比如只有几个系统的数据收集,可以采用flume来完成,flume体现了其轻量级的优势。但如果是有数十个甚至上百个个系统的数据需要收集时,此时用flume则其配置管理和新增加系统的数据收集较为麻烦,推荐使用消息队列(kafka、metaq、rocketmq)。
开发属于自己的Flume component
Flume的架构设计的比较好的一点,就是各个component基本都支持用户开发,在http://flume.apache.org/FlumeUserGuide.html的ComponentSummary章节中提到的component几乎都支持个性化开发。开发后直接在配置中配置即可使用。后续将分享项目中根据需要而开发的一个日志收集的source component。预先公布下此component的功能:
1、 可以直接监控配置的目录下的文件变化,将内容以增量方式传输;
2、 支持重启后的断点续传;
3、 支持传输正在写入文件;
4、 对目录无任何侵入性(flume自带的SpoolDirectory会将传输完毕的文件rename或delete);
5、 支持多行数据解析为一个record传输(当日志中包含Exception或者Error等信息时,往往会有换行符存在,此时应该将这些多行数据作为一个记录进行传输);
6、 能够自动适配log的rotate方式,避免重复传输;比如log4j的日志,采用RollingFileAppender时,当发生rotate行为时,实际上会执行一系列的rename操作,一般的日志传输监控软件不能处理这种状况;
最后,吐槽下csdn博客的格式,太难调了,而且超难看,看来还得继续寻觅免费的博客空间,有好的空间请朋友们介绍些,谢谢。
参考资料:
1、http://flume.apache.org/FlumeUserGuide.html