Heritrix架构简述
本文的目的,其实是希望通过对heritrix架构的分析,了解如何实现一个网络爬虫。
Heritrix的架构如图:
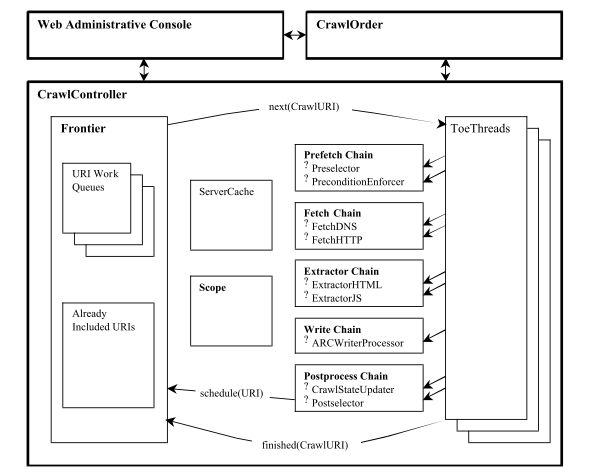
Web Administrative Console: 就是一个基于web的控制台。Heritrix内嵌了Jetty就是为了做这事。
CrawlOrder:这东西的名字有些奇怪。但其实就是一个crawl任务的配置。它是一个基于XML的object,Heritrix根据CrawlOrder中的配置,选择合适的模块来组装这次抓取任务的程序。而且,它还包括了一些很重要的信息,比如抓取任务的seeds,还有抓取url的范围,等等。
CrawlController:抓取的核心程序,它读取CrawlOrder来配置内部的模块和参数,Web Console也是和它做交互来控制爬虫。下面重点介绍Controller的内部:
Frontier:这个模块的名字也挺怪的,但它其实就是一个调度器,它内部有一个url队列,保存着需要去抓取的url。同时,从网页中提取到的url也会送给Frontier,所以,Frontier还有一个功能,对提取后的url进行去重。最后,Froniter进行调度,决定哪个url将被抓取,然后将这个url放入ToeThreads中;
ToeThreads:这组线程是真正的工作线程,它们完成url的抓取以及一系列的后续工作。整个过程又可以分为几部分:
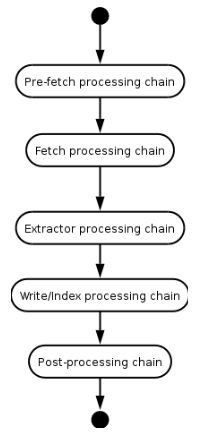
Pre-fetch Processing: 在抓取前的一些处理;
Fetch Processing: 抓取url对应的网页;
Extractor Processing: 抽取网页中的url,分析网页的信息。这个chain是经常需要改动的,因为不同的抓取任务需求都不一样,有一些可能不需要提取图片,有一些可能需要判断网页的内容是否发生改变。这些都可以通过配置或者改写Extractor来实现;
Write/Index Processing: 将网页保存下来,或者写入某个搜索引擎;
Post Processing: 后处理;
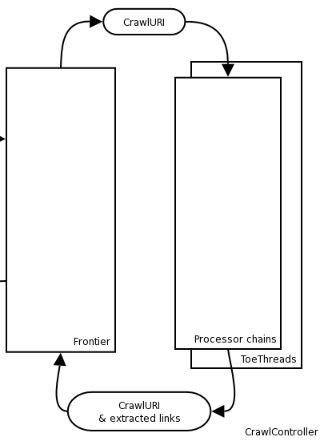
每一个从Frontier中调度出来的url都需要经历这些步骤。所以,在爬虫的运行过程中,Frontier和这些Processing Chain构成了一个环,Frontier将需要处理的url放入Processor Chain中,从Processor Chain中提取出的新的url再被放入Frontier中:
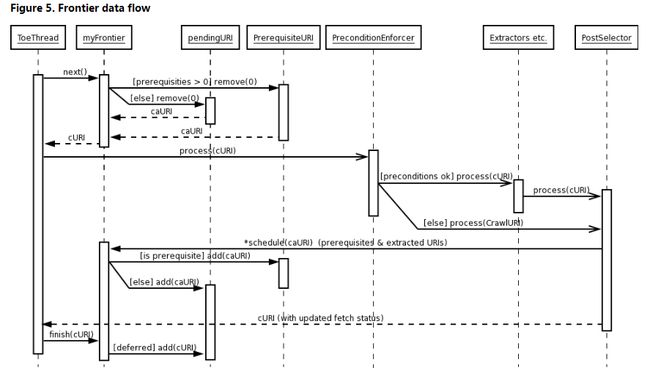
Froniter和Processing Chains的具体交互如下图:
Reference
1. An Introduction to Heritrix
2. Heritrix developer documentation
3. Heritrix User Manual