Java 中的字符集 (控制台,windows,linux)
看本文之前,请先弄清楚什么是unicode,utf8,utf16。不清楚请移步百度百科http://baike.baidu.com/view/40801.htm
Java的String内部有private final char value[] ,使用UTF-16编码来存储。也就是说,不管是什么样的字符串,只要是存储在String对象中的,就是UTF-16编码。
那我们读取的文件的字符集有很多种,怎么办呢。String有个构造函数String(byte[] bytes, String charsetName) ,从文件中读取了bytes后,可以用这个来指定bytes的字符集charset,Java会自动讲bytes从charset转化成UTF-16,然后存到String中。没有指定的话,那么使用系统默认的字符集。
接下来,还有一个问题是,如果我在源代码中写了这样的语句,如
String test="我是中文"
那么,是怎么处理的呢。
使用下面的代码测试:
- public class Test {
- public static void main(String args[]) {
- String test="我是中文";
- System.out.println(test);
- }
- }
- public class Test {
- public static void main(String args[]) {
- String test="我是中文";
- System.out.println(test);
- }
- }
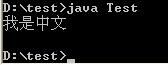
第一次,使用记事本写,保存。
javac Test.java
java Test
一切正常。
第二次,直接使用记事本,把文件另存为UTF8。


这个错误的原因是,记事本自作聪明地给文件前面多加了三个字节。用UE打开看就能看到了。
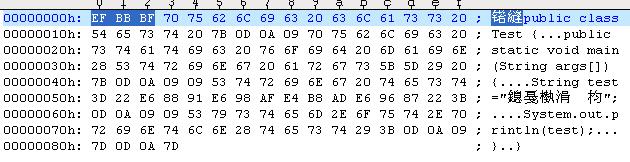
关于这个问题,google一下"记事本 UTF8 BOM"。前人已经写得很清楚了。
OK。我们使用UE将这三个字节删掉。然后
javac Test.java
java Test
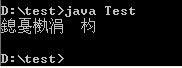
可恶的乱码出现了。
为什么会出现乱码呢?
javac Test.java做了这样的事,首先javac不知道文件的编码,因此使用系统默认的字符集(GBK),也就是说javac把UTF8编码的文件当成了GBK编码的文件。因此,当javac读到"我是中文"时,他看到的是这四个字的UTF8编码的二进制形式,但是他将这些当成GBK编码了。
于是,他就将这些bytes从GBK编码转化成UTF16的String对象(这是个错误的转化,因为得到的就不是"我是中文"的正确的UTF16编码了)。注意,转化完后还是可以得到二进制的字节,javac把这些保存在.class文件中。
这样呢,java Test运行时,输出的就是乱码了。
那么,如果使用java Test > temp.txt,然后用UE打开temp.txt,会看到什么呢?
恩,不是乱码,而是"我是中文"。
这又是为什么呢?
将"我是中文"的UTf8编码记为A
将A用GBK编码转化成的UTF16编码记为B
这样,B就是保存在.class中的内容
System.out做了什么事呢?他先将.class中的B从UTF16转化为GBK(系统默认编码)编码,这样得到了A。
然后把A传给控制台输出。控制台使用的编码也是默认的GBK,因为显示出来就是乱码了。
但是使用重定向后,temp.txt中保存的二进制字节正好是A。
当用UE打开后temp.txt,UE自动根据temp.txt的文件监测编码,发现是UTF8编码的二进制字节,因此使用的UTF8来显示,当然就正常了。(>_<记事本真的很弱)
最后,补充一点,对于源码中的非字符串 部分,javac先按文件的编码解析,然后将所有遇到的源码(除引号中的字符串外),都使用UTF8保存在class文件中。有兴趣的不妨自己打开class文件看看。
下面这个文件我用UTF8 保存:
- public class Test {
- public static void main(String args[]) {
- String 我是中文="我是中文";
- System.out.println(我是中文);
- }
- }
- public class Test {
- public static void main(String args[]) {
- String 我是中文="我是中文";
- System.out.println(我是中文);
- }
- }
然后我用javac Test.java,就报错了。

原因是,javac发现里面有非法的GBK编码。。。。。。呵呵,经常在Windows写代码,然后放到Linux下手动编译的,可能会觉得这个很熟悉吧。
因为Windows默认编码是GBK,Linux默认编码是UTF。
当你写一个GBK编码的Test.java,然后放到Linux下直接javac Test.java,如果文件中有中文的话,一般都会有错误。
建议,如果手动使用javac编译的话,尽量加上encoding选项,避免不必要的问题出现。
如:javac -encoding utf8 Test.java
其中utf8是Test.java文件的编码