从Trie树说到后缀树
参考了july的文章。
什么是Trie树
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点的所有子节点包含的字符都不相同。
在本科毕业设计(桌面搜索引擎)中,直接存储了各个字符串。实际上是可以使用字典树来减少空间开销的。
看下图:
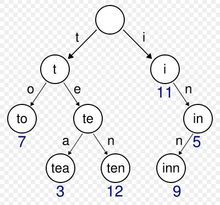
字典树就是利用前缀来减少空间开销和增加查找效率的。
------------------------------------------------------------------
字典树的建立也很简单。在向字典树中插入一个新的单词的时候,对于单词的每个字,查看是否在字典树中
1、不在,则创建一个节点,设置为这个字。
2、存在,则在节点上做上自己需要的信息记录即可。
------------------------------------------------------------
后缀树
对于字符串XMADAMYX,所有的后缀如下:
S[1..8], XMADAMYX, 也就是字符串本身,起始位置为1
S[2..8], MADAMYX,起始位置为2
S[3..8], ADAMYX,起始位置为3
S[4..8], DAMYX,起始位置为4
S[5..8], AMYX,起始位置为5
S[6..8], MYX,起始位置为6
S[7..8], YX,起始位置为7
S[8..8], X,起始位置为8
空字串,记为$。
那么他们的后缀树则如下图表示:
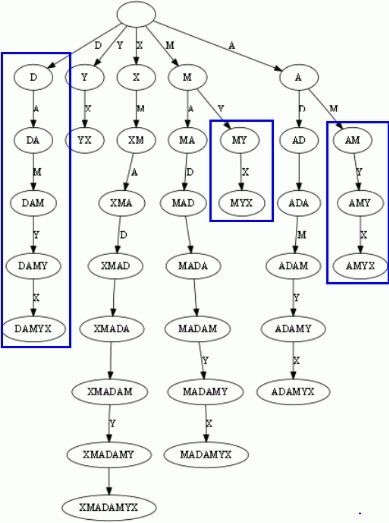
上图中蓝色标注的部分很容易看出来是有重复的。这样重复存储浪费了空间。需要优化。
如果我们允许任意一条边里包含多个字 母,就可以把这种没有分叉的路径压缩到一条边。另外每条边已经包含了足够的后缀信息,我们就不用再给节点标注字符串信息了。我们只需要在叶节点上标注上每 项后缀的起始位置。于是我们得到下图:
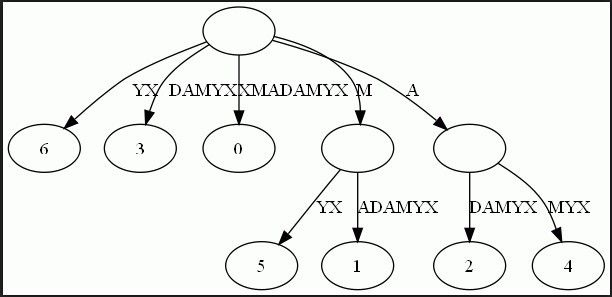
看了上图,可以发现X这个后缀丢失了。因为它正好是字符串XMADAMYX的前缀。为了避免这种情况,我们也规定每项后缀不能是其它后缀的前缀。要解决这个问题其实挺简单,在待处理的子串后加一个空字串就行了。例如我们处理XMADAMYX前,先把XMADAMYX变为 XMADAMYX$,于是就得到suffix tree--后缀树了,如下图所示:
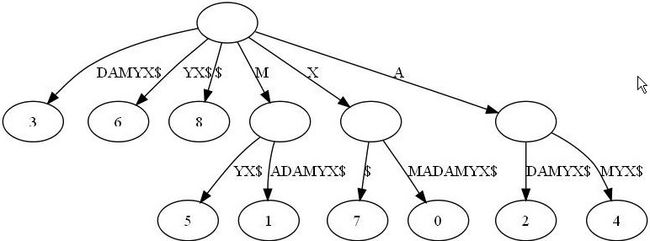
到此,后缀树就完成了。
-------------------------------
那么后缀树有什么作用呢?
比如说我们要找到字符串XMADAMYX中最长的“回文”,分析我们可以知道最长的是MADAM。
但是跟这里的后缀树有什么关系呢?
首先我们要看一下广义后缀树的概念:
广义后缀树(Generalized Suffix Tree)。传统的后缀树处理一坨(个)单词的所有后缀。广义后缀树存储任意多个单词的所有后缀。例如下图是单词XMADAMYX与XYMADAMX的广义后缀 树。注意我们需要区分不同单词的后缀,所以叶节点用不同的特殊符号与后缀位置配对。
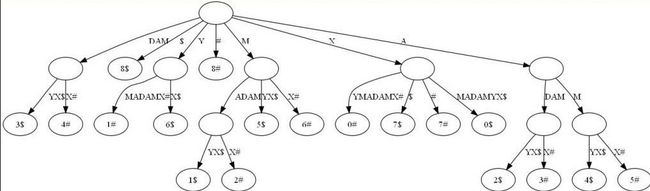
两个字符串的最长公共祖先:
两个字符串的最长公共祖先,意思是说,两个字符串的相同前缀,最长的那一个。
比如说,abcdefgh和abcdfgh,最长公共祖先就是abcd。
有了上面的概念,我们开始解决一个字符串的最长回文问题。
比如说XMADAMYX,假设我们已经找到了其最长回文是MADAM,那么D是回文的“中心”,以D为中心,最侧是DAM,右侧是DAM。
那么,把单词XMADAMYX翻转过来,变成XYMADAMX。
于是我们把寻找回文的问题转换成了寻找两坨后缀的最长公共前缀的问题。当然,我们还需要知道,到底查询那些后缀间的LCA。
很简单,给定字符串S,如果最长回文的中心在i,那从位置i向右数的后缀刚好是S(i),而向左数的字符串刚好是翻转S后得到的字符串S‘的后缀S'(n-i+1)。这里的n是字符串S的长度。
放在刚刚的列子中,就是,XMADAMYX和XYMADAMX,在求解最长公共前缀的时候,把相应位置的字符对齐,然后求两个字符串对齐位置的最长公共前缀即可。看下图,红色位置是对齐的位置。
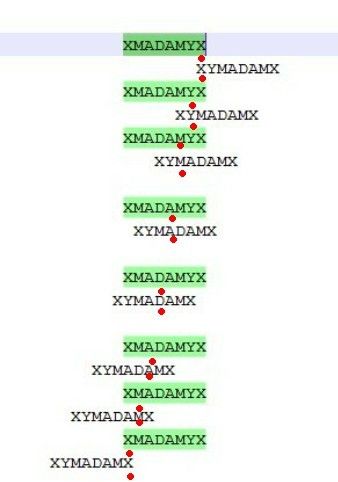
对于上图中的每一次对应,
第1次,最长公共前缀是1
第2次,最长公共前缀是1
第3次,最长公共前缀是1
第4次,最长公共前缀是1
第5次,最长公共前缀是3
第6次,最长公共前缀是1
第7次,最长公共前缀是1
第8次,最长公共前缀是1
综合上面八次考察,发现最长是3,并且回文中心是D。那么就可以从字符串之中直接得到最长回文是MADAM。
对单词XMADAMYX而言,回文中心为D,那么D向右的后缀DAMYX假设是S(i)(当N=8,i从1开始计数,i=4时,便是S(4..8));而对于翻转后的单词XYMADAMX而言,回文中心D向右对应的后缀为DAMX,也就是S'(N-i+1)((N=8,i=4,便是S‘(5..8)) 。此刻已经可以得出,它们共享最长前缀,即LCA(DAMYX,DAMX)=DAM。有了这套直观解释,算法自然呼之欲出:
1、预处理后缀树,使得查询LCA的复杂度为O(1)。这步的开销是O(N),N是单词S的长度 ;
2、对单词的每一位置i(也就是从0到N-1),获取LCA(S(i), S‘(N-i+1)) 以及LCA(S(i+1), S’(n-i+1))。查找两次的原因是我们需要考虑奇数回文和偶数回文的情况。这步要考察每坨i,所以这一步的复杂度是O(N) ;
3、找到最大的LCA,我们也就得到了回文的中心i以及回文的半径长度,自然也就得到了最长回文。总的复杂度O(n)。
经过上面的步骤,一个字符串中的最长回文就找到了。
------------------------------
创建后缀树的时间复杂度:O(n),具体参见july的博客