并查集/朋友圈
高级数据结构设计--并查集及实现学习笔记(有趣篇)
并查集的程序设计:

为了解释并查集的原理,我将举一个更有趣的例子。
话说江湖上散落着各式各样的大侠,有上千个之多。他们没有什么正当职业,整天背着剑在外面走来走去,碰到和自己不是一路人的,就免不了要打一架。但大侠们有一个优点就是讲义气,绝对不打自己的朋友。而且他们信奉“朋友的朋友就是我的朋友”,只要是能通过朋友关系串联起来的,不管拐了多少个弯,都认为是自己人。这样一来,江湖上就形成了一个一个的群落,通过两两之间的朋友关系串联起来。而不在同一个群落的人,无论如何都无法通过朋友关系连起来,于是就可以放心往死了打。但是两个原本互不相识的人,如何判断是否属于一个朋友圈呢?我们可以在每个朋友圈内推举出一个比较有名望的人,作为该圈子的代表人物,这样,每个圈子就可以这样命名“齐达内朋友之队”“罗纳尔多朋友之队”……两人只要互相对一下自己的队长是不是同一个人,就可以确定敌友关系了。
但是还有问题啊,大侠们只知道自己直接的朋友是谁,很多人压根就不认识队长,要判断自己的队长是谁,只能漫无目的的通过朋友的朋友关系问下去:“你是不是队长?你是不是队长?”这样一来,队长面子上挂不住了,而且效率太低,还有可能陷入无限循环中。于是队长下令,重新组队。队内所有人实行分等级制度,形成树状结构,我队长就是根节点,下面分别是二级队员、三级队员。每个人只要记住自己的上级是谁就行了。遇到判断敌友的时候,只要一层层向上问,直到最高层,就可以在短时间内确定队长是谁了。由于我们关心的只是两个人之间是否连通,至于他们是如何连通的,以及每个圈子内部的结构是怎样的,甚至队长是谁,并不重要。所以我们可以放任队长随意重新组队,只要不搞错敌友关系就好了。于是,门派产生了。
下面我们来看并查集的实现。
int pre[1000];
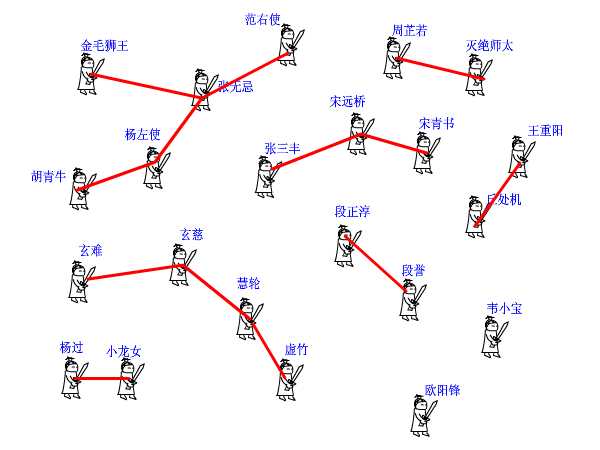
这个数组,记录了每个大侠的上级是谁。大侠们从1或者0开始编号(依据题意而定),pre[15]=3就表示15号大侠的上级是3号大侠。如果一个人的上级就是他自己,那说明他就是掌门人了,查找到此为止。也有孤家寡人自成一派的,比如欧阳锋,那么他的上级就是他自己。每个人都只认自己的上级。比如胡青牛同学只知道自己的上级是杨左使。张无忌是谁?不认识!要想知道自己的掌门是谁,只能一级级查上去。
find这个函数就是找掌门用的,意义再清楚不过了(路径压缩算法先不论,后面再说)。

再来看看join函数,就是在两个点之间连一条线,这样一来,原先它们所在的两个板块的所有点就都可以互通了。这在图上很好办,画条线就行了。但我们现在是用并查集来描述武林中的状况的,一共只有一个pre[]数组,该如何实现呢?
还是举江湖的例子,假设现在武林中的形势如图所示。虚竹小和尚与周芷若MM是我非常喜欢的两个人物,他们的终极boss分别是玄慈方丈和灭绝师太,那明显就是两个阵营了。我不希望他们互相打架,就对他俩说:“你们两位拉拉勾,做好朋友吧。”他们看在我的面子上,同意了。这一同意可非同小可,整个少林和峨眉派的人就不能打架了。这么重大的变化,可如何实现呀,要改动多少地方?其实非常简单,我对玄慈方丈说:“大师,麻烦你把你的上级改为灭绝师太吧。这样一来,两派原先的所有人员的终极boss都是师太,那还打个球啊!反正我们关心的只是连通性,门派内部的结构不要紧的。”玄慈一听肯定火大了:“我靠,凭什么是我变成她手下呀,怎么不反过来?我抗议!”抗议无效,上天安排的,最大。反正谁加入谁效果是一样的,我就随手指定了一个。这段函数的意思很明白了吧?
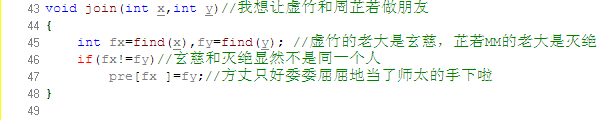
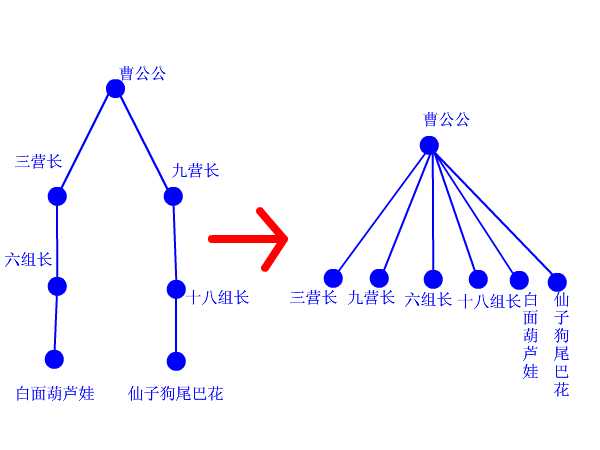
再来看看路径压缩算法。建立门派的过程是用join函数两个人两个人地连接起来的,谁当谁的手下完全随机。最后的树状结构会变成什么胎唇样,我也完全无法预计,一字长蛇阵也有可能。这样查找的效率就会比较低下。最理想的情况就是所有人的直接上级都是掌门,一共就两级结构,只要找一次就找到掌门了。哪怕不能完全做到,也最好尽量接近。这样就产生了路径压缩算法。
设想这样一个场景:两个互不相识的大侠碰面了,想知道能不能揍。
于是赶紧打电话问自己的上级:“你是不是掌门?”
上级说:“我不是呀,我的上级是谁谁谁,你问问他看看。”
一路问下去,原来两人的最终boss都是东厂曹公公。
“哎呀呀,原来是记己人,西礼西礼,在下三营六组白面葫芦娃!”
“幸会幸会,在下九营十八组仙子狗尾巴花!”
两人高高兴兴地手拉手喝酒去了。
“等等等等,两位同学请留步,还有事情没完成呢!”我叫住他俩。
“哦,对了,还要做路径压缩。”两人醒悟。
白面葫芦娃打电话给他的上级六组长:“组长啊,我查过了,其习偶们的掌门是曹公公。不如偶们一起及接拜在曹公公手下吧,省得级别太低,以后查找掌门麻环。”
“唔,有道理。”
白面葫芦娃接着打电话给刚才拜访过的三营长……仙子狗尾巴花也做了同样的事情。
这样,查询中所有涉及到的人物都聚集在曹公公的直接领导下。每次查询都做了优化处理,所以整个门派树的层数都会维持在比较低的水平上。路径压缩的代码,看得懂很好,看不懂也没关系,直接抄上用就行了。总之它所实现的功能就是这么个意思。
提到并查集就不得不提并查集最经典的例子:食物链。
POJ 1182 食物链
http://acm.pku.edu.cn/JudgeOnline/problem?id=1182
题目告诉有3种动物,互相吃与被吃,现在告诉你m句话,其中有真有假,叫你判断假的个数(如果前面没有与当前话冲突的,即认为其为真话)
这题有几种做法,我以前的做法是每个集合(或者称为子树,说集合的编号相当于子树的根结点,一个概念)中的元素都各自分为A, B, C三类,在合并时更改根结点的种类,其他点相应更改偏移量。但这种方法公式很难推,特别是偏移量很容易计算错误。
下面来介绍一种通用且易于理解的方法:
首先,集合里的每个点我们都记录它与它这个集合(或者称为子树)的根结点的相对关系relation。0表示它与根结点为同类,1表示它吃根结点,2表示它被根结点吃。
那么判断两个点a, b的关系,我们令p = Find(a), q = Find(b),即p, q分别为a, b子树的根结点。
1. 如果p != q,说明a, b暂时没有关系,那么关于他们的判断都是正确的,然后合并这两个子树。这里是关键,如何合并两个子树使得合并后的新树能保证正确呢?这里我们规定只能p合并到q(刚才说过了,启发式合并的优化效果并不那么明显,如果我们用启发式合并,就要推出两个式子,而这个推式子是件比较累的活...所以一般我们都规定一个子树合到另一个子树)。那么合并后,p的relation肯定要改变,那么改成多少呢?这里的方法就是找规律,列出部分可能的情况,就差不多能推出式子了。这里式子为 : tree[p].relation = (tree[b].relation - tree[a].relation + 2 + d) % 3; 这里的d为判断语句中a, b的关系。还有个问题,我们是否需要遍历整个a子树并更新每个结点的状态呢?答案是不需要的,因为我们可以在Find()函数稍微修改,即结点x继承它的父亲(注意是前父亲,因为路径压缩后父亲就会改变),即它会继承到p结点的改变,所以我们不需要每个都遍历过去更新。
2. 如果p = q,说明a, b之前已经有关系了。那么我们就判断语句是否是对的,同样找规律推出式子。即if ( (tree[b].relation + d + 2) % 3 != tree[a].relation ), 那么这句话就是错误的。
3. 再对Find()函数进行些修改,即在路径压缩前纪录前父亲是谁,然后路径压缩后,更新该点的状态(通过继承前父亲的状态,这时候前父亲的状态是已经更新的)。
核心的两个函数为:
int Find(int x)
{
int temp_p;
if (tree[x].parent != x)
{
// 因为路径压缩,该结点的与根结点的关系要更新(因为前面合并时可能还没来得及更新).
temp_p = tree[x].parent;
tree[x].parent = Find(tree[x].parent);
// x与根结点的关系更新(因为根结点变了),此时的temp_p为它原来子树的根结点.
tree[x].relation = (tree[x].relation + tree[temp_p].relation) % 3;
}
return tree[x].parent;
}
void Merge(int a, int b, int p, int q, int d)
{
// 公式是找规律推出来的.
tree[p].parent = q; // 这里的下标相同,都是tree[p].
tree[p].relation = (tree[b].relation - tree[a].relation + 2 + d) % 3;
}
而这种纪录与根结点关系的方法,适用于几乎所有的并查集判断关系(至少我现在没遇到过不适用的情况…可能是自己做的还太少了…),所以向大家强烈推荐~~
搞定了食物链这题,基本POJ上大部分基础并查集题目就可以顺秒了,这里仅列个题目编号: POJ 1308 1611 1703 1988 2236 2492 2524。
下面来讲解几道稍微提高点的题目:
POJ 1456 Supermarket
http://acm.pku.edu.cn/JudgeOnline/problem?id=1456
这道题贪心的思想很明显,不过O(n^2)的复杂度明显不行,我们可以用堆进行优化,这里讲下并查集的优化方法(很巧妙)。我们把连续的被占用的区间看成一个集合(子树),它的根结点为这个区间左边第一个未被占用的区间。
先排序,然后每次判断Find(b[i])是否大于0,大于0说明左边还有未被占用的空间,则占用它,然后合并(b[i], Find(b[i]) – 1)即可。同样这里我们规定只能左边的子树合并到右边的子树(想想为什么~~)。
POJ 1733 Parity game
http://acm.pku.edu.cn/JudgeOnline/problem?id=1733
这题同样用类似食物链的思想。
首先我们先离散化,因为原来的区间太大了(10^9),我们可以根据问题数目离散成(10^4)。我们要理解,这里的离散化并不影响最终的结果,因为区间里1的奇偶个数与区间的大小无关(这句话有点奇怪,可以忽略...),然后每次输入a, b,我们把b++,如果他俩在一个集合内,那么区间[a, b]里1的个数相当于b.relation ^ a.relation,判断对错即可。如果不在一个集合内,合并集合(这里我们规定根结点小的子树合并根结点大的,所以要根据不同情况推式子),修改子树的根结点的状态,子树的其他结点状态通过Find()函数来更新。
hdu 3038 How Many Answers Are Wrong
http://acm.hdu.edu.cn/showproblem.php?pid=3038
上面那题的加强版,不需要离散化,因为区间的和与区间的大小有关(和上面的那句话对比下,同样可以忽略之…),做法与上面那题差不多,只是式子变了,自己推推就搞定了。但这题还有个条件,就是每个点的值在[0, 100]之间,那么如果a, b不在一个子树内,我们就合并,但在合并之前还要判断合并后会不会使得区间的和不合法,如果会说明该合并是非法的,那么就不合并,同样认为该句话是错误的。
POJ 1417 True Liars(难)
http://acm.pku.edu.cn/JudgeOnline/problem?id=1417
并查集 + DP(或搜索)。
题目中告诉两种人,一种只说真话,一种只说假话。然后告诉m条语句,问是否能判断哪些人是只说真话的那类人。
其实并查集部分跟食物链还是相似,而且种类变少了一种,更容易了。我们可以通过并查集把有关系的一些人合并到一个集合内(具体方法参见食物链讲解)。
现在的问题转化为,有n个集合,每个集合都有a, b连个数字,现在要求n个集合中各跳出一个数(a或者b),使得他们之和等于n1(说真话的人数)。而这个用dp可以很好的解决,用f[i][j]表示到第i个集合和为j个的情况数,我们还用过pre[i][j]记录当前选的是a还是b,用于后面判断状态。方程为f[i][j] = f[i – 1][j – a] + f[i – 1][j – b], j >= a, j >= b。如果最后f[n][n1] == 1说明是唯一的情况,输出该情况,否则输出 “no”(多解算no)
注意点 :
1. 这题的m, n1, n2都有可能出现0,可以特殊处理,也可以一起处理。
2. 按上面的dp写法,f[i][j]可能会很大,因为n可以达到三位数。其实我们关心的只是f[i][j] 等于0,等于1,大于1三种情况,所以当f[i][j] > 1时,我们都让它等于2即可。
POJ 2912 Rochambeau(难)
http://acm.pku.edu.cn/JudgeOnline/problem?id=2912
Baidu Star 2006 Preliminary的题目,感觉出的很好,在并查集题目中算是较难的了。其实这题跟食物链完全一个磨子,同样三类食物,同样的互相制约关系。所以食物链代码拿过来改都不需要改。但这题有个judge,他可以出任意手势。于是我们的做法是,枚举每个小孩为judge,判断他为judge时在第几句话出错err[i](即到第几句话能判断该小孩不是judge)。
1. 如果只有1个小孩是judge时全部语句都是正确的,说明该小孩是judge,那么判断的句子数即为其他小孩的err[i]的最大值。如果
2. 如果每个小孩的都不是judge(即都可以找到出错的语句),那么就是impossible。
3. 多于1个小孩是judge时没有找到出错的语句,就是Can not determine。
ZOJ 3261 Connections in Galaxy War
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=3563
nuaa 1087 联通or不连通
http://acm.nuaa.edu.cn/acmhome/problemdetail.do?&method=showdetail&id=1087
两题做法差不多,都是反过来的并查集题目,先对边集排序,然后把要删去的边从二分在边集中标记。然后并查集连接没有标记的边集,再按查询反向做就可。第一题合并结点时按照题目要求的优先级合并即可。
这里介绍的并查集题目,主要都是处理些集合之间的关系(这是并查集的看家本领~~),至于并查集还有个用处就在求最小生成树的Kruskal算法中,那个是图论中求最小生成树的问题(一般这个难点不在于并查集,它只是用于求最小生成树的一种方法),就不在这里赘述了~~
分享来自Tina_Z_Y和czyuan 感谢两个牛人!