数据结构------哈夫曼数及哈夫曼编码
哈夫曼(huffman)树,又称最优树,是一类带权路径长度最短的树,有着广泛的应用。通过构造哈夫曼树来生成哈夫曼编码。哈夫曼编码使用的是不等长编码(ASCII为等长编码),通过不等长编码将出现频率高的字符编码比较短,频率高的字符编码长的方式来减少文本的长度。
一,哈夫曼树
首先理解一下什么是路径和路径长度。路径:从树中一个结点到另一个节点之间的边数构成这两个结点之间的路径。路径上变数之和称为路径长度。树的路径长度是指从根结点到每个结点的路径长度之和。带权路径长度指从该结点到树根之间的路径长度与权值的乘积。树的带权路径长度是指所有结点的带权路径长度之和。
1)哈夫曼算法,构造具有最小加权路径长度的扩充二叉树算法,称为哈夫曼算法
2)哈夫曼树,用哈夫曼算法构造的扩充二叉树称为哈夫曼树。
3)哈夫曼算法描述
步骤1:用给定一组权值{w1,w2,w3, .....,wn},生成一个有n二叉树组成的森林F={T1,T2,T3,.....Tn},其中每个二叉树是一个权值为wi的根结点。
步骤2:从F中选择两个权值最小的树,作为新树的左右子树,新树的权值为左右子树的权值之和。
步骤3:从F中删除这两个树,另将新的二叉树加入到F中。
步骤4:重复步骤2和步骤3,直至F中只包含一棵树为止。
可以通过下图形象的了解构造过程
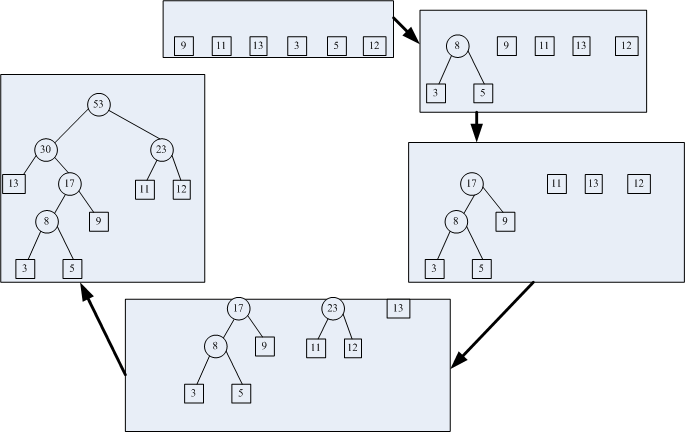
二,哈夫曼编码
假设上图中的值即为权值,13结点的权值,最大,如果进行存储,23结点对应的字符则必须存储多次,通过使用哈夫曼编码,通过不等长的编码,将权值大的编码短。如上图,左分支编码0,右分支编码1,则13编码为00,而3编码为0100,5编码为0101,这样便可压缩存储空间。
三,实现
将结点采用顺序存储。
/*
* =====================================================================================
*
* Filename: huffman.c
*
* Description:
*
* Version: 1.0
* Created: 2012年08月10日 05时11分04秒
* Revision: none
* Compiler: gcc
* Organization:
*
* =====================================================================================
*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
/*huffman树的存储结构,采用顺序存储 */
typedef struct {
unsigned int weight;/*权值*/
unsigned int parent,lchild,rchild;
}HTNode,*HuffmanTree;
#define MAX 10000
typedef char **HuffmanCode;/*存储哈夫曼编码*/
static int flag[20];
void Select(HuffmanTree T,int n,int* s1,int *s2)
{
int i=0,min=MAX;
for(i=2;i<=n;++i)
{
if((flag[i]==0)&&(T[i].weight<min))
{
*s1=i;/*记录最小值的索引 */
min=T[i].weight;
}
}
flag[*s1]=1;
min=MAX;
for(i=1;i<=n;++i)
{
if((flag[i]==0)&&(T[i].weight)<min)
{
*s2=i;
min=T[i].weight;
}
}
flag[*s2]=1;
}
void HuffmanCoding(HuffmanTree *HT,HuffmanCode *HC,int *w,int n)
{
int m,i,s1,s2,c,f,start;
char *cd;
HuffmanTree p;
if(n<=1)
return;
m=2*n-1;/*节点数,因为n个叶结点的哈夫曼数共有2*n-1个结点 */
*HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode));/* 从1下标开始存储 */
for(p=(*HT)+1,i=1;i<=n;++i,++p,++w)
{
p->lchild=p->rchild=p->parent=0;
p->weight=*w;
}/*初始化工作*/
for(;i<=m;++i,++p)
{
p->lchild=p->rchild=p->parent=0;
p->weight=0;/*初始化工作 */
}
for( i=n+1;i<=m;++i)/*开始创建huffman树,存放再n+1到m中*/
{
Select(*HT,i-1,&s1,&s2);/*从HT中找出最小两个权值 */
((*HT)[s1]).parent=i;
((*HT)[s2]).parent=i;
((*HT)[i]).lchild=s1;
((*HT)[i]).rchild=s2;
((*HT)[i]).weight=((*HT)[s1]).weight+((*HT)[s2]).weight;/*通过存储索引的方式来指向 */
}
/*从叶节点到根逆向求每个结点的huffman编码*/
*HC=(HuffmanCode)malloc((n+1)*sizeof(char*));
cd =(char*)malloc(n*sizeof(char));/*编码的存储空间*/
cd[n-1]='\0';
for (i=1;i<=n;++i)
{
start=n-1;
for(c=i,f=((*HT)[i]).parent;f!=0;c=f,f=((*HT)[f]).parent)
{
if(((*HT)[f]).lchild==c)
cd[--start]='0';/*左孩子编码为0 */
else
cd[--start]='1';/*右孩子编码为1 */
}
(*HC)[i]=(char *)malloc((n-start)*sizeof(char));/*将第i个编码存储到HC中 */
strcpy((*HC)[i],,&cd[start]);/*值复制给HC[i] */
}
free(cd);
}
int main()
{
int i=0;
HuffmanTree tree;
HuffmanCode code;
int w[8]={5,29,7,8,14,23,3,11};
HuffmanCoding(&tree,&code,w,8);
for(i=1;i<9;i++)
{
while(*(code[i]))
printf("%c ",*(code[i]++));
printf("\n");
}
free(tree);
free(code);
}
输出结果为:
0 0 0 1, 1 0, 1 1 1 0, 1 1 1 1, 1 1 0, 0 1, 0 0 0 0, 0 0 1, 二叉树结构为:
