目标检测(Object Detection)原理与实现(六)
基于形变部件模型(Deformable Part Models)的目标检测
上节说了基于cascade的目标检测,cascade的级联思想可以快速抛弃没有目标的平滑窗(sliding window),因而大大提高了检测效率,但也不是没缺点,缺点就是它仅仅使用了很弱的特征,用它做分类的检测器也是弱分类器,仅仅比随机猜的要好一些,它的精度靠的是多个弱分类器来实行一票否决式推举(就是大家都检测是对的)来提高命中率,确定分类器的个数也是经验问题。这节就来说说改进的特征,尽量使得改进的特征可以检测任何物体,当然Deep Learning学习特征很有效,但今天还是按论文发表顺序来说下其他方法,(服务器还没配置好,现在还不能大批跑Deep Learning ^.^),在第四节说了ASM并且简单的提了下AAM,这两个模型其实就是形变模型(deform model),说到基于形变模型检测物体的大牛,就不得说说芝加哥大学教授Pedro F. Felzenszwalb,Pedro发表很多有关基于形变部件来做目标检测的论文,并靠这个获得了VOC组委会授予的终身成就奖,另外它早期发表的《Belief propagation for early vision》也很出名,虽然比不上Science那样的开辟新领域的Paper,但在不牺牲精度的情况下大大提高了BP算法的运行效率,这个BP算法不是神经网络的BP算法,而是概率图模型里的推理求解方法(最大后验概率),它也被用在了后面要说基于霍夫推理的目标检测。貌似Pedro很擅长做这种事情,他的另外一篇论文《Cascade Object Detection with Deformable Part Models》也是不牺牲精度的情况下把基于形变部件做目标检测的效率提高了20倍,今天就来学习一下这种基于形变部件的目标检测。
基于形变部件的目标检测是现在除了深度学习之外的还相对不错的目标检测方法,先来看下为什么要使用形变部件,在(图一)中,同一个人的不同姿态,试问用前面几节中的什么方法可以检测到这些不同姿态的人?阈值不行,广义霍夫变换行吗?人的姿态是变换无穷的,需要太多的模板。霍夫森林投票?貌似可以,但是霍夫森立的特征是图像块,只适用于一些形变不大的物体,当图像块内的形变很大时同样不太适用。那么ASM可以吗?想想也是和广义霍夫变换一样,需要太多的均值模板。归根结底就是我们没有很好的形状描述方法,没有好的特征。而Pedro几乎每发表一篇论文就改进一下形状描述的方法,最终由简单的表示方法到语法形式的表示方法,其演化过程可以在参考文献[4]中看出,参考文献[4]是Pedro的博士论文。

(图一)
既然上节中的几种方法都不能解决大形变目标的检测问题,那基于形变部件的目标检测也该上场了。Pedro的五篇关于目标检测的顶级paper,小生就不一一说了,挑参考文献中的三篇学习一下。参考文献[1]、[2]、[3]分别讲述了如何利用形变模型描述物体(特征阶段)、如何利用形变部件来做检测(特征处理+分类阶段)、如何加速检测。首先来说下文献[1]的形变部件。在Deformable Part Model中,通过描述每一部分和部分间的位置关系来表示物体(part+deformable configuration)。其实早在1973年,Part Model就已经在 “Therepresentation and matching of pictorial structures” 这篇文章中被提出了。
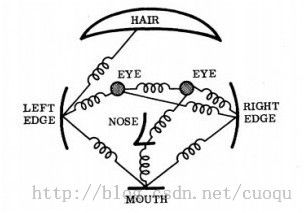
(图二)
Part Model中,我们通过描述a collection of parts以及connection between parts来表示物体。(图二)表示经典的弹簧模型,物体的每一部分通过弹簧连接。我们定义一个energy function,该函数度量了两部分之和:每一部分的匹配程度,部分间连接的变化程度(可以想象为弹簧的形变量)。与模型匹配最好的图像就是能使这个energy function最小的图片。形式化表示中,我们可以用一无向图 G=(V,E) 来表示物体的模型,V={v1,…,vn} 代表n个部分,边 (vi,vj)∈E 代表两部分间的连接。物体的某个实例的configuration可以表示为 L=(l1,…,ln),li 表示为 vi 的位置(可以简单的将图片的configuration理解为各部分的位置布局,实际configuration可以包含part的其他属性)。给定一幅图像,用 mi(li) 来度量vi 被放置图片中的 li 位置时,与模板的不匹配程度;用 dij(li,lj) 度量 vi,vj 被分别放置在图片中的 li,lj位置时,模型的变化程度。因此,一副图像相对于模型的最优configuration,就是既能使每一部分匹配的好,又能使部分间的相对关系与模型尽可能的相符的那一个。同样的,模型也自然要描述这两部分。可以通过下面的(公式一)描述最优configuration:
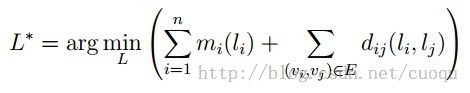
(公式一)
优化(公式一)其实就是马尔科夫随机场中的经典问题求解,可以用上面说的BP算法求解。说的理论些就是最大化后验概率(MAP),因为从随机场中很容易转换到概率测度中(gibbs measure),在这就不说那么复杂了,想系统的学习相关理论可以学习概率图模型(probabilistic graphical model)。识别的时候采用就是采用部件匹配,并且使得能量最小,这有点类似于ASM,但是ASM没有使用部件之间的关系,只是单纯的让各匹配点之间的代价和最小。匹配结果如(图三)所示:

(图三)
上面的方法没有用到机器学习,另外部件的寻找也不是一件容易的事情,因为首先要大概预估部件的位置,因此这个方法也有缺点,但这个形变部件的思想可以用来作为特征,接着就来看下Pedro的第二篇文献[2]如何用它来做目标检测。
Pedro在文献[2]中基于形变模型的目标检测用到了三方面的知识:1.Hog Features 2.Part Model 3. Latent SVM。
1. 作者通过Hog特征模板来刻画每一部分,然后进行匹配。并且采用了金字塔,即在不同的分辨率上提取Hog特征。
2. 利用上段提出的Part Model。在进行object detection时,detect window的得分等于part的匹配得分减去模型变化的花费。
3. 在训练模型时,需要训练得到每一个part的Hog模板,以及衡量part位置分布cost的参数。文章中提出了Latent SVM方法,将deformable part model的学习问题转换为一个分类问题。利用SVM学习,将part的位置分布作为latent values,模型的参数转化为SVM的分割超平面。具体实现中,作者采用了迭代计算的方法,不断地更新模型。
针对上面三条,我们可能有几个疑问:1、部件从何而来?2、如何用部件做检测?在基于部件做目标检测之前,赢得PASCAL VOC 2006年挑战的Dalal-Triggs的方法是直接用HOG作为特征,然后直接基于不同尺度的滑动窗口做判别,像一个滤波器,靠这个滤波器赢得短时的荣誉,但不能抗大形变的目标。Pedro改进了Dalal-Triggs的方法,他计算作为一个得分,其中beta是滤波器,phi(x)是特征向量。通过滤波器找到一个根(root)部件p0,根部件有专门的滤波器,另外还有一系列非根部件(parts)p1…pn,然后把他们组成一个星形结构,此时回顾(图一)的形变模型思想。每个部件用![]() 来表示,其中X,Y是坐标,L表示金字塔级别。当这个星形结构的匹配得分减去模型变化的代价得到最终分最高时,就完成了匹配,如(公式二)所示:
来表示,其中X,Y是坐标,L表示金字塔级别。当这个星形结构的匹配得分减去模型变化的代价得到最终分最高时,就完成了匹配,如(公式二)所示:
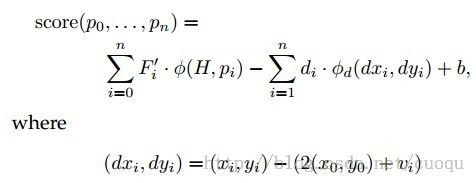
(公式二)
其中F’表示滤波器的向量化表示,b是偏移项,H表示特征金字塔。现在假设滤波器解决了部件,完成了匹配,解答了第二个疑问,但是滤波器从何而来,简单的说就是这个滤波器的权重beta是多少?现在不知道部件,也不知道滤波器,没有滤波器就没有部件,没有部件也求不出滤波器的参数,这就是典型的EM算法要解决的事情,但是作者没有使用EM算法,而是使用隐SVM(Latent SVM)的方法,隐变量其实就是类似统计中的因子分析,在这里就是找到潜在部件。在训练的时候对部分部件进行打标签,用他们求beta,然后用beta再来找潜在部件,因此使用coordinatedescent迭代求解,再一次遇到这个求解方法。有了部件和打分,就是寻找根部件和其他部件的结合匹配最优问题,可以使用动态规划,但很慢,具体请参考文献[2]。
在文献[2]中虽然使用了金字塔来加速搜寻速度,但是对星形结构组合的搜索匹配计算量也很大,检测速度稍慢。因此接着来看第三篇文献[3],文献[3]就是加速检测过程,对于星形结构模型采用cascade来判断,来快速抛去没有有效信息的part,其实实际中根部件的位置对匹配起着很大作用,然后依次对其他部件(n+1),有了这种关系,取一些部件子集后我们可以采用cascade来修剪、抛去一些不是好配置的部件组合(官方用语叫配置),这样一些在弱分类器中评分高的组合进入更一步的判断,类似于cascade的级联思想,但是要注意形变模型的每个部件应该是相关的,而不应该像上节那样harr-like特征之间独立,依次判断在这里行不通,这里其实是个子序列匹配问题,文献[7]提出过一种解决方法,pedro又改进了此方法,在原来n+1个部件的基础上增加n+1可以快速计算的简单部件,这样打乱之后,子序列匹配的代价就小了一些。
下面正式进入检测流程,看看怎么来加速的,大概流程如(图四)所示:

(图四)
其中各个notation含义如(图五)所示(特别注意p不是在上面说的部件,而是表示部件vi的贡献):

(图五)
基于部件检测的主题思想到此差不多了,但是还有更多的trick没有说,比如阈值选取、如何计算简单的部件等
检测效果如(图六)所示:
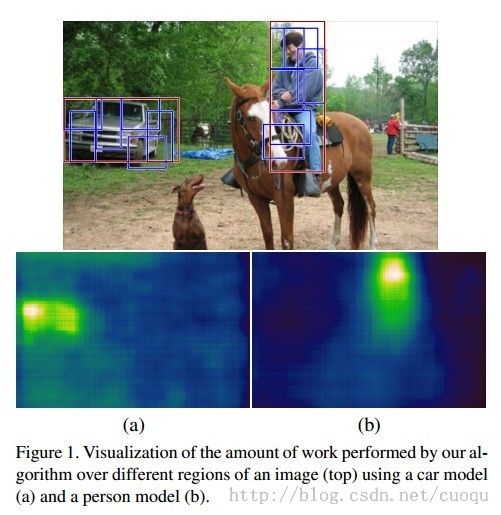
(图六)
这是一篇学习笔记式的“流水账”,难免有说错的地方,如发现请指出,谢谢。本节所有的文献代码都集成在一起挂在pedro主页上。
参考文献:
[1] Pictorial Structures for Object Recognition. Pedro F.Felzenszwalb
[2]Object Detection with Discriminatively Trained Part Based Models.Pedro F. Felzenszwalb
[3]Cascade Object Detection with Deformable Part Models. Pedro F.Felzenszwalb
[4]From RigidTemplates To Grammars: Object Detection With Structured Models. Pedro F.Felzenszwalb
[5]Histogramsof oriented gradients for human detection. N. Dalal and B. Triggs
[6] http://bubblexc.com/y2011/422/
[7]A computational model for visual selection.Y. Amit and D.Geman
转载请注明来源:http://blog.csdn.net/cuoqu/article/details/9244193