task_struct解析(三) 进程id
task_struct 中有这么几个和进程ID有关的字段
- pid_t pid;
- pid_t tgid;
- ....
- struct pid_link pids[PIDTYPE_MAX];
pid和tgid是表示该进程的全局进程ID的,前者是当前进程的ID号,后者是当前进程所在线程组的线程组ID。
而后者则是指向PID哈希表的链接,里面存储了命名空间相关的信息。
1、进程命名空间
Include/linux/Pid_namespace.h里有pid_namespace的定义:
- struct pid_namespace {
- struct kref kref;
- struct pidmap pidmap[PIDMAP_ENTRIES];
- int last_pid;
- struct task_struct *child_reaper;
- struct kmem_cache *pid_cachep;
- unsigned int level;
- struct pid_namespace *parent;
- #ifdef CONFIG_PROC_FS
- struct vfsmount *proc_mnt;
- #endif
- #ifdef CONFIG_BSD_PROCESS_ACCT
- struct bsd_acct_struct *bacct;
- #endif
- };
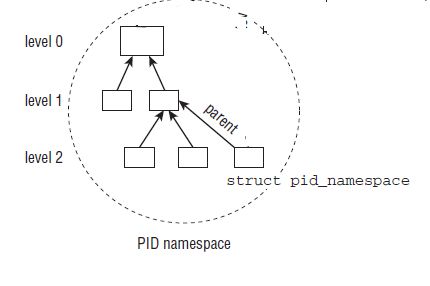
我们这里只关心其中的child_reaper,level和parent这三个字段
child_reaper:指向的是当前命名空间的init进程,每个命名空间都有一个作用相当于全局init进程的进程。
level:代表当前命名空间的等级,初始命名空间的level为0,它的子命名空间level为1,依次递增,而且子命名空间对父命名空间是可见的。
parent:指向父命名空间的指针
因此命名空间的结构如下所示:
2、UPID
正是命名空间的作用,使得进程能够分配到不同的命名空间中去,而且进程在自己所在的命名空间中有着局部的PID,这就是局部PID,因此各个命名空间的PID有可能重复,也即是一个PID可能为多个进程使用,在pid.h文件中定义了一个用来关联PID和命名空间的结构体.
- struct upid {
- /* Try to keep pid_chain in the same cacheline as nr for find_vpid */
- int nr;
- struct pid_namespace *ns;
- struct hlist_node pid_chain;
- };
其中nr表示ID具体的值;
ns是指向命名空间的指针;
pid_chain是指向PID哈希列表的指针,用于关联对于的PID
3、PID
在PID中又对使用该PID的task进行了关联
- struct pid
- {
- atomic_t count;
- unsigned int level;
- /* lists of tasks that use this pid */
- struct hlist_head tasks[PIDTYPE_MAX];
- struct rcu_head rcu;
- struct upid numbers[1];
- };
count 是指使用该PID的task的数目;
level 表示可以看到该PID的命名空间的数目,也就是包含该进程的命名空间的深度
tasks[PIDTYPE_MAX]是一个数组,每个数组项都是一个散列表头,分别对应以下三种类型:
- enum pid_type
- {
- PIDTYPE_PID,
- PIDTYPE_PGID,
- PIDTYPE_SID,
- PIDTYPE_MAX
- };
numbers[1]是一个upid的实例数组,每个数组项代表一个命名空间,用来表示一个PID可以属于不同的命名空间,该元素放在末尾,可以向数组添加附加的项。
总结
1、多个task_struct可以共用一个PID
2、一个PID可以属于不同的命名空间
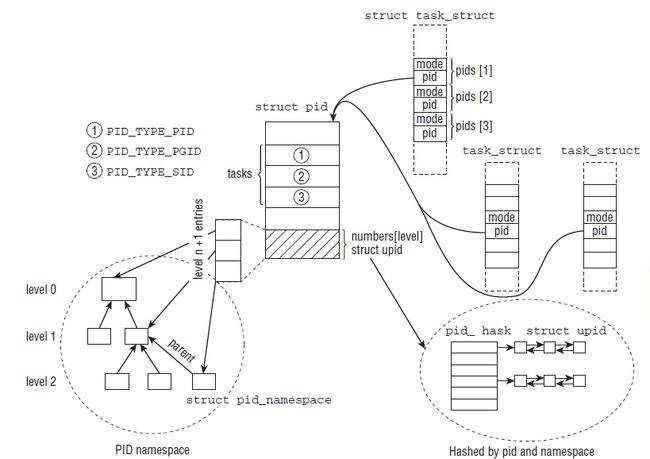
那么最终,linux下进程命名空间和进程的关系结构如下:
可以看到,多个task_struct指向一个PID,同时PID的hash数组里安装不同的类型对task进行散列,并且一个PID会属于多个命名空间。
参考资料:
1、《深入linux内核架构》
2、 http://blog.csdn.net/zhanglei4214/article/details/6765913
转自: http://blog.chinaunix.net/uid-21718047-id-3069416.html