hadoop学习--安装使用
原理普及:
关于hadoop的原理,可以去很多地方普及,这里不再啰嗦。
hadoop内部结构:
hadoop执行map-reduce流程图:
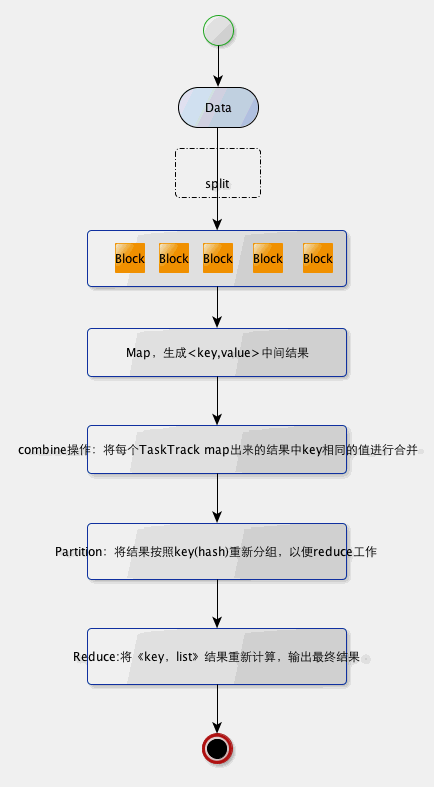
使用教程:
1.下载hadoop core 源代码:http://apache.etoak.com//hadoop/common/hadoop-0.20.2/hadoop-0.20.2.tar.gz
2.安装jdk(pass),修改hadoop脚本中java home变量:songjings-macpro31:conf songjing$ sudo vim bin/hadoop-env.sh
3.跑一个hadoop自带的单机模式的例子,单词统计:
bin/hadoop jar hadoop-0.20.2-examples.jar wordcount test-in test-out
其中test-in为一个目录,目录中是多个文件,文件内容即为待统计的字符串
test-out为该例子输出结果目录
4.查看计算过程和结果:
songjing$ bin/hadoop jar hadoop-0.20.2-examples.jar wordcount test-in test-out11/08/08 13:37:46 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
11/08/08 13:37:46 INFO input.FileInputFormat: Total input paths to process : 2 ##输入文件为两个
11/08/08 13:37:47 INFO mapred.JobClient: Running job: job_local_0001 ##启动一个job
11/08/08 13:37:48 INFO input.FileInputFormat: Total input paths to process : 2
11/08/08 13:37:48 INFO mapred.MapTask: io.sort.mb = 100
11/08/08 13:37:50 INFO mapred.MapTask: data buffer = 79691776/99614720
11/08/08 13:37:50 INFO mapred.MapTask: record buffer = 262144/327680
11/08/08 13:37:50 INFO mapred.JobClient: map 0% reduce 0% ##map开始
11/08/08 13:37:50 INFO mapred.MapTask: Starting flush of map output
11/08/08 13:37:50 INFO mapred.MapTask: Finished spill 0
11/08/08 13:37:50 INFO mapred.TaskRunner: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
11/08/08 13:37:50 INFO mapred.LocalJobRunner:
11/08/08 13:37:50 INFO mapred.TaskRunner: Task 'attempt_local_0001_m_000000_0' done.
11/08/08 13:37:50 INFO mapred.MapTask: io.sort.mb = 100
11/08/08 13:37:51 INFO mapred.JobClient: map 100% reduce 0%
11/08/08 13:37:51 INFO mapred.MapTask: data buffer = 79691776/99614720
11/08/08 13:37:51 INFO mapred.MapTask: record buffer = 262144/327680
11/08/08 13:37:51 INFO mapred.MapTask: Starting flush of map output
11/08/08 13:37:51 INFO mapred.MapTask: Finished spill 0
11/08/08 13:37:51 INFO mapred.TaskRunner: Task:attempt_local_0001_m_000001_0 is done. And is in the process of commiting
11/08/08 13:37:51 INFO mapred.LocalJobRunner:
11/08/08 13:37:51 INFO mapred.TaskRunner: Task 'attempt_local_0001_m_000001_0' done.
11/08/08 13:37:51 INFO mapred.LocalJobRunner:
11/08/08 13:37:51 INFO mapred.Merger: Merging 2 sorted segments ##两个文件的结果进行合并
11/08/08 13:37:51 INFO mapred.Merger: Down to the last merge-pass, with 2 segments left of total size: 76 bytes
11/08/08 13:37:51 INFO mapred.LocalJobRunner:
11/08/08 13:37:51 INFO mapred.TaskRunner: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
11/08/08 13:37:51 INFO mapred.LocalJobRunner:
11/08/08 13:37:51 INFO mapred.TaskRunner: Task attempt_local_0001_r_000000_0 is allowed to commit now
11/08/08 13:37:51 INFO output.FileOutputCommitter: Saved output of task 'attempt_local_0001_r_000000_0' to test-out ##map结束,reduce开始
11/08/08 13:37:51 INFO mapred.LocalJobRunner: reduce > reduce
11/08/08 13:37:51 INFO mapred.TaskRunner: Task 'attempt_local_0001_r_000000_0' done.
11/08/08 13:37:52 INFO mapred.JobClient: map 100% reduce 100%
11/08/08 13:37:52 INFO mapred.JobClient: Job complete: job_local_0001
11/08/08 13:37:52 INFO mapred.JobClient: Counters: 12
11/08/08 13:37:52 INFO mapred.JobClient: FileSystemCounters
11/08/08 13:37:52 INFO mapred.JobClient: FILE_BYTES_READ=467984
11/08/08 13:37:52 INFO mapred.JobClient: FILE_BYTES_WRITTEN=513615
11/08/08 13:37:52 INFO mapred.JobClient: Map-Reduce Framework
11/08/08 13:37:52 INFO mapred.JobClient: Reduce input groups=5
11/08/08 13:37:52 INFO mapred.JobClient: Combine output records=6
11/08/08 13:37:52 INFO mapred.JobClient: Map input records=2
11/08/08 13:37:52 INFO mapred.JobClient: Reduce shuffle bytes=0
11/08/08 13:37:52 INFO mapred.JobClient: Reduce output records=5
11/08/08 13:37:52 INFO mapred.JobClient: Spilled Records=12
11/08/08 13:37:52 INFO mapred.JobClient: Map output bytes=81
11/08/08 13:37:52 INFO mapred.JobClient: Combine input records=8
11/08/08 13:37:52 INFO mapred.JobClient: Map output records=8
11/08/08 13:37:52 INFO mapred.JobClient: Reduce input records=6
songjings-macpro31:hadoop-0.20.2 songjing$ cd test-out/
songjings-macpro31:test-out songjing$ ls
part-r-00000
察看最后的结果:
songjings-macpro31:test-out songjing$ more part-r-00000by 1
goodbye 1
hadoop 2
hello 2
world 2
5.如何写job:
实现mapper和reducer对应的方法map(),reduce():
map方法:
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
以上map方法扫描文件中的每一个字符并将起存储为key-value,其中key为单词,value为1
reduce方法:public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
reduce工作对每个key对应的list进行统计个数
写完map和reduce方法后,需要写主程序来调用map和reduce方法执行job工作:public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);//设置跑job的map-reduce jar包
job.setMapperClass(TokenizerMapper.class);//指定map实现类
job.setCombinerClass(IntSumReducer.class);//指定对map结果按照key合并的类
job.setReducerClass(IntSumReducer.class);//指定reduce类
job.setOutputKeyClass(Text.class);//设置输出字段的key为text
job.setOutputValueClass(IntWritable.class);//设置输出字段的value为int类型
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));//设置要分析的文件路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//设置输出的文件路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
注意:output路径不能是已存在目录,不然hadoop会报错:
// Ensure that the output directory is set and not already there
Path outDir = getOutputPath(job);
if (outDir == null && job.getNumReduceTasks() != 0) {
throw new InvalidJobConfException("Output directory not set in JobConf.");
}
if (outDir != null) {
FileSystem fs = outDir.getFileSystem(job);
// normalize the output directory
outDir = fs.makeQualified(outDir);
setOutputPath(job, outDir);
// check its existence
if (fs.exists(outDir)) {
throw new FileAlreadyExistsException("Output directory " + outDir +
" already exists");
}
}