在C/C++代码中使用SSE等指令集的指令(3)SSE指令集基础
相关参考:
http://edu.gamfe.com/tutor/d/11820.html
http://blog.163.com/chenqneu@126/blog/static/45738484200781392836677/
http://dev.gameres.com/Program/Other/SSEjianjie.htm
http://www.vckbase.com/document/viewdoc/?id=322
scalar packed
(1)Summary:
前面了解到了可以在代码中使用intrinsics函数来实现类似汇编的高级指令集(SSE等)指令,在这里,为了加深理解,再次分析一下SSE指令。
(2)MMX指令集
首先要提到MMX指令集,MMX指令集是在SSE之前的,后来的SSE指令集覆盖了MMX指令集的内容,现在的大多数CPU也都支持SSE指令集了,SSE指令集之后还有SSE2、SSE3、SSE4等,最新的Intel处理器支持AVX指令集。
(3)SIMD
single instruction multiple data,单指令流多数据流,也就是说一次运算指令可以执行多个数据流,这样在很多时候可以提高程序的运算速度。
SIMD是CPU实现DLP(Data Level Parallelism)的关键,DLP就是按照SIMD模式完成计算的。
(4)SSE
SSE(为Streaming SIMD Extensions的缩写)是由 Intel公司,在1999年推出Pentium III处理器时,同时推出的新指令集。如同其名称所表示的,SSE是一种SIMD指令集。所谓的SIMD是指single instruction, multiple data,也就是一个指令同时对多个资料进行相同的动作。较早的MMX和 AMD的3DNow!也都是SIMD指令集。因此,SSE本质上是非常类似一个向量处理器的。SSE指令包括了四个主要的部份:单精确度浮点数运算指令、整数运算指令(此为MMX之延伸,并和MMX使用同样的暂存器)、Cache控制指令、和状态控制指令。
(5)SSE新增的寄存器(用于浮点运算指令)
SSE新增了八 个新的128位元暂存器,xmm0 ~ xmm7。这些128位元的暂存器,可以用来存放四个32位元的单精确度浮点数。SSE的浮点数运算指令就是使用这些暂存器。和之前的MMX或3DNow!不同,这些暂存器并不是原来己有的暂存器(MMX和3DNow!均是使用x87浮点数暂存器),所以不需要像MMX或3DNow!一样,要使用x87指令之前,需要利用一个EMMS指令来清除暂存器的状态。因此,不像MMX或3DNow!指令,SSE的浮点数运算指令,可以很自由地和x87指令,或是MMX指令共用。但是,这样做的主要缺点是,因为多工作业系统在进行context switch时,需要储存所有暂存器的内容。而这些多出来的新暂存器,也是需要储存的。因此,既存的作业系统需要修改,在context switch时,储存这八个新暂存器的内容,才能正确支援SSE浮点运算指令。
下图是SSE新增寄存器的结构:
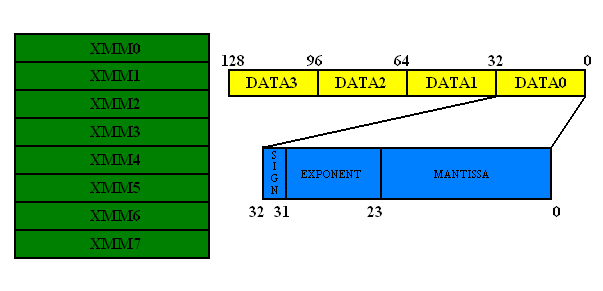
(6)SSE浮点运算指令分类
SSE的浮点运算指令分为两大类:packed和scalar。(有些地方翻译为“包裹指令和”“标量指令” :) )
Packed指令是一次对XMM暂存器中的四个浮点数(即DATA0 ~ DATA3)均进行计算,而scalar则只对XMM暂存器中的DATA0进行计算。如下图所示:
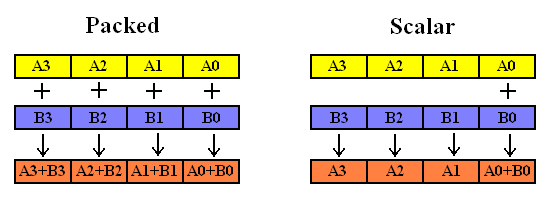
下面是SSE指令的一般格式,由三部分组成,第一部分是表示指令的作用,比如加法add等,第二部分是s或者p分别表示scalar或packed,第三部分为s,表示单精度浮点数(single precision floating point data)。

(7)SSE新的数据类型:
根据上面知道,SSE新增的寄存器是128bit的,那么SSE就需要使用128bit的数据类型,SSE使用4个浮点数(4*32bit)组合成一个新的数据类型,用于表示128bit类型,SSE指令的返回结果也是128bit的。
(8)SSE定址/寻址方式:
SSE 指令和一般的x86 指令很类似,基本上包括两种定址方式:寄存器-寄存器方式(reg-reg)和寄存器-内存方式(reg-mem):
addps xmm0, xmm1 ; reg-reg
addps xmm0, [ebx] ; reg-mem
(10)intrinsics的SSE指令
要使用SSE指令,可以使用intrinsics来简化编程,前面已经介绍过intrinsics的基础了,这里也不会展开。
SSE指令的intrinsics函数名称一般为:_m_operation[u/r...]_ss/ps,和上面的SSE指令的命名类似,只是增加了_m_前缀,另外,表示指令作用的操作后面可能会有一个可选的修饰符,表示一些特殊的作用,比如从内存加载,可能是反过来的顺序加载(不知道汇编指令有没有对应的修饰符,理论上应该没有,这个修饰符只是给编译器用于进行一些转换用的,具体待查)。
SSE指令中的intrinsics函数的数据类型为:__m128,正好对应 了上面提到的SSE新的数据类型,当然,这种数据类型只是一种抽象表示,实际是要转换为基本的数据类型的。
(9)SSE指令的内存对齐要求
SSE中大部分指令要求地址是16bytes对齐的,要理解这个问题,以_mm_load_ps函数来解释,这个函数对应于loadps的SSE指令。
其原型为:extern __m128 _mm_load_ps(float const*_A);
可以看到,它的输入是一个指向float的指针,返回的就是一个__m128类型的数据,从函数的角度理解,就是把一个float数组的四个元素依次读取,返回一个组合的__m128类型的SSE数据类型,从而可以使用这个返回的结果传递给其它的SSE指令进行运算,比如加法等;从汇编的角度理解,它对应的就是读取内存中连续四个地址的float数据,将其放入SSE新的暂存器(xmm0~8)中,从而给其他的指令准备好数据进行计算。其使用示例如下:
float input[4] = { 1.0f, 2.0f, 3.0f, 4.0f };
__m128 a = _mm_load_ps(input);这里加载正确的前提是:input这个浮点数阵列都是对齐在16 bytes的边上。否则加载的结果和预期的不一样。如果没有对齐,就需要使用_mm_loadu_ps函数,这个函数用于处理没有对齐在16bytes上的数据,但是其速度会比较慢。关于内存对齐的问题,这里就不详细讨论什么是内存对齐了,以及如何指定内存对齐方式。这里主要提一下,SSE的intrinsics函数中的扩展的方式:
对于上面的例子,如果要将input指定为16bytes对齐,可以采用的方式是:__declspec(align(16)) float input[4];
那么,为了简化,在xmmintrin.h中定义了一个宏_MM_ALIGN16来表示上面的含义,即:_MM_ALIGN16 float input[4];
(11)大小端问题:
这个只是使用SSE指令的时候要注意一下,我们知道,x86的little-endian特性,位址较低的byte会放在暂存器的右边。也就是说,若以上面的input为例,在载入到XMM暂存器后,暂存器中的DATA0会是1.0,而DATA1是2.0,DATA2是3.0,DATA3是4.0。如果需要以相反的顺序载入的话,可以用_mm_loadr_ps 这个intrinsic,根据需要进行选择。
(12)总结:了解SIMD、DLP、向量化、SSE基础等。