Lucene整理--中文分词
看lucene主页(http://lucene.apache.org/)上目前lucene已经到4.9.0版本了, 参考学习的书是按照2.1版本讲解的,写的代码例子是用的3.0.2版本的,版本
的不同导致有些方法的使用差异,但是大体还是相同的。
源代码用到的jar包(3.0.2版本)下载地址
参考资料:
1、公司内部培训资料
2、《Lucene搜索引擎开发权威经典》于天恩著.
Lucene使用挺简单的,耐心看完都能学会,还有源代码。
分词的方法主要有以下几种:
1)、单字切分
单字切分就是把一段文字按照每个字去建立索引。例如将"阿根廷将捧起大力神杯"用单字切分就会切成"阿" "根" "廷" "将" "捧" "起" "大" "力" "神" "杯"10个词,这种分词法
效率低下,但也能解决一些问题,聊胜于无。
前面几篇Lucene文章里面建立的索引都是应用的单字切分,所以在写的执行索引搜索的时候关键字都是单字的。
2)、二分法
把一段文字的每两个相邻的字算所一个词,这样"阿根廷将捧起大力神杯"就被切分成"阿根" "根廷" "廷将" "将捧" "捧起" "起大" "大力" "力神" "神杯"
这种分词法效率也低,但是比单字切分要好些的。
3)、词典法
词典法就是建立一个词典文件,然后使用词典和文字段落进行匹配,从而得出分词结果
4)、语义法
这种方法目前只存在于理论上,因为想让计算机完全读懂一个人表达的意思目前还实现不了,中文博大精深的,人和人之间交流还有听不懂的时候呢。
1、先介绍下二分法分词器的使用
Lucene软件包下自带一个lucene-analyzers-3.0.2.jar的包 支持二分法分词
首先也是创建一个索引,代码不贴了,跟前面创建的索引(FootBall)只有一行代码的区别:
IndexWriter indexWriter = new IndexWriter(dir, new CJKAnalyzer(Version.LUCENE_30), true,IndexWriter.MaxFieldLength.LIMITED);
索引创建完执行搜索,这个跟前面的代码没有任何区别,就是执行搜索的时候只能是根据两个字的词进行搜索,用一个字或者三个字都检索不出东西来。
2、JE分词器的用法
JE是一个不错的分词器,许多人都在使用
点击下载JE分词器jar包
它是一个基于词库的分词器,可以向分词器内增加新词。
演示一下这个分词器的使用:
<span style="font-family:SimSun;font-size:12px;">import java.io.IOException;
import jeasy.analysis.MMAnalyzer;
public class UseJE {
public static void main(String[] args) {
String str="阿根廷将捧起大力神杯";
MMAnalyzer mm=new MMAnalyzer();
try {
System.out.println(mm.segment(str, "---"));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
</span>
执行结果控制台截图:

为什么会报这个错误呢,我找了好半天啊,因为JE分词器只支持lucene1.9--lucene2.4版本的,版本太低不行,版本太高也不行,我无语了。
下载个lucene2.0试了下,结果截图如下:

怎样维护JE分词器词库呢
<span style="font-family:SimSun;font-size:12px;">import jeasy.analysis.MMAnalyzer;
public class AddWord {
public static void main(String[] args) {
MMAnalyzer mm=new MMAnalyzer();
System.out.println(MMAnalyzer.contains("曹海成"));//是否包含该词条
mm.addWord("曹海成");//像分词器内添加该词条
System.out.println(MMAnalyzer.contains("曹海成"));
System.out.println(mm.size());//包含词条总数
}
}
</span>
执行结果:
lucene要是所有版本都支持JE分词器就好了。
3、IK分词器
点此下载IK分词器JAR包
<span style="font-family:SimSun;font-size:12px;">import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.TermAttribute;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class UseIK {
public static void main(String[] args) {
String str="阿根廷将捧起大力神杯";
IKAnalyzer ik=new IKAnalyzer();
testAnalyzer(ik, str);
}
private static void testAnalyzer(IKAnalyzer ik, String str) {
System.out.println("当前使用的分词器:" + ik.getClass());
TokenStream tokenStream = ik.tokenStream("content",new StringReader(str));
tokenStream.addAttribute(TermAttribute.class);
try {
while (tokenStream.incrementToken()) {
TermAttribute termAttribute = tokenStream.getAttribute(TermAttribute.class);
System.out.println(termAttribute.term());
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println();
}
}
</span>
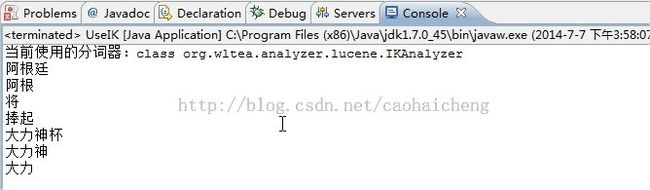
执行结果截图: