cascading基本概念
这是cascading官方userguide的中文翻译,其中有些概念看过一段时间又忘了,在此做个记录,一是方便自己复习,二是方便新手。
关于cascading我不想多说了,你如果写过原生mapreduce程序,然后再接触cascading,你会发现cascading Great job。它对Map和Reduce进行了高度抽象,用Tap、Pipe、Function、Operation这些概念替代了原有的Map和Reduce,可以很舒服的开发hadoop程序,但是这些概念过了一个来月我又忘的差不多了,所以有了这篇翻译。
对于一些不好翻译的单词我这里直接给出了原单词,所以说看资料还是英文原版的好,看翻译的书籍有很大风险,万一别人翻译错了,那你这个newbie怎么能懂!
下面的翻译来自cascading-userguide/ch03s03.html,下载地址:http://docs.cascading.org/cascading/2.5/userguide/html/userguide.zip
首先是一段关于pipe assembly的代码例子
// the "left hand side" assembly head Pipe lhs = new Pipe( "lhs" ); lhs = new Each( lhs, new SomeFunction() ); lhs = new Each( lhs, new SomeFilter() ); // the "right hand side" assembly head Pipe rhs = new Pipe( "rhs" ); rhs = new Each( rhs, new SomeFunction() ); // joins the lhs and rhs Pipe join = new CoGroup( lhs, rhs ); join = new Every( join, new SomeAggregator() ); join = new GroupBy( join ); join = new Every( join, new SomeAggregator() ); // the tail of the assembly join = new Each( join, new SomeFunction() );
通用流模式Common Stream Pattern
-
Split 一分多
-
Merge 多合一stream拥有相同fields常见的有:Merge、GroupBy
-
Join 和sqljoin一样,把拥有不同列的stream按照相同列join起来。HashJoin、CoGroup
除了split、merge、join以外,管道组装还有examine、filter、organize、transform这些操作,为了方便处理,在元组中的每个值都被赋予一个fieldname,就像数据库中的列名一样,这样他们就能很方便的被引用与选择。
术语介绍:
-
Operation(cascading.operation.Operation)接受一个参数元组Tuple,输出零或多个结果元组。Cascading提供了几个常用的Operation,开发者也可以自己实现。
-
Tuple,在Cascading中,数据被看作元组(cascading.tuple.Tuple)的流,元组由fields构成,元组和数据库中的记录或行类似。一个元组是一组值的数组,每个值可以为任何java.lang.Object。
-
Fields(cascading.tuple,Fields)被用于声明或引用元组中的某一列,fields可以表示为像“firstname”、“birthdate”的字符串,也可以是整数值(0表示第一个,-1表示最后一个),或者还可以是预定义的值(Fields.All、Fields.RESULT、Fields.REPLACE等)
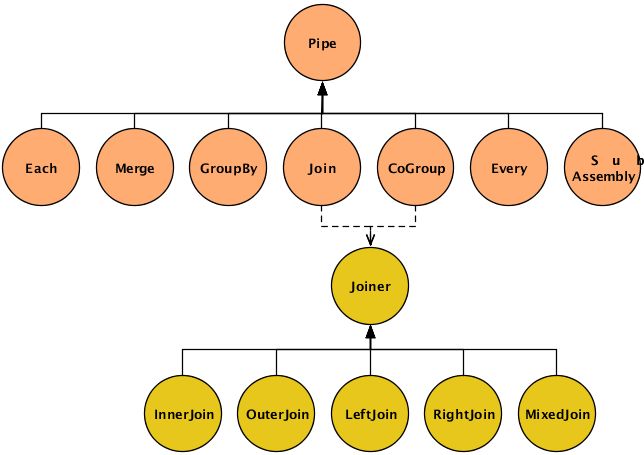
Pipe类是用于实例化与命名一个pipe,Pipe的名字可以被planner用于绑定到tap上,作为source或者sink使用。(第三种选择是绑定pipebranch到一个tap,作为一个trap,这在高级主题在详细讨论)
SubAssembly子类是一个特殊的pipe类型,他用于嵌套一组可重用的pipeassemblies,这样可以方便用于更大范围内的pipeassembly。
其余六种pipe类型:
-
Each这种pipe基于tuple的内容做处理,包括analyze、transform、filter。还可以用Each类splitor branch一个流,达到这种效果你仅仅需要把Each的输出定向到一个不同的pipe或sink即可。
-
Merge这个pipe和Each一样都可以把一个流split成两个,Merge还可以把多个流合并成一个,前途是这些流具有相同的fields。当不需要grouping(noaggregator or buffer操作会被使用时)时使用Merge,Merge比GroupBy快。
-
GroupBy基于特定field,把一个流中的tuples分组。如果传入多个stream,它在分组之前先进行merge操作,在进行merge时,GroupBy要求多个stream必须用相同的fieldstructure。分组的目的通常是为Every管道准备一个处理流,Every管道可以针对groups进行aggregator和buffer操作,比如counting,totalling,averaging。我们应该明确,grouping这里意味着基于某一特地field的值进行分组(byGroupBy或CoGroup),比如按照timestamp或zipcode进行分组,在每一分组中,元组的顺序是随机的,不过你也可以指定一个次sortkey,但是通常情况下,是不必要的,这只会增加运行时间。
-
Every用于处理分组后的流。只能用于GroupBy或Cogroup的输出流,不能处理Each、Merge、HashJoin的输出流。
-
CoGroup对多个流进行join,和SQLjoin类似。它只基于某特定field进行group,产出一个结果流。如果在多流中包含有相同的field名,它们必须被重命名来避免结果tuple中field的冲突
-
HashJoin和Cogroup一样,用于对多个流的join。但是它更适用于不需要grouping的场合下,这时它的性能更优。
Pipe类型对比表
| Pipe type |
Purpose |
Input |
Output |
|
|
instantiate a pipe; create or name a branch |
name |
a (named) pipe |
|
|
create nested subassemblies |
|
|
|
|
apply a filter or function, or branch a stream |
tuple stream (grouped or not) |
a tuple stream, optionally filtered or transformed |
|
|
merge two or more streams with identical fields |
two or more tuple streams |
a tuple stream, unsorted |
|
|
sort/group on field values; optionally merge two or morestreams with identical fields |
one or more tuple streams with identical fields |
a single tuple stream, grouped on key field(s) with optionalsecondary sort |
|
|
apply aggregator or buffer operation |
grouped tuple stream |
a tuple stream plus new fields with operation results |
|
|
join 1 or more streams on matching field values |
one or more tuple streams |
a single tuple stream, joined on key field(s) |
|
|
join 1 or more streams on matching field values |
one or more tuple streams |
a tuple stream in arbitrary order |
Each、Every的语法如下:
new Each( previousPipe, argumentSelector, operation, outputSelector ) new Every( previousPipe, argumentSelector, operation, outputSelector )
这两个pipe都有四个参数:
-
一个pipe实例
-
一个参数选择器
-
一个Operation实例
-
一个输出选择器
Each与Every的主要不同在于Each用于处理单个元组,Every用于处理由GroupBy或CoGroup输出的分组tuple,这限制了它们分别可以实施的操作、结果的输出。
Each的操作可以是Functions和Filters的子类。比如你可以从日志文件中解析出特定field;过滤掉除了HTTPGET以外的请求,把timestring替换成datefield。
Every的操作可以是Aggregators和Buffer的子类。比如你可以用Every去统计每天GET请求数,它会为每天输出一个统计值。
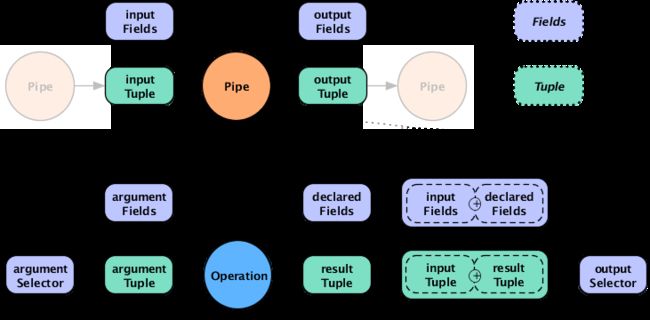
大多数Operation子类都声明了resultfield(就是上图中的declaredfields),outputSelector指定输出Tuple中的field,而输出Tuple中的field来源于input的field和operation的结果这两个方面。如果outputSelector=Fields.ALL那么输出的Tuple就是input+result的数据merge后的结果。
对于Each来说argumentSelector默认为Fields.All,outputSelector默认为Fields.RESULT
对于Every来说Aggregator的result默认被追加到inputTuple上。比如,你在department域上做grouping,然后统计这个公寓的names,那么结果fields会是["department","num_employees"]
当Every与Bufferoperation一起使用时,行为和Aggregator很不一样,operationresult这次是和当前valuestuple关联在一起,而不是当前groupingtuple。这就像Each与Function一起使用时一样。这也许看起来不是很直观,但这提供了很大的灵活性。换一个说法,bufferoperation的result没有被追加到thecurrent keys being grouped on,是由buffer来决定是emit它们ifthey are relevant,而且对于Buffer来说,针对每个唯一的grouping有可能emit多个resultTuple。也就是说,一个Buffer可能或者可能不和Aggregator行为一致,但是Aggregator只是一个特殊的Buffer。