CUDA相关概念
使用CUDA编程,需要了解CUDA的体系和相关概念。
参考:
CUDA C Programming Guide
深入浅出CUDA编程
【CUDA学习】GPU硬件结构
http://blog.csdn.net/leonwei/article/details/8880012
CUDA内存模式的解释比较有趣:http://blog.sina.com.cn/s/blog_5e8e35510100lizi.html
以下内容来源于 CUDA C PROGRAMMING GUIDE,部分图片来自互联网
什么是CUDA:. CUDA®: A General-Purpose Parallel Computing Platform and Programming Model
这是NVIDIA对CUDA的定义,通用的并行计算平台和编程模型
three key abstractions - a hierarchy of thread groups, shared memories, and barrier synchronization
CUDA编程模型的核心内容可以抽象为线程组、共享存储、栅栏同步的层次结构
kernel:CUDA C extends C by allowing the programmer to define C functions, called kernels, that, when called, are executed N times in parallel by N different CUDA threads, as opposed to only once like regular C functions.
核,一个C函数,是并行执行的基本单位,N个线程就执行N次kernel
thread、block、grid
threads can be identified using a one-dimensional, two-dimensional, or three-dimensional thread index, forming a one-dimensional, two-dimensional, or three-dimensional block of threads, called a thread block.On current GPUs, a thread block may contain up to 1024 threads.
Blocks are organized into a one-dimensional, two-dimensional, or three-dimensional grid of thread blocks
a kernel can be executed by multiple equally-shaped thread blocks, so that the total number of threads is equal to the number of threads per block times the number of blocks.
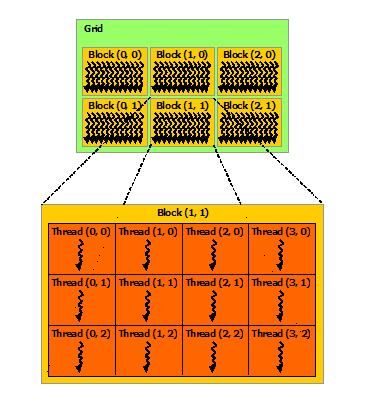
Memory Hierarchy
存储体系
CUDA threads may access data from multiple memory spaces during their execution. Each thread has privatelocal memory. Each thread block hasshared memory visible to all threads of the block and with the same lifetime as the block. All threads have access to the sameglobal memory.
There are also two additional read-only memory spaces accessible by all threads: theconstant and texture memory spaces. The global, constant, and texture memory spaces are optimized for different memory usages . Texture memory also offers different addressing modes, as well as data filtering, for some specific data formats
Heterogeneous Programming
异构编程模型
from 3.2. CUDA C Runtime
a program manages the global, constant, and texture memory spaces visible to kernels through calls to the CUDA runtime
CUDA runtime的作用:内存管理
Device Memory:the CUDA programming model assumes a system composed of a host and a device, each with their own separate memory. Kernels operate out of device memory, so the runtime provides functions to allocate, deallocate, and copy device memory, as well as transfer data between host memory and device memory.
CUDA将系统区分为HOST和DEVICE,分别拥有各自的存储空间。Kernels运行于device memory中。运行时提供了一系列接口用于申请、释放、拷贝device memory,以及在host memory和device memory之间传递数据
Shared Memory:Threads within a block can cooperate by sharing data through some shared memory and by synchronizing their execution to coordinate memory accesses.Shared memory is expected to be much faster than global memory
共享存储shared memory,通过把一个block大小的数据一次性从global memory扔进shared memory中,让kernel到shared memory中读取数据,从而减少读取global memory的次数。这里所说的global memory就是device memory
Page-Locked Host Memory
理解“page”:分段与分页机制小结
Using page-locked host memory has several benefits:
‣ Copies between page-locked host memory and device memory can be performed
concurrently with kernel execution for some devices as mentioned in Asynchronous
Concurrent Execution.
‣ On some devices, page-locked host memory can be mapped into the address space
of the device, eliminating the need to copy it to or from device memory as detailed
in Mapped Memory.
‣ On systems with a front-side bus, bandwidth between host memory and device
memory is higher if host memory is allocated as page-locked and even higher if
in addition it is allocated as write-combining as described in Write-Combining
Memory.
page-locked的意义:
*在某些设备上可以实现 数据传输(host和device)与kernel执行(device)的并发
*在某些设备上,page-locked memory可以直接映射到device memory上,从而避免host和device间的数据传递(例如,显卡共享内存)
*在系统存在前端总线的情况下,page-locked能够增加host和device间的内存带宽
Page-locked host memory is a scarce resource however, so allocations in page-locked
memory will start failing long before allocations in pageable memory. In addition, by
reducing the amount of physical memory available to the operating system for paging,
consuming too much page-locked memory reduces overall system performance.
page-locked的弊端:减少系统的可用内存,有可能降低系统的整体性能
Write-Combining Memory:Write-combining memory frees up the host's L1 and L2 cache
resources, making more cache available to the rest of the application. In addition, write-combining
memory is not snooped during transfers across the PCI Express bus, which
can improve transfer performance by up to 40%.
Reading from write-combining memory from the host is prohibitively slow, so write-combining
memory should in general be used for memory that the host only writes to.
Write-Combining Memory占用更小的缓存资源,同时提高了数据传输速度。但是仅限于device往host写数据,如果是device从host读数据速度反而更慢
-------------------------- NOT END --------------------------
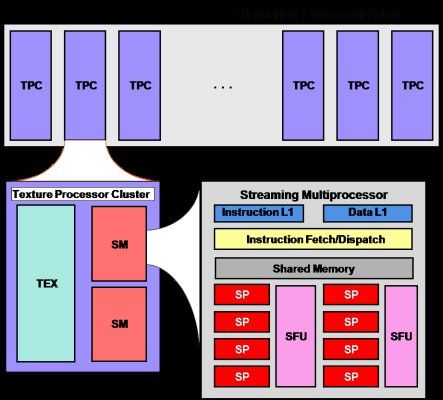
GPU的硬件结构:转自网文http://www.cnblogs.com/dwdxdy/p/3215158.html
sp: 最基本的处理单元,streaming processor 最后具体的指令和任务都是在sp上处理的。GPU进行并行计算,也就是很多个sp同时做处理
sm:多个sp加上其他的一些资源组成一个sm, streaming multiprocessor. 其他资源也就是存储资源,共享内存,寄储器等。
warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令。
grid、block、thread:在利用cuda进行编程时,一个grid分为多个block,而一个block分为多个thread.其中任务划分到是否影响最后的执行效果。划分的依据是任务特性和GPU本身的硬件特性。
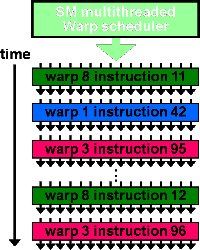
此图反应了warp作为调度单位的作用,每次GPU调度一个warp里的32个线程执行同一条指令,其中各个线程对应的数据资源不同。
上图是一个warp排程的例子。
一个sm只会执行一个block里的warp,当该block里warp执行完才会执行其他block里的warp。进行划分时,最好保证每个block里的warp比较合理,那样一个sm可以交替执行里面的warp,从而提高效率,此外,在分配block时,要根据GPU的sm个数,分配出合理的block数,让GPU的sm都利用起来,提利用率。分配时,也要考虑到同一个线程block的资源问题,不要出现对应的资源不够。