1什么是知识图谱
-
允许用户搜索搜索引擎知道的所有事物,人物或者地方,包括地标,名人,城市, 球队,建筑,地理特征,电影,天体,艺术作品等等,而且能够显示关于你的查询的实时信息。它是迈向下一代搜索业务关键的第一步,使得搜索智能化,根据用户的意图给出用户想要的结果。
-
知识图谱本质上是一种语义网络。其结点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系 [5]
-
知识图谱相对于传统的本体和语义网络而言,实体覆盖率更高,语义关系也更加复杂而全面
2为什么需要构建中文知识图谱
-
互联网上拥有丰富的资源。但是,大多数的资源都只能被人理解,而机器无法理解,如何让机器像人一样理解文本?
-
现有知识图谱对中文支持不够
-
为此,我们需要构建一个海量的中文知识图谱,帮助机器理解文本
3方法
研究框架

中文知识图谱研究框架
分布式爬虫
-
互联网上存在着丰富的资源,选择合适的资源以及相应的爬取策略至关重要
-
单台电脑已经无法支持大规模的网页爬取
-
网站可能存在着限制访问次数、访问出错等问题
-
因此,提出了多任务、容错、平衡、可设置优先级、多样性的分布式爬虫策略
知识抽取
-
数据来源丰富,包括百科全书类网站、地理位置信息(POI)网站、输入法词库、搜索引擎语料库、音乐视频小说等门户网站、电子商务网站等
-
从数据源中抽取出高质量的实体/概念集。包括实体抽取、实体映射(不同词表达相同含义)、关系抽取以及实体质量评估。
知识集成
采用迭代的方式对不同来源的数据进行集成,将相同实体/概念的内容进行融合,特别是多义词之间的融合。具体方法包括:首先找到明显相同的实体/概念对,根据其属性、分类以及相关词,扩充找到更多的相同实体/概念对。依次循环,直至不能找到新的实体/概念对
图数据管理系统
基于开源的Hadoop分布式文件系统与分布式数据库,作为大数据存储的基础
所有的操作都建立在HBase之上
4应用介绍
百度知识图谱
[3] 国内搜索巨头百度近日开始大范围测试类似谷歌的“知识图谱”功能。
此前用户在百度搜索某些公众人物的关键词时,会出现该人物相关的资料,搜索结果以“百科全书”式的方式显示。而如今不只是搜索热门人物,当用户搜索地名、学科名或者流行的“事实“时,百度在左边的搜索结果里会给出常规的搜索结果,而搜索结果的右边则展示跟关键词相关的百度百科内容,以及相关的搜索链接。
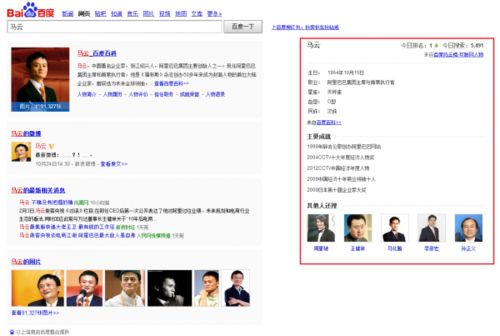
比如用户搜索“马云”时,会在搜索的结果中呈现“马云”百度百科词条、新浪微博地址、相关新闻以及人物图片。而在右侧的“知识图谱”里则展示马云的简介、主要成就以及“其他人还搜”的智能推荐。而如果用户搜索“奥巴马”时,右侧的知识图谱展示得则更多。
同样,如果用户输入地名如“松花江”、学科名如“哲学”以及其他名词性的东西时都会触发百度的“知识图谱”功能。
不过百度并非第一家推出“知识图谱”功能的搜索引擎,去年5月,谷歌就正式推出了Knowledge Graph(知识图谱)功能,而同样拥有“知识图谱”的公司还有2009年创立的搜索引擎Wolfram Alpha。
而相较谷歌的“知识图谱”而言不同的是,百度的“知识图谱”搜索结果并没有完全划到右侧,而是部分内容在搜索结果中全屏幕置顶展现,此外目前右侧也仅用来展示百度自家的内容,如相关的百度百科词条、相关的搜索关键词。
对此有业内人士就表示,百度此次低调推出“知识图谱”一是进一步改善搜索结果,增强用户粘度,使得百度在和谷歌以及360搜索竞争时更有产品方面的优势。同时也能借此为百度旗下的产品如百度百科、百度新闻、百度音乐、爱奇艺、百度贴吧、百度图片增加了海量的流量入口,减少了“肥水”流入外人田的几率。
搜狗知立方
[4] 搜狗在其官方微博中宣称:为了让用户获取信息更简单,搜狗搜索发布全新的知识库搜索引擎――“知立方”。这是国内搜索引擎行业中首家知识库搜索产品。
比如搜索“张学友的电影”,搜狗搜索会在结果上方显示张学友的所有参演过的影片,右侧则展示张学友的人物关系、电视剧、专辑等相关信息,帮助用户更加立体和全面的了解张学友。
再比如搜索“范冰冰的身高”,一般的搜索引擎会给出很多包含“范冰冰身高”的页面,用户需要逐一点击寻找答案。搜狗知立方可以直接给出精准答案。
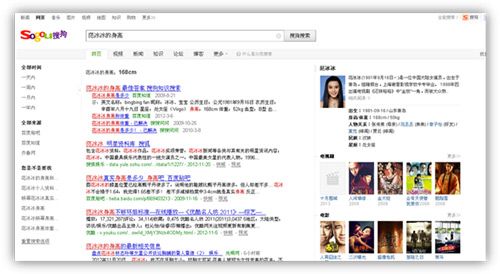
要做到直接给出答案,除了要有结构化的海量数据知识库为支撑外,语义理解也是其中重要一环。搜狗凭借自然语言处理技术的多年积累,能够更加智能的理解用户的查询意图,给出精准的答案。
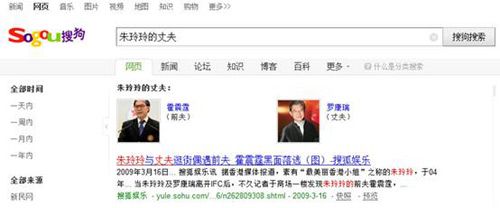
据搜狗搜索事业部总经理茹立云介绍,搜狗知立方已经秘密研发一年有余,而负责该产品研发的架构师则自博士在读期间就从事相关领域的研究。目前知立方知识库涉及实体已达亿级,实体间的关系达到十亿级,未来会逐渐应用到线上。
茹立云介绍,搜狗知立方相比之前搜索结果的优势是:
1.更加精准。知立方可以智能分析用户的查询意图,基于推理及计算能力,直接给出用户想要的答案。
2.更加权威。知立方通过对全网页面的分析和挖掘,保证知识库数据的准确性,提供比知道类产品更加权威的答案。
3.更加全面。知立方可以给出完整的知识体系,使用户更加全方位的了解知识点,同时还可以发现很多不知道的东西。比如搜索“李娜”,可以发现叫“李娜”的除了知名的歌手和网球运动员外,还有演员、击剑运动员和跳水运动员。
相关业内人士称,搜狗知立方的上线代表国内搜索引擎在知识库领域的一次成功探索,是“语义网”自 2001 年提出之后,首次在国内搜索引擎行业的成功应用。搜索引擎诞生十多年来核心机制没有实质性的变化,搜狗的此次成功突破,相信不久后国内主流搜索引擎会相继跟进与模仿。
复旦GDM中文知识图谱
[1]
文本化展示
-
输入一个关键字后,搜索引擎能够准备的知道用户搜索的关键字含义,并给出相关的知识说明
-
提供知识查询、问题查询、别名搜索、知识源合并等功能
图形化展示
-
为了更好的理解知识,采用了图形化引擎进行展示,更好的表现了语义之间的关系
-
同时,将相关词进行聚类,分成若干类,按类展示,并为每个类标注类标签,这样能更加清楚、直观的理解实体

图形化展示
深度阅读
运用知识图谱,对电子书中出现地词语进行精确、全面解释,挖掘词语背后的知识,改善阅读体验
舆情分析
-
运用知识图谱,对微博进行数据挖掘分析
-
倾听民意,改善民生
-
研究成果已被解放日报、新民晚报等报纸刊登报道,并被多家网络媒体转载