Nutch主流程代码阅读笔记整理(一)
Nutch 的Crawler和Searcher两部分被尽是分开,其主要目的是为了使两个部分可以布地配置在硬件平台上,例如Crawler和Searcher分别被放置在两个主机上,这样可以极大的提高灵活性和性能。
一、总体流程介绍
爬行过程在Introduction to Nutch, Part 1 Crawling 里已有详细说明,或许直接看Crawl类来理解爬行的过程。
这里有一幅更直观的图:
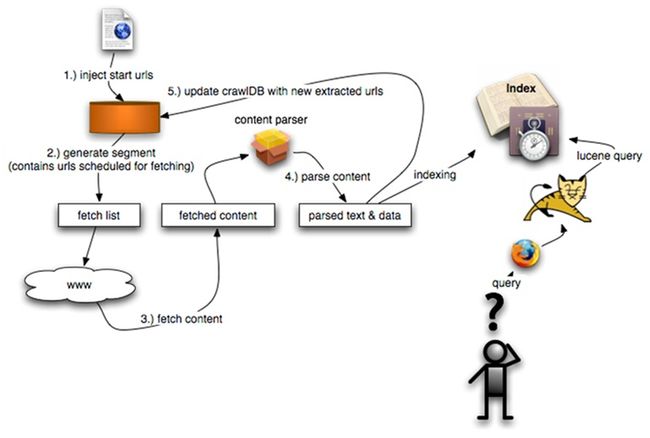
1、先注入种子urls到crawldb
2、循环:
* generate 从crawldb中生成一个url的子集用于抓取
* fetch 抓取上一小的url生成一个个segment
* parse 分析已抓取segment的内容
* update 把已抓取的数据更新到原先的crawldb
3、从已抓取的segments中分析出link地图
4、索引segment文本及inlink锚文本
Nutch用入口地址,地址正则表达式,搜索深度三种形式来限制
因为使用了Hadoop,Nutch的代码都按照Hadoop的模式来编写以获得分布式的能力,因此要先了解一下Hadoop,明白它Mapper,Rerducer, InputFormat, OutputFormat类的作用才能更好的阅读。
二、相关的数据结构和目录结构分析
爬虫Crawler:
Crawler 的工作流程包括了整个nutch的所有步骤--injector,generator,fetcher,parseSegment,updateCrawleDB,Invert links, Index ,DeleteDuplicates, IndexMerger
Crawler涉及的数据文件和格式和含义,和以上的各个步骤相关的文件分别被存放在物理设备上的以下几个文件夹里,crawldb,segments,indexes,linkdb,index五个文件夹里。
那么各个步骤和流程是怎么,各个文件夹里又是放着什么呢?
观察Crawler类可以知道它的流程
./nutch crawl urls -dir ~/crawl -depth 4 -threads 10 -topN 2000
Crawl目录结构分析,参考自《Lucene+Nutch搜索引擎开发》
一、crawldb 下载的url,以及下载日期,用来进行页面更新
二、segements 存放抓取页面和分析结果
1、crawl_generate:待下载url
2、crawl_fetch:每个下载url的状态
3、content:每个下载页面的内容
4、parse_text:包含每个解析过的url文本内容
5、parse_data:每个url解析出的外部链接和元数据
6、crawl_parse:用来更新crawl的外部链接库
三、linkdb 存放url的互联关系
四、indexes:存放每次下载的独立索引目录
五、index:符合lucene格式的索引目录,是indexes里所有index合并后的完整索引
数据结构:
Crawl DB
● CrawlDb 是一个包含如下结构数据的文件:
<URL, CrawlDatum>
● CrawlDatum:
<status, date, interval, failures, linkCount, ...>
● Status:
{db_unfetched, db_fetched, db_gone,linked,
fetch_success, fetch_fail, fetch_gone}