Linux内存管理之slab机制(概述)
通过前面所有代码的分析和总结,已经把各个部分熟悉了一遍,在此对Linux内核中slab机制做最后的总结。
伙伴系统算法采用页作为基本内存区,这适合于大块内存的请求。对于小内存区的申请,比如说几十或几百个字节,我们用slab机制。
Slab分配器把对象分组放进高速缓存。每个高速缓存都是同类型对象的一种“储备”。包含高速缓存的主内存区被划分为多个slab,每个slab由一个活多个连续的页组成,这些页中既包含已分配的对象,也包含空闲的对象。
1,cache对象管理器
Cache对象管理器为kmem_cache结构,如下:
/*
* struct kmem_cache
*
* manages a cache.
*/
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];/*local cache*/
/* 2) Cache tunables. Protected by cache_chain_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int buffer_size;/*slab中对象大小*/
u32 reciprocal_buffer_size;/*slab中对象大小的倒数*/
/* 3) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
/* 4) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags;
size_t colour;/*着色块个数*/ /* cache colouring range */
unsigned int colour_off;/* cache的着色块的单位大小 */ /* colour offset */
struct kmem_cache *slabp_cache;
unsigned int slab_size;/*slab管理区大小,包含slab对象和kmem_bufctl_t数组*/
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *obj);
/* 5) cache creation/removal */
const char *name;
struct list_head next;
/* 6) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;/*cache命中计数,在分配中更新*/
atomic_t allocmiss;/*cache未命中计数,在分配中更新*/
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. buffer_size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
int obj_size;
#endif /* CONFIG_DEBUG_SLAB */
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
struct kmem_list3 *nodelists[MAX_NUMNODES];
/*
* Do not add fields after nodelists[]
*/
};
在初始化的时候我们看到,为cache对象、三链结构、本地cache对象预留了三个cache共分配。其他为通用数据cache,整体结构如下图
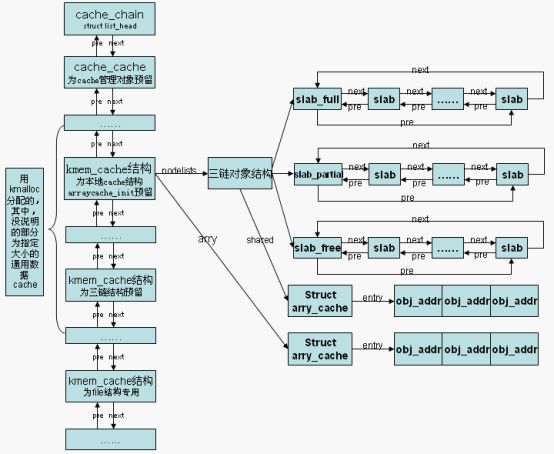
其中,kmalloc使用的对象按照大小分属不同的cache,32、64、128、……,每种大小对应两个cache节点,一个用于DMA,一个用于普通分配。通过kmalloc分配的对象叫作通用数据对象。
可见通用数据cache是按照大小进行划分的,结构不同的对象,只要大小在同一个级别内,它们就会在同一个general cache中。专用cache指系统为特定结构创建的对象,比如struct file,此类cache中的对象来源于同一个结构。
2,slab对象管理器
Slab结构如下
/*
* struct slab
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/
struct slab {
struct list_head list;
/* 第一个对象的页内偏移,对于内置式slab,colouroff成员不仅包括着色区
,还包括管理对象占用的空间
,外置式slab,colouroff成员只包括着色区。*/
unsigned long colouroff;
void *s_mem;/* 第一个对象的虚拟地址 *//* including colour offset */
unsigned int inuse;/*已分配的对象个数*/ /* num of objs active in slab */
kmem_bufctl_t free;/* 第一个空闲对象索引*/
unsigned short nodeid;
};
关于slab管理对象的整体框架以及slab管理对象与对象、页面之间的联系在前面的slab创建一文中已经总结的很清楚了。
3,slab着色
CPU访问内存时使用哪个cache line是通过低地址的若干位确定的,比如cache line大小为32,那么是从bit5开始的若干位。因此相距很远的内存地址,如果这些位的地址相同,还是会被映射到同一个cache line。Slab cache中存放的是相同大小的对象,如果没有着色区,那么同一个cache内,不同slab中具有相同slab内部偏移的对象,其低地址的若干位是相同的,映射到同一个cache line。如图所示。
如此一来,访问cache line冲突的对象时,就会出现cache miss,不停的在cache line和内存之间来回切换,与此同时,其他的cache line可能无所事事,严重影响了cache的效率。解决这一问题的方法是通过着色区使对象的slab内偏移各不相同,从而避免cache line冲突。
着色貌似很好的解决了问题,实质不然,当slab数目不多时,着色工作的很好,当slab数目很多时,着色发生了循环,仍然存在cache line冲突的问题。