无约束优化方法读书笔记—入门篇
优化方法读书笔记
声明:
1)该博文的绝大部分内容抄自课本《最优化理论与方法》,作者袁亚湘,孙文瑜
2)该博文只是列出优化算法大体框架,没有深入去推导各种公式。
2)本文仅供学术交流,非商用,有些部分本来就是直接从课本复制过来的。如果某部分不小心侵犯了大家的利益,还望海涵,并联系老衲删除或修改,直到相关人士满意为止。
3)本人才疏学浅,整理总结的时候难免出错,还望各位前辈不吝指正,谢谢。
4)阅读本文需要一定的数学基础,如微分,梯度,向量,矩阵等等基础(如果没有也没关系了,没有就看看,当做跟同学们吹牛的本钱)。
5)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。请直接回帖,本人来想办法处理。
6)本人手上有word版的和pdf版的,不知道怎么上传,所以需要的话可以直接到DeepLearning高质量交流群里要,群号由于未取得群主同意不敢公布,需要的同学可以联系群主@tornadomeet
1.1问题定义
1.1.1优化问题定义
最优化问题数学上定义,最优化问题的一般形式为
其中的是自变量,f(x)是目标函数,为约束集或者说可行域。
可行域这个东西,有等式约束,也有不等式约束,或者没有约束,这次的精力主要还是集中在无约束的优化问题上,如果有精力,再讨论有约束的。
1.1.2最优化方法定义
优化问题的解法叫最优化方法。最优化方法通常采用迭代的方法求它的最优解,其基本思想是:给定一个初始点 。按照某一迭代规则产生一个点列 ,使得当 是有穷点列时,其最后一个点是最优化模型问题的最优解,当是 无穷点列时,它有极限点,且其极限点是最优化模型问题的最优解。一个好的算法应具备的典型特征为:迭代点 能稳定地接近局部极小值点 的邻域,然后迅速收敛于 。当给定的某个收敛准则满足时,迭代即终止。
好吧,上面是一堆描述,来点定义,设为第k次迭代点,第k次搜索方向,为第k次步长因子,则第k次迭代为
(2)
然后后面的工作几乎都在调整这个项了,不同的步长和不同的搜索方向分别构成了不同的方法。
当然步长和搜索方向是得满足一些条件,毕竟是求最小值,不能越迭代越大了,下面是一些条件
(3)
(4)
式子(3)的意义是搜索方向必须跟梯度方向(梯度也就是)夹角大于90度,也就是基本保证是向梯度方向的另外一边搜索,至于为什么要向梯度方向的另外一边搜索,就是那样才能保证是向目标函数值更小的方向搜索的,因为梯度方向一般是使目标函数增大的(不增大的情况是目标函数已经到达极值)。
式子(4)的意义就很明显了,迭代的下一步的目标函数比上一步小。
最优化方法的基本结构为:
给定初始点,
(a) 确定搜索方向,即按照一定规则,构造目标函数f在点处的下降方向作为搜索方向。
(b) 确定步长因子,使目标函数值有某种意义的下降。
(c) 令
能不能收敛到最优解是衡量最优化算法的有效性的一个重要方面。
1.1.3收敛速度简介
收敛速度也是衡量最优化方法有效性的一个重要方面。
设算法产生的迭代点列在某种范数意义下收敛,即
(5)
若存在实数(这个不是步长)以及一个与迭代次数k无关的常数,使得
(6)
(a) 当,时,迭代点列叫做具有Q-线性收敛速度;
(b) 当,q>0时或,q=0时,迭代点列叫做具有Q-超线性收敛速度;
(c) 当时,迭代点列叫做具有Q-二阶收敛速度;
一般认为,具有超线性收敛速度和二阶收敛速度的方法是比较快速的。但是对于一个算法,收敛性和收敛速度的理论结果并不保证算法在实际执行时一定有好的实际计算特性。一方面是由于这些结果本身并不能保证方法一定有好的特性,另一方面是由于算法忽略了计算过程中十分重要的舍入误差的影响。
1.2步长确定
1.2.1一维搜索
如前面的讨论,优化方法的关键是构造搜索方向 和步长因子 ,这一节就讨论如何确定步长。
设
这样,从x_k出发,沿搜索方向,确定步长因子,使得
的问题就是关于α的一维搜索问题。注意这里是假设其他的和都确定了的情况下做的搜索,要搜索的变量只有α。
如果求得的,使得目标函数沿搜索方向达到最小,即达到下面的情况
或者说
如果能求导这个最优的,那么这个就称为最优步长因子,这样的搜索方法就称为最优一维搜索,或者精确一维搜索。
但是现实情况往往不是这样,实际计算中精确的最优步长因子一般比较难求,工作量也大,所以往往会折中用不精确的一维搜索。
不精确的一维搜索,也叫近似一维搜索。方法是选择,使得目标函数f得到可接受的下降量,即使得下降量是用户可接受的。也就是,只要找到一个步长,使得目标函数下降了一个比较满意的量就可以了。
为啥要选步长?看下图,步长选不好,方向哪怕是对的,也是跑来跑去,不往下走,二维的情况简单点,高维的可能会弄出一直原地不动的情况来。
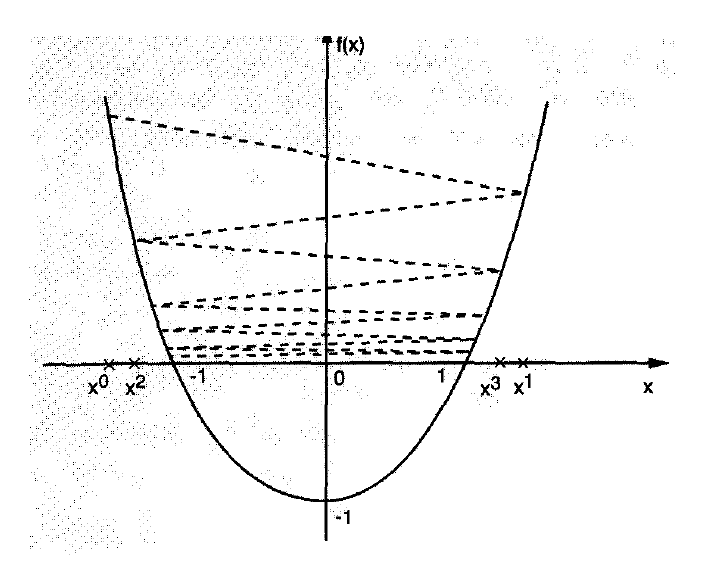
一维搜索的主要结构如下:1)首先确定包含问题最优解的搜索区间,再采用某种分割技术或插值方法缩小这个区间,进行搜索求解。
当然这个搜索方法主要是适应单峰区间的,就是类似上面的那种,只有一个谷底的。
1.2.1.1确定搜索区间
确定搜索区间一般用进退法,思想是从某一点出发,按某步长,确定函数值呈现“高-低-高”的三个点,一个方向不成功,就退回来,沿相反方向寻找。
下面是步骤。

1.2.1.2搜索求解
搜索求解的话,0.618法简单实用。虽然Fibonacci法,插值法等等虽然好,复杂,就不多说了。下面是0.618法的步骤。

普通的0.618法要求一维搜索的函数是单峰函数,实际上遇到的函数不一定是单峰函数,这时,可能产生搜索得到的函数值反而大于初始区间端点出函数值的情况。有人建议每次缩小区间是,不要只比较两个内点处的函数值,而是比较两内点和两端点处的函数值。当左边第一个或第二个点是这四个点中函数值最小的点是,丢弃右端点,构成新的搜索区间;否则,丢弃左端点,构成新的搜索区间,经过这样的修改,算法会变得可靠些。步骤就不列了。
1.2.2不精确一维搜索方法
一维搜索过程是最优化方法的基本组成部分,精确的一维搜索方法往往需要花费很大的工作量。特别是迭代点远离问题的解时,精确地求解一个一维子问题通常不是十分有效的。另外,在实际上,很多最优化方法,例如牛顿法和拟牛顿法,其收敛速度并不依赖于精确一维搜索过程。因此,只要保证目标函数f(x)在每一步都有满意的下降,这样就可以大大节省工作量。
有几位科学家Armijo(1966)和Goldstein(1965)分别提出了不精确一维搜索过程。设
是一个区间。看下图
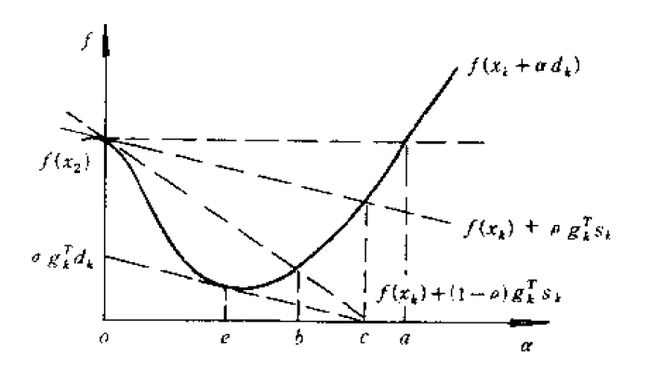
在图中,区间J=(0,a)。为了保证目标函数单调下降,同时要求f的下降不是太小(如果f的下降太小,可能导致序列的极限值不是极小值),必须避免所选择的α太靠近区间j的短短。一个合理的要求是
(2.5.2)
(2.5.3)
其中0<ρ<1/2,。满足(2.5.2)要求的α_k构成区间J_1=(0,c],这就扔掉了区间J右端附件的点。但是为了避免α太小的情况,又加上了另一个要求(2.5.3),这个要求扔掉了区间J的左端点附件的点。看图中和两条虚线夹出来的区间J_2=[b,c]就是满足条件(2.5.2)和(2.5.3)的搜索区间,称为可接受区间。条件(2.5.2)和(2.5.3)称为Armijo-Goldstein准则。无论用什么办法得到步长因子α,只要满足条件(2.5.2)和(2.5.3),就可以称它为可接受步长因子。
其中这个要求是必须的,因为不用这个条件,可能会影响牛顿法和拟牛顿法的超线性收敛。
在图中可以看到一种情况,极小值e也被扔掉了,为了解决这种情况,Wolfe-Powell准则给出了一个更简单的条件代替 (2.5.4)
其几何解释是在可接受点处切线的斜率大于或等于初始斜率的σ倍。准则(2.5.2)和(2.5.4)称为Wolfe-Powell准则,其可接受区间为J_3=[e,c]。
要求ρ<σ<1是必要的,它保证了满足不精确线性搜索准则的步长因子的存在,不这么弄,可能这个虚线会往下压,没有交点,就搞不出一个区间来了。
下面就给出Armijo-Goldstein准则和Wolfe-Powell准则的框图。
从算法框图中可以看出,两种方法是类似的,只是在准则不成立,需要计算新的时,一个利用了简单的求区间中点的方法,另一个采用了二次插值方法。


算法步骤只给出Armijo-Goldstein不精确一维搜索方法的,下面就是

好了,说到这,确定步长的方法也说完了,其实方法不少,实际用到的肯定是最简单的几种,就把简单的几种提了一下,至于为什么这样,收敛如何,证明的东西大家可以去书中慢慢看。
1.3方向确定
1.3.1最速下降法
最速下降法以负梯度方向作为最优化方法的下降方向,又称为梯度下降法,是最简单实用的方法。1.3.1.1算法步骤
下面是步骤。
看个例子。
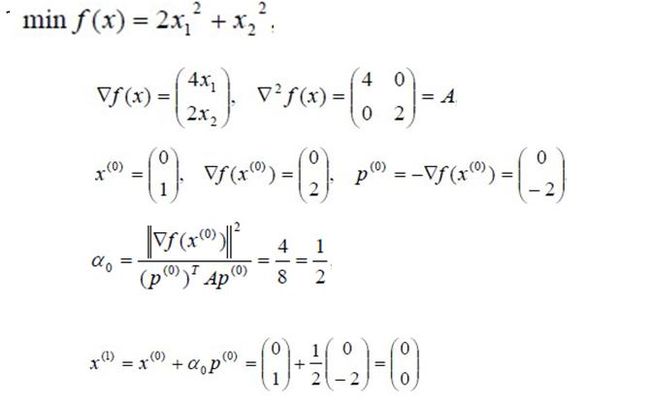
这个选步长的方法是对二次函数下的特殊情况,是比较快而且好的显式形式,说明步长选得好,收敛很快。
1.3.1.2缺点
数值实验表明,当目标函数的等值线接近一个圆(球)时,最速下降法下降较快,当目标函数的等值线是一个扁长的椭球是,最速下降法开始几步下降较快,后来就出现锯齿线性,下降就十分缓慢。原因是一维搜索满足 ,即 ,这表明在相邻两个迭代点上函数f(x)的两个梯度繁星是互相直交(正交)的。即,两个搜索方向互相直交,就产生了锯齿性质。当接近极小点时,步长越小,前进越慢。下图是锯齿的一个图。

1.3.2牛顿法
1.3.2.1算法思想和步骤
牛顿法的基本思想是利用目标函数的二次Taylor展开,并将其极小化。设f(x)是二次可微实函数, ,Hesse矩阵 正定。在 附件用二次Taylor展开近似f,
其中,,为f(x)的二次近似。将上式右边极小化,便得
这就是牛顿迭代公式。在这个公式中,步长因子。令,,则上面的迭代式也可以写成。
其中的Hesse矩阵的形式如下。

一个例子如下。
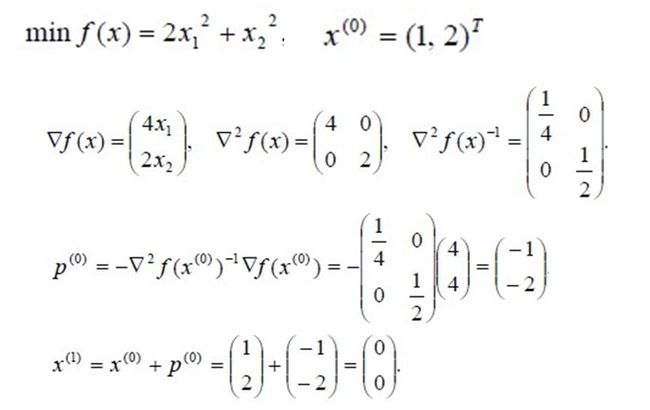
对于正定二次函数,牛顿法一步就可以得到最优解。
对于非二次函数,牛顿法并不能保证经过有限次迭代求得最优解,但由于目标函数在极小点附近近似于二次函数,所以当初始点靠近极小点时,牛顿法的收敛速度一般是快的。
当初始点远离最优解,不一定正定,牛顿方向不一定是下降方向,其收敛性不能保证,这说明步长一直是1是不合适的,应该在牛顿法中采用某种一维搜索来确定步长因子。但是要强调一下,仅当步长因子收敛到1时,牛顿法才是二阶收敛的。
这时的牛顿法称为阻尼牛顿法,步骤如下。

下面看个例子。
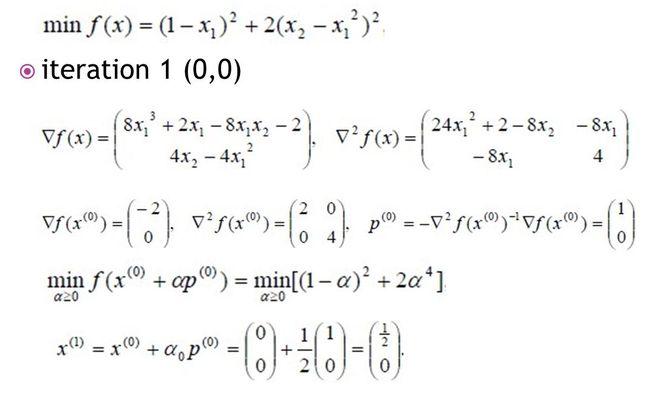

这样的牛顿法是总体收敛的。
1.3.2.2缺点
牛顿法面临的主要困难是Hesse矩阵 不正定。这时候二次模型不一定有极小点,甚至没有平稳点。当 不正定时,二次模型函数是无界的。为了克服这种困难,有多种方法,常用的方法是使牛顿方向偏向最速下降方向 。具体做法是将Hesse矩阵 改变成 ,其中 ,使得 正定。 一般希望是比较小,最好是刚刚好能使 正定。
1.3.3拟牛顿法
牛顿法在实际应用中需要存储二阶导数信息和计算一个矩阵的逆,这对计算机的时间和空间要求都比较高,也容易遇到不正定的Hesse矩阵和病态的Hesse矩阵,导致求出来的逆很古怪,从而算法会沿一个不理想的方向去迭代。
有人提出了介于最速下降法与牛顿法之间的方法。一类是共轭方向法,典型的是共轭梯度法,还有拟牛顿法。
其中拟牛顿法简单实用,这里就特地介绍,其他方法感兴趣的读者可以去看相关资料。
1.3.3.1算法思想和步骤
牛顿法的成功的关键是利用了Hesse矩阵提供的曲率信息。但是计算Hesse矩阵工作量大,并且有些目标函数的Hesse矩阵很难计算,甚至不好求出,这就使得仅利用目标函数的一阶导数的方法更受欢迎。拟牛顿法就是利用目标函数值f和一阶导数g(梯度)的信息,构造出目标函数的曲率近似,而不需要明显形成Hesse矩阵,同时具有收敛速度快的特点。设 在开集 上二次可微,f在 附近的二次近似为

两边求导,得
令,得
其中,是梯度。那么,只要构造出Hesse矩阵的逆近似满足这种上式就可以,即满足关系
这个关系就是拟牛顿条件或拟牛顿方程。
拟牛顿法的思想就是——用一个矩阵去近似Hesse矩阵的逆矩阵,这样就避免了计算矩阵的逆。
当然需要满足一些条件:
(a) 是一个正定的矩阵
(b) 如果存在,则。
(c) 初始正定矩阵取定后,应该由递推给出,即;其中是修正矩阵,是修正公式。
常用而且有效的修正公式是BFGS公式,如下

下面给出BFGS公式下的拟牛顿法

在上述步骤中,初始正定矩阵通常取为单位矩阵,即。这样,拟牛顿法的第一次迭代相当于一个最速下降迭代。
1.3.3.2优缺点
与牛顿法相比,有两个优点:
(a) 仅需一阶导数
(b) 校正保持正定性,因而下降性质成立
(c) 无需计算逆矩阵,但具有超线性收敛速度
(d) 每次迭代仅需要次乘法计算
缺点是初始点距离最优解远时速度还是慢。
解决方法是,迭代前期用最速下降法进行迭代,得到一定解以后用拟牛顿法迭代。
致谢
Deep Learning高质量交流群里的多位同学@ ParadiseLost,@一路走来 等等,那个MathType太好用了。
参考文献
【1】最优化理论与方法。袁亚湘,孙文瑜