nutch
Nutch是一个刚刚诞生开放源代码(open-source)的web搜索引擎。
尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步演变成为一个公司垄断了几乎所有的web搜索为其谋取商业利益.这显然不利于广大Internet用户.
Nutch为我们提供了这样一个不同的选择. 相对于那些商用的搜索引擎, Nutch作为开放源代码搜索引擎将会更加透明, 从而更值得大家信赖. 现在所有主要的搜索引擎都采用私有的排序算法, 而不会解释为什么一个网页会排在一个特定的位置. 除此之外, 有的搜索引擎依照网站所付的费用, 而不是根据它们本身的价值进行排序. 与它们不同, Nucth没有什么需要隐瞒, 也没有动机去扭曲搜索的结果. Nutch将尽自己最大的努力为用户提供最好的搜索结果.
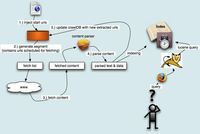
Nutch主要分为两个部分
爬虫crawler和查询searcher。Crawler主要用于从网络上抓取网页并为这些网页建立索引。Searcher主要利用这些索引检索用户的查找关键词来产生查找结果。两者之间的接口是索引,所以除去索引部分,两者之间的耦合度很低。
Crawler和Searcher两部分尽量分开的目的主要是为了使两部分可以分布式配置在硬件平台上,例如将Crawler和Searcher分别放在两个主机上,这样可以提升性能。
爬虫,Crawler
Crawler的重点在两个方面,Crawler的工作流程和涉及的数据文件的格式和含义。数据文件主要包括三类,分别是web database,一系列的segment加上index,三者的物理文件分别存储在爬行结果目录下的db目录下webdb子文件夹内,segments文件夹和index文件夹。那么三者分别存储的信息是什么呢?
Web database,也叫WebDB,其中存储的是爬虫所抓取网页之间的链接结构信息,它只在爬虫Crawler工作中使用而和Searcher的工作没有任何关系。WebDB内存储了两种实体的信息:page和link。Page实体通过描述网络上一个网页的特征信息来表征一个实际的网页,因为网页有很多个需要描述,WebDB中通过网页的URL和网页内容的MD5两种索引方法对这些网页实体进行了索引。Page实体描述的网页特征主要包括网页内的link数目,抓取此网页的时间等相关抓取信息,对此网页的重要度评分等。同样的,Link实体描述的是两个page实体之间的链接关系。WebDB构成了一个所抓取网页的链接结构图,这个图中Page实体是图的结点,而Link实体则代表图的边。
一次爬行会产生很多个segment,每个segment内存储的是爬虫Crawler在单独一次抓取循环中抓到的网页以及这些网页的索引。Crawler爬行时会根据WebDB中的link关系按照一定的爬行策略生成每次抓取循环所需的fetchlist,然后Fetcher通过fetchlist中的URLs抓取这些网页并索引,然后将其存入segment。Segment是有时限的,当这些网页被Crawler重新抓取后,先前抓取产生的segment就作废了。在存储中。Segment文件夹是以产生时间命名的,方便我们删除作废的segments以节省存储空间。
Index是Crawler抓取的所有网页的索引,它是通过对所有单个segment中的索引进行合并处理所得的。Nutch利用Lucene技术进行索引,所以Lucene中对索引进行操作的接口对Nutch中的index同样有效。但是需要注意的是,Lucene中的segment和Nutch中的不同,Lucene中的segment是索引index的一部分,但是Nutch中的segment只是WebDB中各个部分网页的内容和索引,最后通过其生成的index跟这些segment已经毫无关系了。